Java Http多次请求复用同一连接示例详解
颜如玉 人气:0概述
注:
- 本文乃是最简单的实现,真实场景要复杂麻烦的多
- 旨在阐述清晰多次HTTP请求复用一个连接的底层逻辑
早在HTTP/1.0时代,每次HTTP请求都要创建一个连接,而创建连接的过程需要消耗资源和时间,代价相对昂贵,为了减少资源消耗,缩短响应时间,就需要重用连接。在后来的HTTP/1.1中,引入了连接复用的机制,Http Header中加入Connection: keep-alive来告诉对方这个请求响应完成后先不忙关闭,这也是本篇文章的由来。
复用的基本条件
理论基础
OSI是Open System Interconnection的缩写,意为开放式系统互联。国际标准化组织(ISO)制定了OSI模型,该模型定义了不同计算机互联的标准,是设计和描述计算机网络通信的基本框架。也就是如下七层模型:
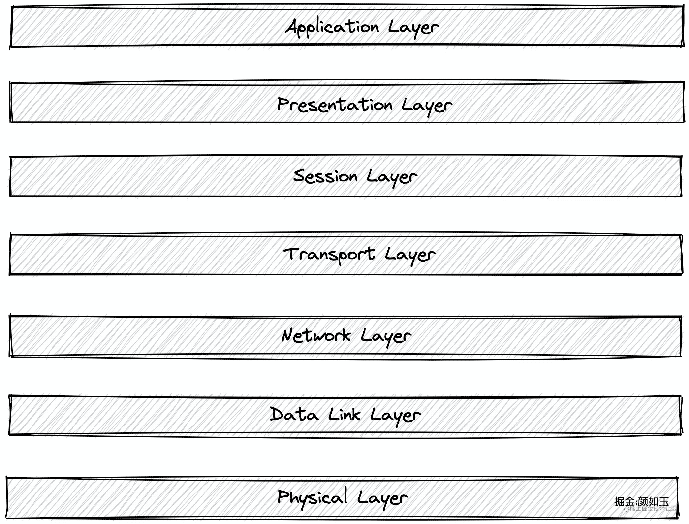
当然也有大家熟知的五层模型,也就是把会话层、表示层、应用层合称为应用层。耳熟能详的TCP、UDP属于数量稀少的传输层协议。在这之上的应用层协议百花齐放诸如:HTTP、SMTR、FTP......,然后很多中间件也自定义了通讯协议,比如Dubbo、Mysql。
读到这里大家可能就已经清醒的意识到,即使同属应用层的协议,是否支持长连接也不尽相同。笔者想要传达的一个认知:之所以能支持长连接,那是因为TCP经历三次握手建立连接之后,如果不出现其他意外是可以保证连接状态的。也就是说应用层协议是否属于长连接仅仅取决于成功建立TCP,发送一个请求之后,对该连接的处理策略:
- 如早期的HTTP每次发送请求,Server端回复完毕之后直接关闭则是短连接
- 如Mysql处理完一条SQL请求,然后继续执行下一个则是长连接
这其实就是我们的理论基础,HTTP有希望支持长连接的前提是TCP本身就是长连接。
现实基础
HTTP协议并非魔法,不是说新增一条规范,也不是简简单单的Header中加入Connection: keep-alive就能立马支持长连接了。想要达到这个目的需要Client、Server端共同努力。
客户端譬如Chrome浏览器,服务端譬如阿里OSS,像这样两端都支持了新的规范,HTTP才能快乐的成为长连接阵营中的一员。
获取HTTP资源常见方式
因为JDK提供了相关工具、且平台相关的第三方包也足够优秀,所以Java获取HTTP资源并非难事。
@Slf4j
public class SinaPicDownload {
/* 微博上某个画师的作品 */
static final String HTTP_URL = "https://wx3.sinaimg.cn/mw2000/006jQ3i8ly1h5k50zujydj35k0334kjo.jpg";
/* 下载之后放在颜如玉电脑的io文件下 */
static final String LOCAL = "/Users/admin/io/灵魂莲华-皎月.jpeg";
public static void main(String[] args) {
try (
InputStream in = new URL(HTTP_URL).openStream();
FileOutputStream out = new FileOutputStream(LOCAL)
) {
byte[] buffer = new byte[1024 << 2];
int read;
while ((read = in.read(buffer)) > -1) {
out.write(buffer, 0, read);
}
out.flush();
}
catch (Throwable e) {
log.error("获取HTTP资源失败:", e);
}
}
}
配合Java 7之后提供的try-with-resources语法糖,你甚至仅仅只需要不到二十行的代码就可以轻而易举的达到目的,但是缺点也显而易见,通过这种方法每次只能获取一个资源,用完之后只能完毕。我当时就在想,Java怎么实现一次连接多次请求呢?
Transfer-Encoding
笔者在上文提到的理论基础上推测到肯定可以使用Java提供的Socket建立TCP连接,关键问题是怎么跟Server端描述HTTP请求呢?
类比到现实生活中,两者能顺畅交流必然要求双方都可以听懂对方的语言。那HTTP有没有一种Client、Server都能解析的规范呢,HTTP Transfer-Encoding正是在这种背景下应运而生。通俗的来讲Transfer-Encoding就是一种双方都约定好的格式,我按照这个格式Encoding,你按照这个格式Decoding,ta大概长这个样子:
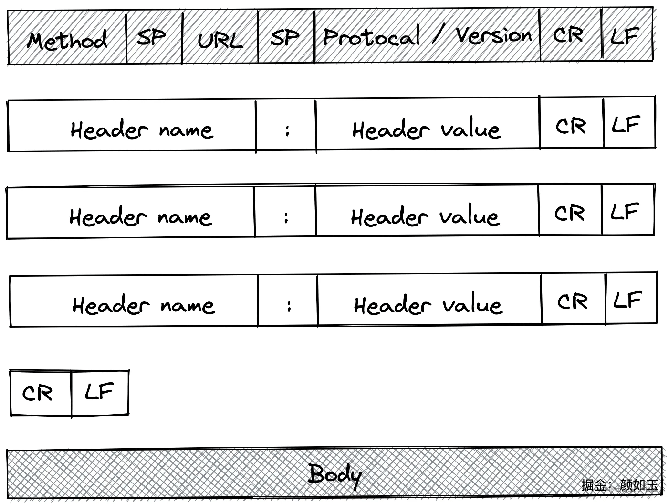
可想而知刚刚获取那张图片资源的是时候,我们肯定是这么跟新浪微博服务端说的:
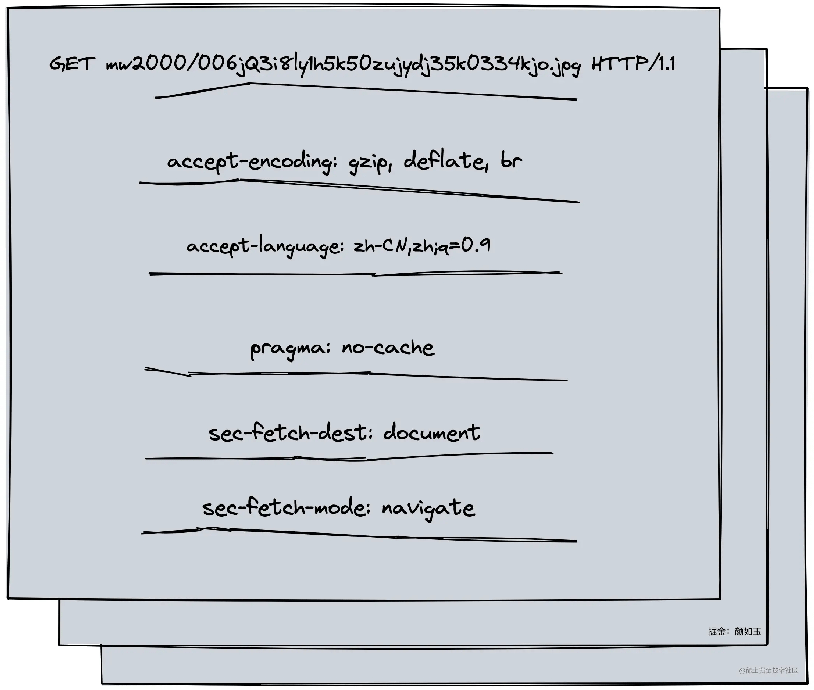
声明:
- 真实的Request Line与图中一致
- Header其实复杂很多,配图做了简化
- 该请求Body为空,图中略过
简略实现
先声明一些常量,以备后用
@Slf4j
public class ReusableHttp {
/* 颜如玉公司的OSS服务域名 */
static final String HOST = "****.oss-cn-zhangjiakou.aliyuncs.com";
static final int PORT = 80;
/* 颜如玉在OSS上放置的几个资源 */
static final String[] URLS = new String[]{
"/context/reusable/gtyj.text",
"/context/reusable/tlyxqch.text",
"/context/reusable/yj.text",
"/context/reusable/ls.text"
};
/* CR = '\r'; LF = '\n'*/
static final byte[] CRLF = new byte[]{Chars.CR, Chars.LF};
static final String LOCAL_PATH = "/Users/admin/io/";
}
建立TCP连接,然后获得输出,输入流
public static void main(String[] args) {
try {
try (
Socket socket = new Socket(HOST, PORT);
OutputStream out = socket.getOutputStream();
InputStream in = socket.getInputStream()
) {
/* 复用连接,获取资源 */
reusable(out, in);
}
}
catch (IOException e) {
log.error("请求出现异常", e);
}
}
写出Request Line
/**
* Write Request Line
*
* RequestLine encoding规范
*
* **********************************************
* * method * sp * URL * sp * version * cr * lf *
* **********************************************
*/
static void writeRequestLine(OutputStream out, String url) throws IOException {
/* 注意空格一定要按照规定来摆放 */
out.write(("GET " + url + " HTTP/1.1").getBytes());
/* 最后再写入一个回车、换行符表示Request Line结束 */
out.write(CRLF);
}
写出Request Header
/**
* Write Request Header
*
* HeaderLine encoding规范
*
* *******************************************
* * header field name * : * value * cr * lf *
* *******************************************
* ....
* *******************************************
* * header field name * : * value * cr * lf *
* *******************************************
* ...
* ***********
* * cr * lf *
* ***********
* ***************
* * Entity Body *
* ***************
*/
static void writeHeaderLine(OutputStream out) throws IOException {
out.write("Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9".getBytes());
out.write(CRLF);
out.write("Accept-Encoding: gzip, deflate".getBytes());
out.write(CRLF);
out.write("Accept-Language: zh-CN,zh;q=0.9".getBytes());
out.write(CRLF);
out.write("Connection: keep-alive".getBytes());
out.write(CRLF);
out.write("Host: kuaimai-sheji.oss-cn-zhangjiakou.aliyuncs.com".getBytes());
out.write(CRLF);
/* 最后再写入一个回车、换行符表示Request Header结束 */
out.write(CRLF);
}
因为是简单的请求,所以直接省略Request Body。发出如上报文后,Server端会解析请求,然后回复。
/**
* 1.向Server端写出请求
* 2.接受Server端回复
* 3.写到颜如玉本地机器的io文件夹下
*
* @param out 往Server端写出流
* @param in Server端往Client端写入流
*/
static void reusable(OutputStream out, InputStream in) throws IOException {
for (int i = 0, s = URLS.length; i < s; i++) {
writeRequestLine(out, URLS[i]);
writeHeaderLine(out);
out.flush();
byte[] bytes = new byte[512];
in.read(bytes);
String file = LOCAL_PATH + i + ".text";
try (
FileOutputStream fo = new FileOutputStream(file)
) {
fo.write(bytes);
fo.flush();
}
catch (Throwable e) {
log.error("文件写入出现异常", e);
}
}
}
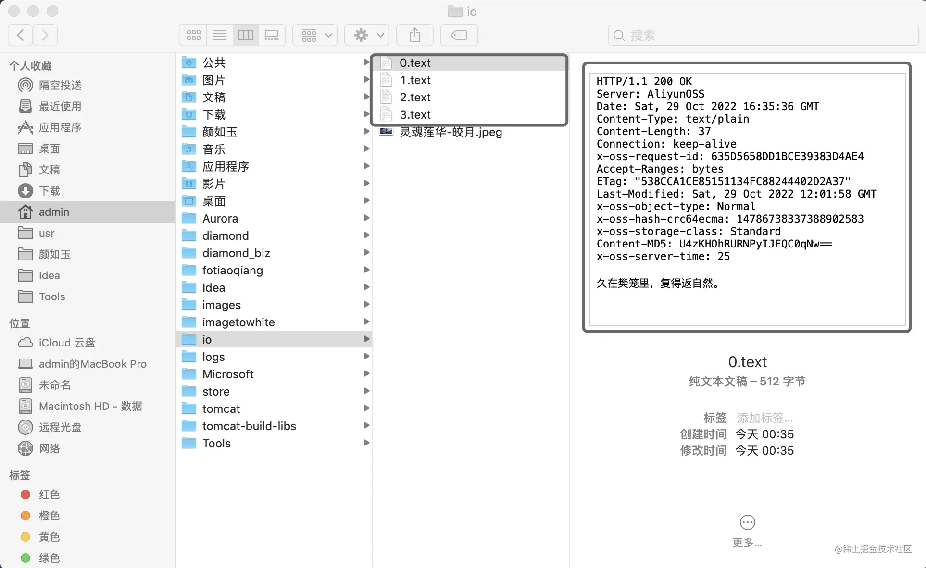
可以看到功能已经实现,同一连接我反复请求了四次,最终得到四个资源。
加载全部内容