Python提取PDF发票信息保存Excel文件并制作EXE程序的全过程
PromiseTo 人气:0前言
通过本篇文章可学习pdf发票信息的提取,内容保存至Excel,了解命令图像工具Gooey,以及如何将python文件打包为exe程序
背景
现在电子发票越来越普遍,各公司开票形式已基本无纸化。目前所在公司的情况是,每个人自己报账,需要将发票信息(发票号/金额)填如K3系统进行流程申请,另外将电子发票打印为纸质并贴票后找领导签字及审批K3的流程;之后在将纸质单据送至财务审批。如果财务发现数据填写不正确,就会将流程和单据打回来,又要重新找领导签字审批,相当麻烦。
分析
为了减少报账被打回来的情况,我们先分析,整个报账过程中,存在的问题
下载回来的发票文件命名不规范不容易识别
如:04500160011131347550.pdf
填K3时需要复制发票号和金额,还要选择发票类型
每次要打开pdf发票复制发票号和金额
发票可能存在错误情况:如公司名称或纳税人识别号不正确
每次还要检查一下
优化
一开始的想法是,做一个程序,识别发票信息并提供复制按钮,方便复制到k3。自动检查发票信息是否完整正确,公司名称和纳税人识别号是否正确,如不正确则提示错误,另外自动将文件重名称,及一键打印功能。
不过由于对Python的GUI还不大熟悉,就改了方式:将发票信息提取至Excel,在自己到Excel上复制信息和检查发票是否完整,另外将文件重命名为开票公司+金额的形式
最终效果
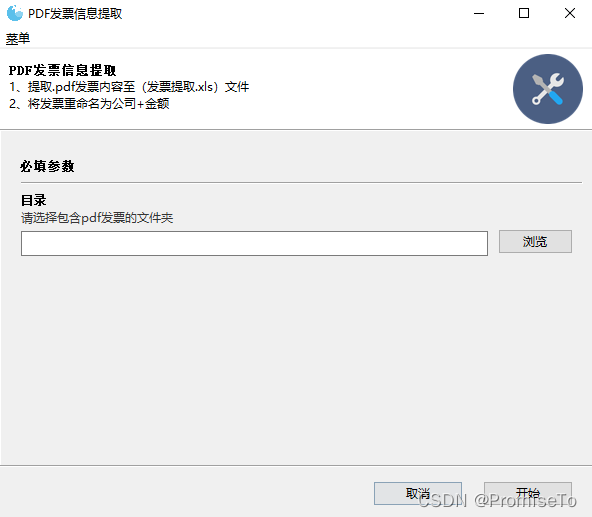
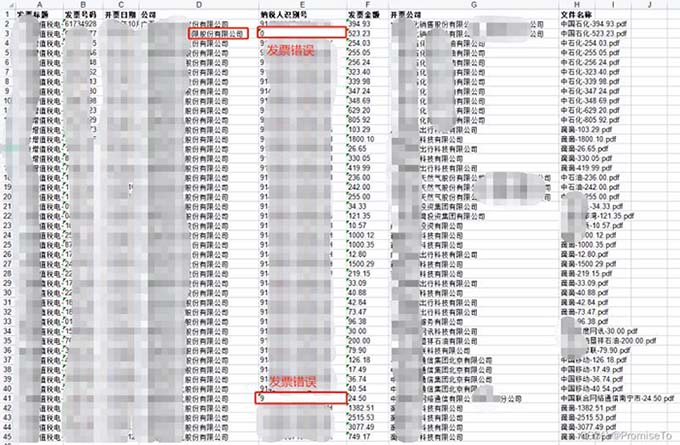
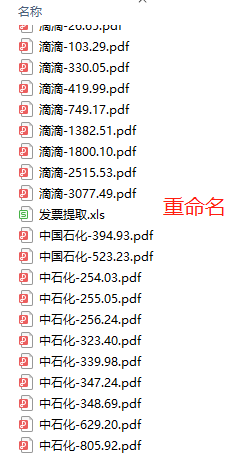
实现
读取pdf发票
使用pdfplumber,安装命令pip install pdfplumber,
import pdfplumber
import re
import os
def re_text(bt, text):
m1 = re.search(bt, text)
if m1 is not None:
return re_block(m1[0])
def re_block(text):
return text.replace(' ', '').replace(' ', '').replace(')', '').replace(')', '').replace(':', ':')
def get_pdf(dir_path):
pdf_file = []
for root, sub_dirs, file_names in os.walk(dir_path):
for name in file_names:
if name.endswith('.pdf'):
filepath = os.path.join(root, name)
pdf_file.append(filepath)
return pdf_file
def read():
filenames = get_pdf('C:\Users\Administrator\Desktop\a') # 修改为自己的文件目录
for filename in filenames:
print(filename)
with pdfplumber.open(filename) as pdf:
first_page = pdf.pages[0]
pdf_text = first_page.extract_text()
if '发票' not in pdf_text:
continue
# print(pdf_text)
print('--------------------------------------------------------')
print(re_text(re.compile(r'[\u4e00-\u9fa5]+电子普通发票.*?'), pdf_text))
t2 = re_text(re.compile(r'[\u4e00-\u9fa5]+专用发票.*?'), pdf_text)
if t2:
print(t2)
# print(re_text(re.compile(r'发票代码(.*\d+)'), pdf_text))
print(re_text(re.compile(r'发票号码(.*\d+)'), pdf_text))
print(re_text(re.compile(r'开票日期(.*)'), pdf_text))
print(re_text(re.compile(r'名\s*称\s*[::]\s*([\u4e00-\u9fa5]+)'), pdf_text))
print(re_text(re.compile(r'纳税人识别号\s*[::]\s*([a-zA-Z0-9]+)'), pdf_text))
price = re_text(re.compile(r'小写.*(.*[0-9.]+)'), pdf_text)
print(price)
company = re.findall(re.compile(r'名.*称\s*[::]\s*([\u4e00-\u9fa5]+)'), pdf_text)
if company:
print(re_block(company[len(company)-1]))
print('--------------------------------------------------------')
read()通过上述代码可以实现对pdf发票的内容识别和输出功能,完整的功能请通过学习本文后续的内容自主实现。
写入Excel
使用xlwt写Excel文件,安装命令pip install xlwt,一个简单的例子如下
import xlwt
# 创建工作簿
wb = xlwt.Workbook()
# 创建表单
sh = wb.add_sheet('sheet 1')
# 写入数据
sh.write(0, 1, '姓名')
# 保存
wb.save('test.xls')创建图像界面
使用Gooey创建GUI图像界面,安装命令pip install Gooey
官网地址:https://github.com/chriskiehl/Gooey 目前是:15.4k stars
这里对Gooey的适用情况做一个说明,Gooey适用于命令行的图形工具,也就是只做输入(有各种输入/选择框)和输出的情况,不适用于做界面展示,无法添加自定义按钮,如button等。使用print就能将输出内容显示到GUI图形界面上
一个简单的例子
from gooey import Gooey, GooeyParser
@Gooey(program_name="简单的实例")
def main():
parser = GooeyParser(description="第一个示例!")
parser.add_argument('文件路径', widget="FileChooser") # 文件选择框
parser.add_argument('日期', widget="DateChooser") # 日期选择框
args = parser.parse_args() # 接收界面传递的参数
print(args)
if__name__ == '__main__':
main()
打包为exe文件
使用pyinstaller将代码打包为exe文件
安装命令pip install pyinstaller
打包命令pyinstaller -F xxxxx.py -w (xxxxx.py改为具体的.py文件名)
等待打包完成,在代码目录的会生成dist文件夹,打开后可以看到exe程序

注意:程序有中文输出的请查看该文章,避免打包后程序无法正常运行,参考如下
附:解决Gooey在打包成exe文件后打印中文报UnicodeDecodeError: 'utf-8' codec can't decode
问题
在使用Gooey这个工具生成GUI的时候,没有打包前测试是好的,但是当打包成exe文件后,双击exe运行填入所需选项执行报UnicodeDecodeError: 'utf-8' codec can't decode的错误。
PS C:\Users\faces\Desktop\gooey demo\dist> .\auto.exe
Exception in thread Thread-1:
Traceback (most recent call last):
File "threading.py", line 926, in _bootstrap_inner
File "threading.py", line 870, in run
File "site-packages\gooey\gui\processor.py", line 71, in _forward_stdout
File "site-packages\gooey\gui\processor.py", line 84, in _extract_progress
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb5 in position 13: invalid start byte
通过查找github中提交的issue发现是打包后环境的encoding与打包时的encoding不一致导致的问题。
解决方案
在Gooey装饰器中加入关键字参数encoding='cp936'
from gooey import Gooey, GooeyParser
@Gooey(encoding='cp936')
def main():
parser = GooeyParser(description="Export music lite")
parser.add_argument('exe文件', widget="FileChooser")
parser.add_argument('flac文件夹', widget="DirChooser")
parser.add_argument('MP3导出文件夹', widget="DirChooser")
args = parser.parse_args()
print(args)
if __name__ == "__main__":
main()
问题
接下来我想更改Gooey生成的GUI页面为中文,那么代码改为
from gooey import Gooey, GooeyParser
@Gooey(encoding='cp936', language='chinese')
def main():
parser = GooeyParser(description="Export music lite")
...
这时候执行会报如下错误
PS C:\Users\faces\Desktop\gooey demo\dist> .\auto.exe
Traceback (most recent call last):
File "auto.py", line 17, in <module>
File "site-packages\gooey-1.0.3-py3.7.egg\gooey\python_bindings\gooey_decorator.py", line 87, in inner2
File "auto.py", line 12, in main
File "site-packages\gooey-1.0.3-py3.7.egg\gooey\python_bindings\gooey_parser.py", line 114, in parse_args
File "site-packages\gooey-1.0.3-py3.7.egg\gooey\python_bindings\gooey_decorator.py", line 82, in run_gooey
File "site-packages\gooey-1.0.3-py3.7.egg\gooey\gui\application.py", line 21, in run
File "site-packages\gooey-1.0.3-py3.7.egg\gooey\gui\application.py", line 28, in build_app
File "site-packages\gooey-1.0.3-py3.7.egg\gooey\gui\lang\i18n.py", line 24, in load
File "json\__init__.py", line 293, in load
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 20: illegal multibyte sequence
解决方案
从报错信息中可以看到是因为load代码的时候使用encoding='cp936'去加载文件导致的错误,那么简单粗暴的方法是编辑site-packages\gooey-1.0.3-py3.7.egg\gooey\gui\lang\i18n.py这个文件
找到
with io.open(os.path.join(language_dir, json_file), 'r', encoding=encoding) as f:
_DICTIONARY = json.load(f)
修改为
with io.open(os.path.join(language_dir, json_file), 'r', encoding='utf-8') as f:
_DICTIONARY = json.load(f)
总结
加载全部内容