MySQL 数据类型
行百里er 人气:0不超过范围的情况下,数据类型越小越好
应该尽量使用可以正确存储数据的最小数据类型,更小的数据类型通常更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期更少。
但是要确保选择的存储类型范围足够用,如果无法确认哪个数据类型,就选择你认为不会超过范围的最小类型。
看一个案例,下面是两张字段相同,字段类型相同,只是 id 字段 emp1 是 smallint 类型, emp2 的 id 是 bigint 类型,分别向两个表插入 5000 条记录,观察一下表容量大小。
CREATE TABLE `mytest`.`emp1` ( `id` smallint(5) NULL, `name` varchar(255) NULL); CREATE TABLE `mytest`.`emp2` ( `id` bigint(5) NULL, `name` varchar(255) NULL);
两个表的初始大小是一致的,都是 96K :
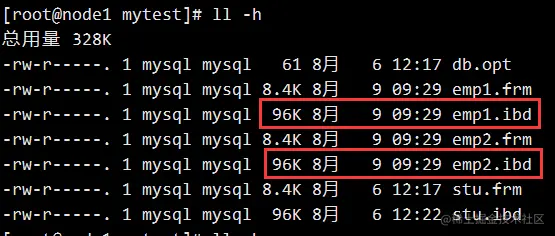
PS:可以用如下命令查看数据文件的存放位置:
> mysql> show variables like '%datadir%'; +---------------+-----------------+ | Variable_name | Value | +---------------+-----------------+ | datadir | /var/lib/mysql/ | +---------------+-----------------+ 1 row in set (0.01 sec)
为了方便,写个 shell 脚本分别向两个表插入 5000 条记录:
#!/bin/bash
i=1
while [ $i -le 5000 ]
do
mysql -uroot -p123456 mytest -e "insert into emp2 (id,name) values ($i,'n$i');"
i=$(($i+1))
done注意表名,emp1 和 emp2 分别执行一遍。
执行完毕,确认两个表都是 5000 条记录:
mysql> select count(*) from emp1; +----------+ | count(*) | +----------+ | 5000 | +----------+ 1 row in set (0.03 sec) mysql> select count(*) from emp2; +----------+ | count(*) | +----------+ | 5000 | +----------+ 1 row in set (0.01 sec)
来,见证一下奇迹先:
[root@node1 mytest]# ll -h | grep emp1.ibd && ll -h | grep emp2.ibd -rw-r-----. 1 mysql mysql 272K 8月 9 09:33 emp1.ibd -rw-r-----. 1 mysql mysql 304K 8月 9 09:37 emp2.ibd
可以发现,两个表占用的空间竟然不一样,表 emp1 id字段类型 smallint(5) 插入 5000 条记录后占用空间为 272K ,而 emp2 id字段类型 bigint(5) 插入同样的数据后占用空间大小为 304K 。
这就是所谓 不超过范围的情况下,数据类型越小越好 。
简单就好
简单数据类型的操作通常需要更少的CPU周期
- 1、整型比字符操作代价更低,因为字符集和校对规则是字符比较比整型比较更复杂;
- 2、使用 MySQL 自建类型而不是字符串来存储日期和时间;
- 3、用整型存储IP地址。
我们拿日期数据类型来举个例子,同样建两张表:
CREATE TABLE `tab1` ( `id` smallint(5) NULL, `name` varchar(255) NULL, `ctime` date NULL ); CREATE TABLE `tab2` ( `id` smallint(5) NULL, `name` varchar(255) NULL, `ctime` datetime NULL );
tab1 的 ctime 字段类型为 date ,tab2 的 ctime 字段类型为 datetime ,同样,执行 shell 脚本,插入 20000 条记录:
#!/bin/bash
i=1
while [ $i -le 20000 ]
do
mysql -uroot -p123456 test -e "insert into tab1 (id,name,ctime) values ($i,'n$i',now());"
i=$(($i+1))
done
改下脚本,再向表 tab2 插入 20000 条记录。
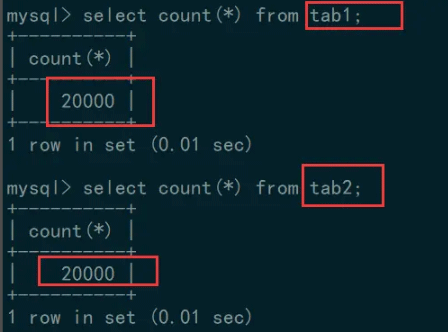
数据准备完毕后,我们来分别查询一下这两个表:
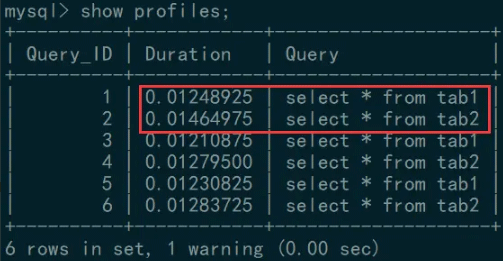
look,看到了,查询两个表的 SQL 语句执行速度不一样(样本量可能还有点小)!
尽量避免 null
如果查询中包含可为 NULL 的列,对 MySQL 来说很难优化,因为可为 null 的列使得 索引 、 索引统计 和 值比较 都更加复杂。
通常情况下 null 的列改为 not null 带来的性能提升比较小,所有没有必要将所有的表的 schema 进行修改,但是应该尽量避免设计成可为 null 的列。
一切以实际情况为准 。
一些细则
整数类型
可以使用的几种整数类型:
- TINYINT 8 bit,
- SMALLINT 16 bit,
- MEDIUMINT 24 bit,
- INT 32 bit,
- BIGINT 64 bit
尽量使用满足需求的最小数据类型。前文有述。
字符和字符串类型
varchar :根据实际内容长度保存数据。
使用最小的符合需求的长度:
varchar(n) :n小于等于255使用额外一个字节保存长度,n>255使用额外两个字节保存长度。
varchar(5) 与 varchar(255) 保存同样的内容,硬盘存储空间相同,但内存空间占用不同,是指定的大小 。
varchar在 MySQL 5.6 之前变更长度,或者从255一下变更到255以上时,都会导致 锁表 。
varchar应用场景:
存储长度波动较大的数据,如:文章,有的会很短有的会很长;
字符串很少更新的场景,每次更新后都会重算并使用额外存储空间保存长度;
适合保存多字节字符,如:汉字,特殊字符等。
char:固定长度的字符串
最大长度:255;
会自动删除末尾的空格;
检索效率、写效率 会比varchar高,以空间换时间。
char 使用场景:
存储长度波动不大的数据,如:md5摘要;
存储短字符串、经常更新的字符串。
BLOB 和 TEXT 类型
MySQL 把每个 BLOB 和 TEXT值当作一个独立的对象处理。
两者都是为了存储很大数据而设计的字符串类型,分别采用二进制和字符方式存储。
日期时间
datetime
- 占用8个字节;
- 与时区无关,数据库底层时区配置,对 datetime 无效;
- 可保存到毫秒;
- 可保存时间范围大;
- 不要使用字符串存储日期类型,占用空间大,损失日期类型函数的便捷性。
timestamp
- 占用4个字节;
- 时间范围:1970-01-01到2038-01-19;
- 精确到秒;
- 采用整形存储;
- 依赖数据库设置的时区;
- 自动更新timestamp列的值。
date
- 占用的字节数比使用字符串、datetime、int存储要少,使用date类型只需要3个字节;
- 使用date类型还可以利用日期时间函数进行日期之间的计算;
- date类型用于保存1000-01-01到9999-12-31之间的日期。
使用枚举代替字符串类型
有时可以使用 枚举 类型代替常用的字符串类型,MySQL 存储枚举类型会非常紧凑,会根据列表值的数据压缩到一个或两个字节中,MySQL 在内部会将每个值在列表中的位置保存为整数,并且在表的 .frm 文件中保存“数字-字符串”映射关系的查找表。
特殊类型数据
曾经我使用 varchar(15) 来存储 ip 地址,然而,ip 地址的本质是 32 位无符号整数不是字符串,可以使用 INET_ATON 和 INET_NTOA 函数在这两种表示方法之间转换。
比如:
mysql> select inet_aton('192.168.134.119');
+------------------------------+
| inet_aton('192.168.134.119') |
+------------------------------+
| 3232269943 |
+------------------------------+
1 row in set (0.03 sec)
mysql> select inet_ntoa('3232269943');
+-------------------------+
| inet_ntoa('3232269943') |
+-------------------------+
| 192.168.134.119 |
+-------------------------+
1 row in set (0.03 sec)加载全部内容