R语言常见报错
酷二的R语言记录册 人气:0前言
与Python、C语言等相比,R语言可以说是比较容易的编程语言之一(更适合数据探索和科研)。尽管R语言相对简单,但仍给新手小白们带来无数的困难和痛苦。特别是,当你在run一份code,发现每行code都出现Error,更是无奈。然而,在刚开始学习R语言的过程中,这些ERROR又不可避免。对我自己而言,刚开始学习R时,也遇到了各式各样的Error,确实让人崩溃。这里,我给大家总结了一些初学者学习代码时容易踩的坑,以及如何copy with,以Rstudio为例。
第一类:工作路径问题
未设定工作路径
如下:Cannot find XX.csx/txt/xlsx等等,这是新手常见的报错–工作路径问题。在出现这类报错时,第一反应检查自己在导入/读取文件前是否设置了工作路径,或者说工作路径设定是否正确。具体理解:也就是说,所要读取或加载的文件必须存在当前设定的路径下才允许。其次,如果我们设定了工作路径,但是发现该存在路径下,并没有存放所需文件也需要更改工作路径。例子,有两种情况需要注意。一是,在读取文件前没有设置工作路径,解决办法:补充该工作路径所在路径,用setwd()设置;二是,设置了工作路径,但是当前工作路径不是该文件所在的工作路径,解决办法:更改工作路径,先用getwd()检查当前的工作路径,再用setwd()进行修改。
## 第一种情况
library(openxlsx)
mydata <- read.xlsx("1.xlsx",1)
#报错信息如下
Error in loadWorkbook(file, password = password) : Cannot find 1.xlsx
#解决办法
setwd ( ) #这是设置所需读取文件的工作路径的函数, 路径记得加双引号或者单引号。
Tips:在读取前文件前用setwd()来设置绝对路径是一种方法,但这样得保证每次所用数据都必须在同一个工作路径才可以,并且得清楚这个路径的名称(这里可以从我的电脑去复制粘贴路径),否则都需要改。然而,通常我们的数据都是根据个人情况分别放在不同的文件夹,即工作路径都不同。因此,每次读取文件前,我在这里推荐大家用这个方法选择工作路径(choose directory)以解决上述问题:

当前路径需要修改
## 第二种情况
setwd (XXXX)
mydata <- read.xlsx("1.xlsx",1)
#报错信息与第一种情况一样
#解决办法
getwd ( ) #这是检查当前工作路径的函数
setwd ( )
选择好后,我们会在console这个界面看到一个路径,如:I:/作业就是我们的当前工作路径。在R里面所有的操作,导入导出文件都会保存在这个路径下。

第二类:对象名或函数名问题
未找到函数名报错
如下:Could not find function "XXX"等等,这个报错是属于程序包没有加载的问题。因此,在使用某个函数时,首先要清楚知道该函数属于哪个程序包里的,并先用library()读取该程序包,然后再运行该函数即可。
mydata <- read.xlsx("1.xlsx",1)
## 报错信息如下
Error in read.xlsx("1.xlsx", 1) : could not find function "read.xlsx"
### 解决办法
library(openxlsx)
mydata <- read.xlsx("1.xlsx",1)mydata <-read.xlsx("1.xlsx",1)
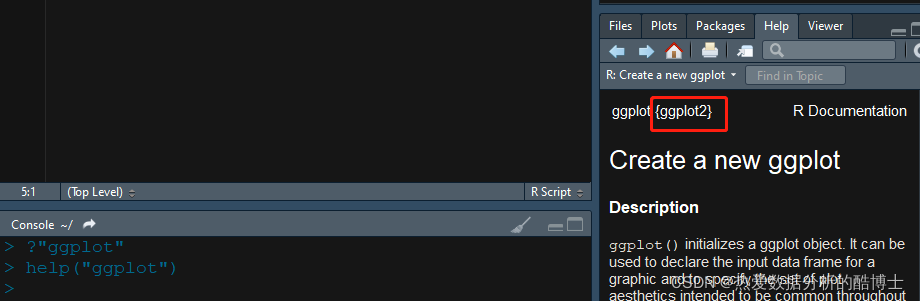
如果不清楚该函数是哪个程序包,我们可以用?“read.xlsx"或 help(“xx”)来咨询,咨询结果如下:红色框即为所需要的程序包,需要注意的是在咨询的时候必要时需加上引号” "。
函数名大小写问题
我们在调用程序R包、函数名时,要注意一个小问题–字母的大小写。这里,我直接用例子给大家展示:head ( )、Head ( )以及HEAD ( )这里只有第一个函数名是能够正常运行的,因为在R语言中只存在自带函数名的字母大小写,也就是说,程序中不会默认都是大写或者都是小写。
## R语言程序包大小写错误
library(Openxlsx)
## 报错信息如下
Error in library("Openxlsx") : there is no package called ‘Openxlsx'
## 更正后
library("openxlsx")
## 函数名大小写错误
mydata <- Read.xlsx("I:\\R language\\R语言郑师兄代码\\图一.xlsx",2)
## 报错信息如下
Error in Read.xlsx("I:\\R language\\R语言郑师兄代码\\图一.xlsx", 2) :
could not find function "Read.xlsx"
## 更正大小写后
mydata <- read.xlsx("I:\\R language\\R语言郑师兄代码\\图一.xlsx",2)
## 另外一个example
Head(mydata)
## 报错信息如下
Error in Head(mydata) : could not find function "Head"
## 更正后
head(mydata)
错误结果和更正展示:

未找到赋值对象
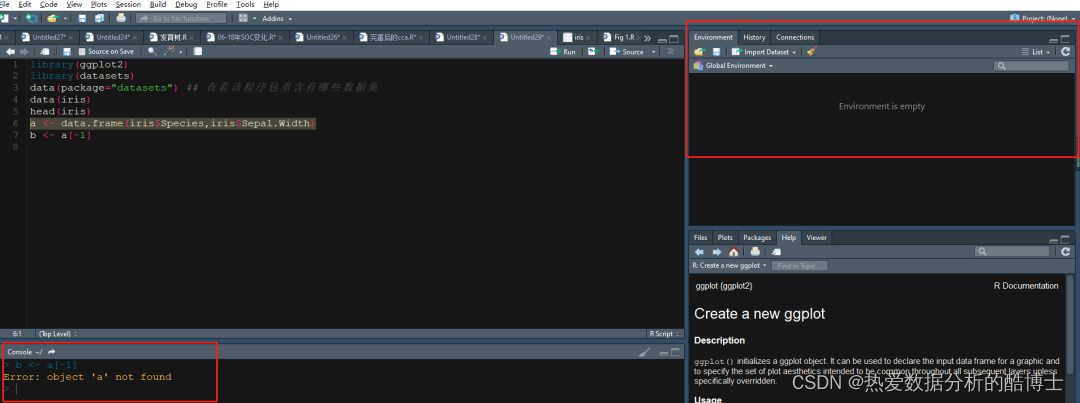
如下:object ‘xxx’ not found,这类报错比较直观,就是如错误所描述的:找不到目标的问题。在下面例子中,就是报错信息中的a找不到。通常可能是你自己在运行代码时候,run 的太快了,上一行的数据读取信息还没读,就紧接着跑下一行代码,所以会出现第二行代码报错,没有找到a这个变量。以后出现这类错误时,只需要查看一下自己环境变量是否缺少该目标变量,如果缺少了补充上就可以了。
## 这类错误检查环境变量中是否存在所需目标 library(ggplot2) library(datasets) data(package="datasets") ## 查看该程序包里含有哪些数据集 data(iris) head(iris) b <- a[-1] ## 报错信息如下 Error: object 'a' not found ## 解决办法 ## 补充目标变量即可 a <- data.frame(iris$Species,iris$Sepal.Width) b <- a[-1]
个人建议:在报错时,先检查下环境变量中的变量,是否能找到所需要的目标。如果没有的话,把目标变量读取后再运行报错的代码即可。
对象赋值不规范
如下:unexpected symbol in “1r”,这类错误也是新手会犯的,但这类错误很简单,我们在定义目标变量的时候,不能用数字作为定义名。这里我提供一个思路去理解,如果可以用数字打头,也需要加上字母:例如1+UUU; 1+AALL。然而这些不能作为变量名,因为编译器不能区分究竟是数字还是变量名。利用数字和字母一起显然没有只用字母来的简便,索性就去掉了。因此,我们需要记住的是,在定义目标变量名称的时候不能用数字打头。
## 数字打头不能做变量名的错误 1r <- iris$Species ## 报错信息如下 Error: unexpected symbol in "1r" ## 解决办法 ## 把数字去掉,只用字母作为变量名 r <- iris$Species
第三类:符号问题
中文逗号报错
如下:unexpected input in ‘XXX’, 这类错误是初学者常遇到的–中英文标点符号问题。新手在出现这类报错时,第一反应应该查看报错的位置 Error in 停在哪里。在下面例子中,句子停在了Species,"之后,通过仔细查看代码,能够发现句子中报错的位置是一个中文格式的逗号。因此,把中文格式的逗号改成英文格式即可,这种报错只要在R语言练习一段时间后就基本不会再烦了。
## 这类错误需要检查中英文标点符号 library(ggplot2) library(datasets) data(package="datasets") ## 查看该程序包里含有哪些数据集 data (iris) head (iris) a <- data.frame(iris$Species ,iris$Sepal.Width) ## 报错信息如下 Error: unexpected input in "a <- data.frame(iris$Species ,?" ## 解决办法 ## 将中文的标点符号改成英文模式下的即可 a <- data.frame(iris$Species, iris$Sepal.Width)
个人建议:由于rstudio刚开始使用时用的是默认的背景模板,为了在学习过程中节省一些时间,提高代码的准确率,可以用下面方法更换一下背景模板,选择一种最适合自己的模板,减少不必要的错误。

绝对路径的设定符号使用不规范
如下:unexpected input in “setwd(I:”,是路径未设定成功,但是根本报错是因为路径符号不对导致的。我们需要清楚在R语言中引用地址的时候,需要注意是’/‘还是’\‘(单向左还是双向右下的斜杠)。如果在地址引用时,用了’//‘或’‘就会报错。下面我们用例子来展示,我们发现我们在设置路径时,符号用错了,直接报错。在读取数据时,工作路径的符号也用错了,出现了同样的报错。这里,我们只需要熟记一点,在R语言中要用’/’ or '\'即可。
## 这类报错也属于符号使用错误
setwd("I:\R language\R语言郑师兄代码")
## 报错信息如下
Error: unexpected input in "setwd(I:\"
## 解决办法
## 把'\'改成 '/' or '\\'
setwd("I:\\R language\\R语言代码")
setwd("I:/R language/R语言代码")
## 同样是工作路径的情况
library(openxlsx)
mydata <- read.xlsx("I:\R language\R语言代码\图一.xlsx",2)
## 报错信息如下
Error: '\R' is an unrecognized escape in character string starting ""I:\R"
## 解决方法 与上述相同
mydata <- read.xlsx("I:\\R language\\R语言代码\\图一.xlsx",2)
报错结果如下:

更正后结果:

缺少括号或引号
如下:unexpected symbol in: “XXX”,这类报错是比较常见且简单的,属于缺少or多余符号。这类错误出现时,应该第一时间查看error中出现报错的位置,出现问题的地方在两个报错的两个双引号" "之间,因此应该出现在第一行和第二行代码之间。下面的例子中,我们发现缺少了括号,因此我们在代码的最后把括号补充上后,问题就解决了。
## 这类报错属于多余或缺少符号 library(ggplot2) library(datasets) data(package="datasets") ## 查看该程序包里含有哪些数据集 data(iris) head(iris) a <- data.frame(iris$Species,iris$Sepal.Width) mydata <- iris mydata <- as.data.frame(t(dat[,as.character(a$Species)]) # 这里看出少了一个括号。 mydata ## 报错信息如下 Error: unexpected symbol in: "mydata < as.data.frame(t(dat[,as.character(a$Species)]) mydata" ## 解决办法 ## 只需要删除多余和补充缺少的符号即可
个人建议:如果在输入有括号的代码时,可以把鼠标在每个右半边的括号点一下,rstudio会自带提醒这一组括号是否完成输入:当前括号表示是第二个左半边括号,因此需要在最右边再补充一个括号。

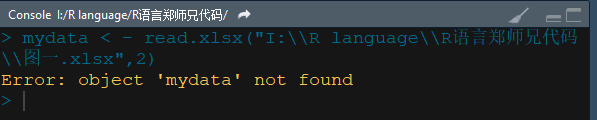
赋值号报错
通常用这两种方式来表示赋值,<- 或者 =。如果我们在去读时候赋值号使用有误,也会出现object ‘mydata’ not found。我用一个例子告诉大家,这里不是因为没有读取之前的目标,而是在编辑代码的过程中可能因为粗心等因素出现代码的小错误。具体情况如下:
## 这类属于未找到目标变量,但是属于代码错误的问题
library(openxlsx)
mydata < - read.xlsx("I:\\R language\\R语言郑师兄代码\\图一.xlsx",2)
## 报错信息如下
Error: object 'mydata' not found
## 仔细一看发现是赋值时候的符号被隔断了
## 解决方法
< - 改写成 <-即可
报错如下:
更正展示:

必要的引号与括号
我将这两个易犯的小错误合一起与大家分享。第一,忘记使用必要的引号;第二,在使用函数名时忘记使用括号。其实,这两类错误可能在之前也有提到一点。但是,这里我单独将他们拿出来讲,考虑到这两类错误新手特别容易犯。但是两类错误也是特别容易解决,只要在写代码的时候稍微小心一点就可以啦~图片下面我用一些具体的例子和大家展示:
## 特别是安装程序包时,必要的引号不能丢
install.packages(ggplot2)
## 报错信息如下
Error in install.packages : object 'ggplot2' not found
## 解决办法
## 所需安装的程序包加上引号即可
install.packages("ggplot2")
## 使用函数名时需要加括号,例如
help
## 报错信息如下
function (...)
## 解决办法,在函数名后添加括号
help()
## 此外,需要强调并不是所有函数都可以使用空白括号的
特别提醒:并不是所有函数名都可以用 XXX ( )来查询,有的函数名的括号内必须加入目标变量才可以访问。这里举一个简单的例子:例如head ( )

第四类:中文注释乱码
注释的信息显示乱码,这是新手常遇到的问题。首先,注释信息在你每次编辑一条代码之前、中间以及之后都可以进行。其次,你每次编辑完注释信息保存时都需要选择一种encoding,也就是编码方式。在windows系统下,read.csv ( )和read.table ( )方法不指定文件格式时,默认读取的格式为GBK(GB2312)。Rstudio里面有设置默认文本编码方式,但是修改前后读入中文数据情况都一样,encoding为UTF-8或GB2312都相同。然而,在Linux系统下,系统指定中文编码方式是UTF-8,所以read.csv ( )和read.table ( )都要求UTF-8。如下两个文件,分别是UTF-8格式和GBK格式,首先用read.csv读取,可以看到不指定编码方式时,读取UTF-8格式文件是乱码。用encoding指定读取的文件编码方式为UTF-8后,正常。这样看起来read.csv ( )方法读取UTF-8好像可行?总结一下,如果大家看不懂上面这一串没关系,在保存文件时选用UTF-8的编码格式,以及在打开一份code时,如果中文乱码就用UTF-8打开。无论保存还是打开文件都选择UTF-8格式即可。
如下情况:

将编码方式更改为UTF-8:

下面是重新以UTF-8格式打开一份代码:
file—reopen with encoding—utf-8—ok

第五类:数据集或变量长度不同
如下: ‘x’ and ‘w’ must have the same length, 这类错误也是较为常见的报错–通常为两个数据框的数据行与列长度不同。新手在出现这类报错时,第一反应看你在读取两个数据框时的数据行列数是否满足长度对等关系。我们通过下面例子来讲解这个报错需要注意的问题:我们在做一些需要两个数据集的分析时(例如beta分析,即在探究环境因子与微生物群落的关系时的一些距离分析,特别需要注意这个行列对等问题,因为代码只能识别行列对等的矩阵。这里,我们要记住读取数据时的几个比较重要的函数,header=T 这是个默认的函数,header=T 表示第一行设为每列的列名,这是默认代码,如果不需要可以将T改为F。row.names=1表示第一列设为每行的行名。有这个代码,意味着会少一列,注意这个函数在使用时要保证没有重复的名称。
## x和w长度需要一致,即两个矩阵的行列长度要对等
library(vegan)
library(grid)
env=read.csv("env(1)(1).csv", header=T, sep=",", row.names = 1) # read.csv读取csv格式的数据
env=data.matrix(env) # 将数据框转化为矩阵
env[is.na(env)]=0 # 去掉数据为0的值
speciesdata=read.csv("OTU(2).csv", header=T, sep=",")
speciesdata=data.matrix(speciesdata)
speciesdata[is.na(speciesdata)]=0
speciesdata=t(speciesdata)
speciesdata.cca=cca(speciesdata,env) #进行CCA分析
## 报错信息如下
Error in weighted.mean.default(newX[, i], ...) :
'x' and 'w' must have the same length
## 解决办法
## 由于是两个数据框的长度不同,那么只要将两个数据框对齐即可
speciesdata=read.csv("OTU(2).csv",header=T, sep=",") ## 在这行代码添加 row.names=1
speciesdata=read.csv("OTU(2).csv",header=T, sep=",",row.names=1)# 让430列变成429列 与第一矩阵长度相等
错误结果:

更正展示:

个人建议:这类报错–两个数据框/矩阵行列不对等时,我们在每读取一个文件时应该先看看环境中的数据框,可以用鼠标点开数据框,看看数据框读取的结果与自己预期的结果以及在正常excel下打开的是否一致,再去判断在运行代码时能否成功等等。

补充:有一些错误是R的初学者和经验丰富的R程序员都可能常犯的。
如果程序出错了,请检查一下几个方面。
- 使用了错误的大小写。help(),Help() 和 HELP() 是三个不同的函数(只有第一个是正确的)。
- 忘记使用必要的引号。install.packages("gclus") 能够正常执行,然后Install.packages(gclus)将会报错。
- 在函数调用时忘记使用括号。例如,要使用help()而非help。即使函数无需参数,仍需加上()。
- 在Windows上,路径名中使用了\。R将反斜杠视为一个转义字符。setwd("c:\mydata")会报错。正确的写法是setwd("c:/mydata")或setwd("c:\\mydata")。
- 使用了一个尚未载入包中的函数。函数order.cluster()包含在包gclus中。如果还没有载入这个包就使用它,将会报错。
R的报错信息可能是含义模糊的,但如果谨慎遵守了以上要点,就应该可以避免许多错误。
总结
加载全部内容