Python BautifulSoup
万里顾一程 人气:01、获取节点的内容
获取节点内容:
如果要获得节点中的文本内容,可以用 string 或 get_text()
- string:只能获得节点中的文本内容,如果节点中有子孙节点,string就获取不到内容,返回 None
- get_text() 推荐使用:获取到节点中包含的所有内容包括子孙节点中的内容
- 可以使用get_text() 方法快速得到源文件中的所有文本内容,如 soup.get_text()
使用实例:
待解析的html文本文件如下:id为al的p标签有子孙节点,id为bl的span标签没有子孙节点
<!DOCTYPE html>
<html lang="en">
<head>
<title>test</title>
</head>
<body>
<p class="title"/>
<a href="http://localhost:8080" rel="external nofollow" rel="external nofollow" rel="external nofollow" />
<div>
<p class="story" id="al">
<a class="s1" href="www.baidu.com" rel="external nofollow" id="l1">a1</a>
<a class="s2" href="" id=" rel="external nofollow" rel="external nofollow" l2">a2</a>
<a class="s3" href="" id=" rel="external nofollow" rel="external nofollow" l3">a3</a>
<span>span</span>
</p>
<span id="bl">
方唐镜
</span>
</div>
</body>
</html>使用实例1:对p标签和span标签进行解析,打印里面的内容
from bs4 import BeautifulSoup
#使用 lxml 解析器
soup = BeautifulSoup(open('test.html',encoding='utf-8'),'lxml')
list = soup.select('#al')[0]
print(list.string)
print(list.get_text())执行结果及说明:
用string获取p标签的文本内容,因为p标签有子孙节点,所以返回None;
get_text()获取p标签的文本内容,返回p标签及子孙节点中的文本内容;
None # 用 a1 a2 a3
使用实例2:对span标签进行解析,打印里面的内容
span = soup.select('#bl')[0]
print(span.string)
print(span.get_text())执行结果及说明:
string获取span标签的文本内容,因为span标签没有子孙节点,所以可以返回文本内容;
用get_text()获取span标签的文本内容,因为span标签没有子孙节点,所以只返回span标签的文本内容;
span
方唐镜
方唐镜
2、获取节点的名称
.name 获取节点的名称
待解析的html文本文件:
<!DOCTYPE html>
<html lang="en">
<head>
<title>test</title>
</head>
<body>
<p class="title"/>
<a href="http://localhost:8080" rel="external nofollow" rel="external nofollow" rel="external nofollow" />
<div>
<span id="span" class="c1">
方唐镜
</span>
</div>
</body>
</html>获取节点的属性实例:
from bs4 import BeautifulSoup
#使用 lxml 解析器
soup = BeautifulSoup(open('test.html',encoding='utf-8'),'lxml')
# 根据class选择器查找,返回第一个节点
obj = soup.select('.c1')[0]
print(obj.name)执行结果:该节点为span节点
span
3、获取节点的属性值
.attrs 获取获取节点的属性值,并以字典的形式返回
待解析的html文本文件:
<!DOCTYPE html>
<html lang="en">
<head>
<title>test</title>
</head>
<body>
<p class="title"/>
<a href="http://localhost:8080" rel="external nofollow" rel="external nofollow" rel="external nofollow" />
<div>
<span id="span" class="c1">
方唐镜
</span>
</div>
</body>
</html>获取节点的属性实例:
from bs4 import BeautifulSoup
#使用 lxml 解析器
soup = BeautifulSoup(open('test.html',encoding='utf-8'),'lxml')
# 根据class选择器查找,返回第一个节点
obj = soup.select('.c1')[0]
print(obj.attrs)执行结果:以字典的形式返回
{'id': 'span', 'class': ['c1']}可以通过get方法获得字典里指定属性的属性值:有下面三种方法
# 获取class属性的属性值
#方式一(推荐)
print(obj.attrs.get('class'))
#方式二
print(obj.get('class'))
#方式三
print(obj['class'])执行结果:
['c1']
['c1']
['c1']
3、BS4具体使用
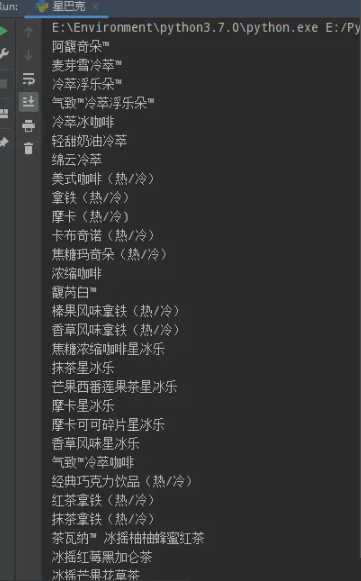
代码实例:获取所有饮品的名称·
import urllib.request
from bs4 import BeautifulSoup
from lxml import etree
url = 'https://www.starbucks.com.cn/menu/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.2242 SLBChan/10'
}
# 定制请求,发送请求并返回响应对象和html文档
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# 使用 lxml 解析器
soup = BeautifulSoup(content,'lxml')
# 检索html文档,返回列表形式
name_list = soup.select('ul[class="grid padded-3 product"] strong')
# 遍历打印
for name in name_list:
print(name.string)执行结果:
加载全部内容