阿里妈妈淘宝联盟宝贝采集方法
人气:0本文介绍使用采集器采集阿里妈妈淘宝联盟(以衣服为例)的方法
本文仅以阿里妈妈淘宝联盟衣服搜索结果页面举例说明,大家如果有其他采集淘宝联盟商品的需求,可以更换搜索关键词进行采集。
采集内容为:
商品图片地址,商品标题,店铺名,销量,商品价格,佣金,比率,商品链接

操作方法
- 01
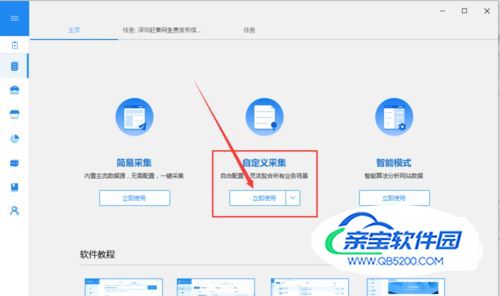
步骤1:创建采集任务1)进入主界面,选择“自定义采集”
- 02
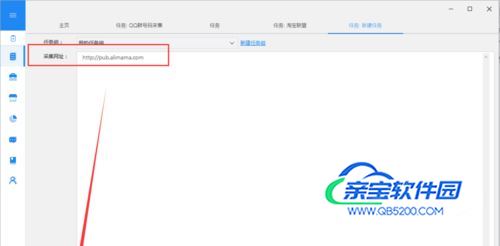
2)将要采集的网站URL复制粘贴到输入框中,点击“保存网址”
- 03
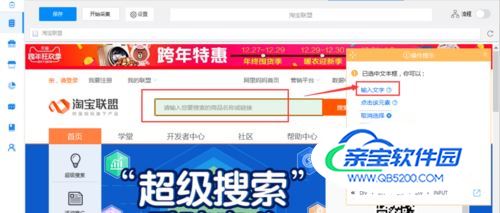
3)保存网址后,鼠标点击输入框,在右侧操作提示框中,选择“输入文字”
- 04
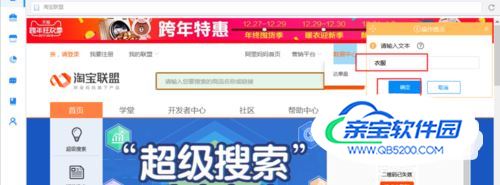
4)然后输入采集的商品,点击确定
- 05
5) 网络加载速度比较慢,所以需要设置执行前等待,为防止输入框没加载完毕操作失效还需要设置出现元素。
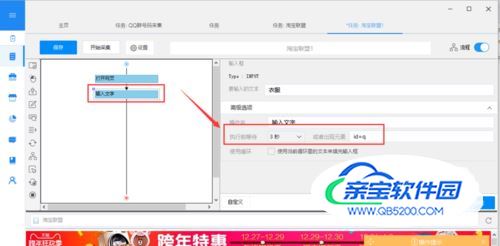
- 06
然后点击搜索,并选择“点击该按钮”
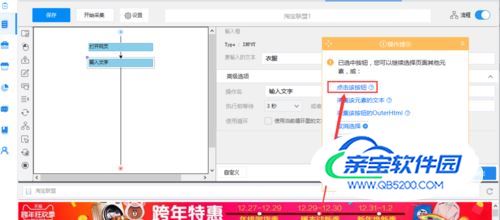
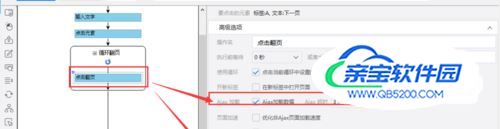
- 07
由于网页涉及Ajax技术。所以需要选中点击元素,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“5秒”。 因为页面打开后需要向下滑动才可以出现更多内容,所以还需要设置页面滚动,滚动次数选择30次,每次间隔2秒,选择向下滚动一屏完成后,点击“确定”。
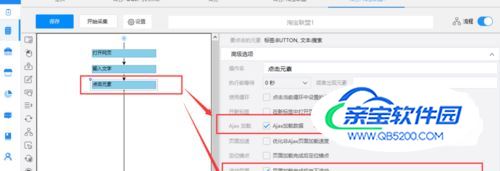
- 08
步骤2:创建翻页循环1)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接”
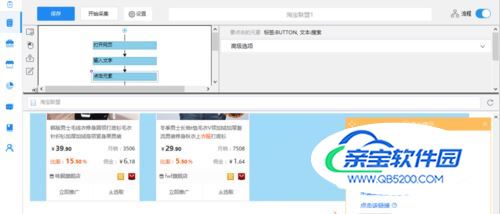
- 09
2)同上,此步骤也需要设置高级选项,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“3秒”。 因为页面打开后需要向下滑动才可以出现更多内容,所以还需要设置页面滚动,滚动次数选择30次,每次间隔1秒,选择向下滚动一屏完成后,点击“确定”
- 10
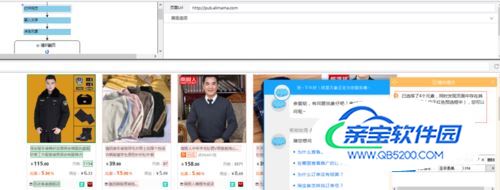
步骤3:采集阿里妈妈淘宝联盟商品信息1)移动鼠标,选中第一个商品图片,标题,店铺名,系统会自动识别出相似的元素,在提示框中选择“选中全部”,随后点击采集图片地址或者采集以下元素文本。
- 11
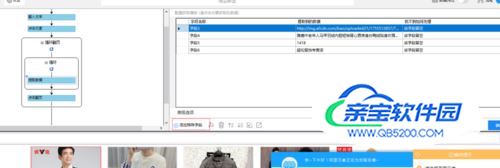
2)如果要采集商品链接,价格,佣金,比率,销量的话,则要写xpath才能实现采集。以采集价格字段举例:首先选择添加特殊字段
- 12
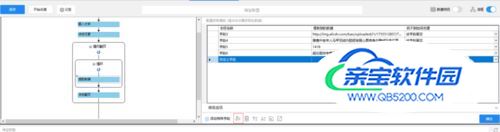
然后选中该字段,选择自定义数据字段(下图红色框中的)
- 13
随后选择自定义定位元素方式,并按下图填入XPah。价格的元素匹配的XPath为//div[1]//div[@class="content-line clearfix mt5"]/span[1]相对Xpath勾上,并填入//div[@class="content-line clearfix mt5"]/span[1]需要注意的事,Xpath会随着网站结构的改变而改变,所以上面xpath不能确保一直有效。如果要采集这些数据,建议学习一下Xpath:
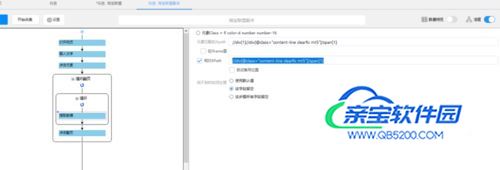
- 14
填好xpath之后,随后在自定义数据字段->自定义抓取方式中选择抓取文本即可。
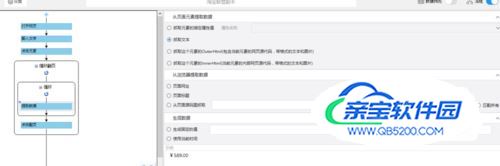
- 15
同理,如果要采集佣金,比率,商品链接分别设置为:佣金:元素匹配的XPath为//div[1]//div[@class="content-line clearfix"]/span[2]相对Xpath勾上,并填入//div[@class="content-line clearfix"]/span[2]自定义数据字段->自定义抓取方式中选择抓取文本商品链接:元素匹配的XPath为//div/a[@class="search-box-img img-loaded"]相对Xpath勾上,并填入//div/a[@class="search-box-img img-loaded"]自定义数据字段->自定义抓取方式中选择抓取超链接(a标签的href)比率:元素匹配的XPath为//div[1]//div[@class="content-line clearfix"]/span[1]相对Xpath勾上,并填入//div[@class="content-line clearfix"]/span[1]自定义数据字段->自定义抓取方式中选择抓取文本销量:元素匹配的XPath为//div[1]//div[@class="content-line clearfix mt5"]/span[2]相对Xpath勾上,并填入//div[1]//div[@class="content-line clearfix mt5"]/span[2]自定义数据字段->自定义抓取方式中选择抓取文本设置完成以后,可以看到数据都在字段中了:
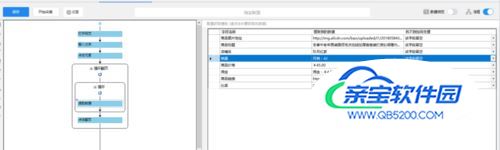
- 16
3)然后再选择‘’启动本地采集”
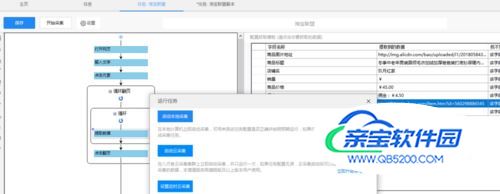
- 17
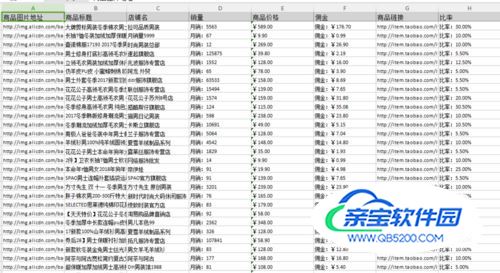
步骤4:数据采集及导出1)采集完成后,会跳出提示,选择“导出数据”选择“合适的导出方式”,将采集好的数据导出这里我们选择excel作为导出为格式,一份完好的阿里妈妈淘宝联盟商品信息就导入出来了,数据导出后如下图
加载全部内容