Python如何拆分ZIP文件
陈年椰子 人气:0Python拆分ZIP文件
同事接到个任务,每周拆分下发zip文件。
文件样子如下

目录下有很多文件,要按网点下发。这个总不能每次都手工做吧。 python 脚本搞起!
需要 2个库
import os import zipfile
先解压到临时目录,再遍历压缩成新zip文件。注意中文字符问题。
上代码
# encoding: utf-8
"""
@author: 陈年椰子
@contact: hndm@qq.com
@version: 1.0
@project:MyTools
@file: zip_work.py
@time: 2021-9-13 15:48
说明
"""
import os
import zipfile
def dfs_get_zip_file(input_path,result):
# 遍历目录列表
files = os.listdir(input_path)
for file in files:
if os.path.isdir(input_path+'/'+file):
dfs_get_zip_file(input_path+'/'+file,result)
else:
result.append(input_path+'/'+file)
def zip_path(input_path,output_path,output_name,up_path=""):
# input_path 要压缩的目录
# output_path zip文件存放目录
# output_name zip文件名
# up_path zip包需要剔除的父目录,避免压缩包内目录过深
f = zipfile.ZipFile(output_path+'/'+output_name,'w',zipfile.ZIP_DEFLATED)
filelists = []
dfs_get_zip_file(input_path,filelists)
for file in filelists:
f.write(file,file.replace(up_path,''))
f.close()
return output_path+r"/"+output_name
def get_category_dir_zip(filepath, ext_dir, up_path = ""):
#遍历filepath下所有文件,包括子目录 , 找到网点目录,压缩成zip文件
# 按需要修改压缩逻辑 , 我这里是按网点机构分别压缩
cate_dict = {'469030':'21',
'469035':'23',
'469031':'24',
'469027':'19',
'469003':'13',
'469025':'17',
'469007':'16',
'460101':'11',
'469033':'25',
'469028':'26',
'469034':'27',
'469002':'14',
'469036':'28',
'460201':'12',
'469026':'22',
'469006':'20',
'469005':'18',
'469001':'15',
}
files = os.listdir(filepath)
if os.path.isdir(ext_dir):
pass
else:
os.mkdir(ext_dir)
for fi in files:
fi_d = os.path.join(filepath,fi)
if os.path.isdir(fi_d):
if fi.find("46")==0:
zip_file_cnt = 0
ctg_dir_list = os.listdir(filepath)
for ci in ctg_dir_list:
ctg_dir = os.path.join(filepath, ci)
if os.path.isdir(ctg_dir):
zip_file = "{}.zip".format(ci[:6])
zip_file_dir = os.path.join(ext_dir, zip_file)
if os.path.exists(zip_file_dir): # 如果文件存在 删除文件
os.remove(zip_file_dir)
print('压缩', ctg_dir, zip_file_dir, ext_dir)
zip_path(ctg_dir, ext_dir, zip_file, up_path)
zip_file_cnt = zip_file_cnt + 1
return zip_file_cnt
else:
return get_category_dir_zip(fi_d, ext_dir)
def sfp_unzip(file_path, ext_dir):
"""unzip zip file"""
zip_file = zipfile.ZipFile(file_path)
if os.path.isdir(ext_dir):
pass
else:
os.mkdir(ext_dir)
zip_i = 0
for names in zip_file.namelist():
zip_i = zip_i + 1
# 避免中文出现乱码
gbk_names = names.encode('cp437').decode('gbk')
file_size = zip_file.getinfo(names).file_size
new_path = os.path.join(ext_dir, gbk_names)
# 判断文件是文件夹还是文件
if file_size > 0:
# 是文件,通过open创建文件,写入数据
with open(file=new_path, mode='wb') as f:
# zf.read 是读取压缩包里的文件内容
f.write(zip_file.read(names))
else:
# 是文件夹,就创建
os.mkdir(new_path)
zip_file.close()
return zip_i
if __name__=="__main__":
# 解压文件
file_cnt = sfp_unzip("zip/xyk.zip", "D:/zip/tmp")
if file_cnt > 0:
# 按网点压缩打包文件
zip_file_cnt = get_category_dir_zip("D:/zip/tmp", "D:/zip/data")
print("拆分建立{}个zip文件。".format(zip_file_cnt))
else:
print("zip文件为空,未拆分建立zip文件。")Python ZIP 装包 拆包
装包
zip函数可以将两个列表“缝合起来”,比如:
a=[1,2,3] b=['x','y','z'] c=list(zip(a,b)) print(c)
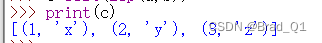
这里的含义是a里面的第一个元素跟b里面的第一个元素配对,放到一个元组里面;a里面的第二个元素跟b里面的第二个元素配对,放到另外一个元组里面;以此类推。
现在,另外在a里面增加一个元素,再使用zip的结果会怎么样呢?
a.append(4) c=list(zip(a,b)) print(c)

从上面截图可以看出,列表是作为参数被传入zip函数中,而zip函数在遍历列表(或者其他的可迭代数据类型 Iterable data type)时,遍历到最短的那个列表后,遍历结束。
在上面a和b的例子中,b列表长度是3,a列表长度是4,所以最终产生的列表c的长度也只有3。
拆包
拆包是装包的方向操作
d=list(zip(*c)) print(d)
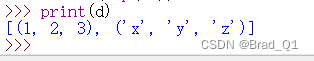
上述拆包的核心是在zip(*c)里面,这里不是太好理解。从结果来看,是产生了两个元组,d和e。其分别的内容和a及b这两个列表元素一样。
这里重点看下*c,不太好理解。其实可以打印出来:
print(*c)

从上图可以看出 *c是把c列表里面的三个参数分别拆了出来,然后作为参数传入了zip函数里面。可以做另一个试验验证一下。
p1=(1,'x') p2=(2,'y') p3=(3,'z') p=list(zip(p1,p2,p3)) p==d
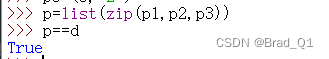
从上面的验证可以看出拆包时候的*c,其实就c列表里面三个作为元组的元素分别传入zip函数中。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容