Kotlin Flow封装类
newki 人气:0Kotlin中SharedFlow的使用 VS StateFlow
SharedFlow 是继承于 Flow ,同时它是 StateFlow 的父类,它们都是是热流,先说一下冷流与热流的概念。
- 冷流 :只有订阅者订阅时,才开始执行发射数据流的代码。并且冷流和订阅者只能是一对一的关系,当有多个不同的订阅者时,消息是重新完整发送的。也就是说对冷流而言,有多个订阅者的时候,他们各自的事件是独立的。
- 热流:无论有没有订阅者订阅,事件始终都会发生。当 热流有多个订阅者时,热流与订阅者们的关系是一对多的关系,可以与多个订阅者共享信息。
SharedFlow的特点
- SharedFlow没有默认值
- SharedFlow可以保存旧的数据,根据配置可以将旧的数据回播给新的订阅者
- SharedFlow使用emit/tryEmit发射数据,StateFlow内部其实都是调用的setValue。
- SharedFlow会挂起直到所有的订阅者处理完成。
为什么我先讲的 StateFlow ,而不是SharedFlow,是因为 StateFlow 是 继承 SharedFlow 实现,是在其基础的场景化实现,我们可以把 StateFlow 理解为是 SharedFlow 的 “青春版”。并不是它更轻量,而是它使用更简单。
我们举例看看怎么使用 SharedFlow,看看它与 StateFlow的区别。
既然 StateFlow 是 继承 SharedFlow 实现,那么StateFlow
一、SharedFlow的使用
方式一,我们自己 new 出来
public fun <T> MutableSharedFlow(
// 重放数据个数
replay: Int = 0,
// 额外缓存容量
extraBufferCapacity: Int = 0,
// 缓存溢出策略
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): MutableSharedFlow<T> {
val bufferCapacity0 = replay + extraBufferCapacity
val bufferCapacity = if (bufferCapacity0 < 0) Int.MAX_VALUE else bufferCapacity0 // coerce to MAX_VALUE on overflow
return SharedFlowImpl(replay, bufferCapacity, onBufferOverflow)
}
public enum class BufferOverflow {
// 挂起
SUSPEND,
// 丢弃最早的一个
DROP_OLDEST,
// 丢弃最近的一个
DROP_LATEST
}
举例说明
@HiltViewModel
class Demo4ViewModel @Inject constructor(
val savedState: SavedStateHandle
) : BaseViewModel() {
private val _sharedFlow = MutableSharedFlow<String>(replay = 1, onBufferOverflow = BufferOverflow.SUSPEND)
val sharedFlow: SharedFlow<String> = _sharedFlow
fun changeSearch(keyword: String) {
_sharedFlow.tryEmit(keyword)
}
}
在Activity中我们就可以像类似 LiveData 一样的使用 SharedFlow
private fun testflow() {
mViewModel.changeSearch("key")
}
override fun startObserve() {
mViewModel.sharedFlow.collect {
YYLogUtils.w("value $it")
}
}
方式二,通过一个 冷流 Flow 转换为 sharedFlow
class NewsRemoteDataSource(...,
private val externalScope: CoroutineScope,
) {
val latestNews: Flow<List<ArticleHeadline>> = flow {
...
}.shareIn(
externalScope,
replay = 1,
started = SharingStarted.WhileSubscribed() // 启动政策
)
}
几个重要参数的说明如下
- scope 共享开始时所在的协程作用域范围
- started 控制共享的开始和结束的策略
- replay 为0 代表不重放,也就是没有粘性,为1 代表重放最新的一个数据
scope 和 replay 不需要过多解释,主要介绍下 started: SharingStarted 启动策略,分为三种:
Eagerly(热启动式): 立即启动数据流,并保持数据流(直到 scope 指定的作用域结束);
Lazily(懒启动式): 在首个订阅者注册时启动,并保持数据流(直到 scope 指定的作用域结束);
WhileSubscribed(): 在首个订阅者注册时启动,并保持数据流直到在最后一个订阅者注销时结束(或直到 scope 指定的作用域结束)。
使用示例:
val sharedFlow = flowOf(1, 2, 3).shareIn(
scope = lifecycleScope,
// started = WhileSubscribed(5000, 1000),
// started = Eagerly,
started = Lazily,
replay = 0
)
lifecycleScope.launch {
sharedFlow.collect {
YYLogUtils.w("shared-value $it")
}
}
打印结果:
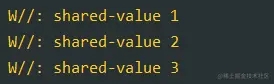
创建的几种方式基本和StateFlow类似,那么它们之间有什么区别?
二、SharedFlow、StateFlow、LiveData的对比
我们直接举例,实现 LiveData 的功能。我们看看 LiveData StateFlow SharedFlow 实现同样的效果如何操作
@HiltViewModel
class Demo4ViewModel @Inject constructor(
val savedState: SavedStateHandle
) : BaseViewModel() {
private val _searchLD = MutableLiveData<String>()
val searchLD: LiveData<String> = _searchLD
private val _searchFlow = MutableStateFlow("")
val searchFlow: StateFlow<String> = _searchFlow
private val _sharedFlow = MutableSharedFlow<String>(replay = 1, onBufferOverflow = BufferOverflow.SUSPEND)
val sharedFlow: SharedFlow<String> = _sharedFlow
fun changeSearch(keyword: String) {
_sharedFlow.tryEmit(keyword)
_searchFlow.value = keyword
_searchLD.value = keyword
}
}
打印的结果:

可以看到 SharedFlow 通过设置之后是可以达到 LiveData 和 StateFlow 的效果的。
SharedFlow对比StateFlow的优势,不需要设置默认值,没有默认值的发送。
SharedFlow对比StateFlow的劣势,不能自由取值,这是致命的。
例如下面的代码,StateFlow 我可以在代码的任意地方取值,但是 SharedFlow 只能接收流,不能自由取值。

所以,我们一般才说 StateFlow 平替 LiveData,虽然 SharedFlow 可以通过 参数的方式达到一部分 LiveData 的效果,但是痛点更明显。
另外需要说明的是 StateFlow 与 SharedFlow 这么设置是去重的,也就是说如果点击登录按钮之后登录失败报告密码错误,然后再次点击登录按钮,就不会弹出吐司了。
这不符合我们的业务场景啊,如果按照 StateFlow 平替 LiveData 的原则,我们还需要改用 Channel 的方式才行 (毕竟SharedFlow不能自由取值真的不适合这个场景)。
@HiltViewModel
class Demo4ViewModel @Inject constructor(
val savedState: SavedStateHandle
) : BaseViewModel() {
val channel = Channel<String>(Channel.CONFLATED)
private val _searchLD = MutableLiveData<String>()
val searchLD: LiveData<String> = _searchLD
private val _searchFlow = MutableStateFlow("")
val searchFlow: StateFlow<String> = _searchFlow
private val _sharedFlow = MutableSharedFlow<String>(replay = 1, onBufferOverflow = BufferOverflow.SUSPEND)
val sharedFlow: SharedFlow<String> = _sharedFlow
fun changeSearch(keyword: String) {
_sharedFlow.tryEmit(keyword)
_searchFlow.value = keyword
_searchLD.value = keyword
channel.trySend(keyword)
}
}
private fun testflow() {
mViewModel.changeSearch("1234")
}
override fun startObserve() {
mViewModel.searchLD.observe(this) {
YYLogUtils.w("value $it")
}
lifecycleScope.launch {
mViewModel.sharedFlow.collect {
YYLogUtils.w("shared-value1 $it")
}
}
lifecycleScope.launch {
mViewModel.channel.consumeAsFlow().collect {
YYLogUtils.w("shared-value2 $it")
}
}
lifecycleScope.launchWhenCreated {
mViewModel.searchFlow.collect {
YYLogUtils.w("state-value $it")
}
}
}
我们加入了使用 Channel 的方式,前文我们讲过 Channel 是协程中的通信通道,我们这边发送那一边转为Flow来collect。打印结果如下:
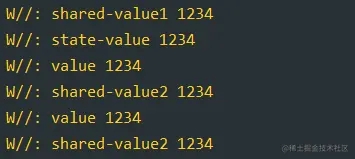
好麻烦哦,这还不如LiveData呢,所以大家知道 StateFlow 与 LiveData 的优缺点之后,按需选择即可。
三、SharedFlow 的粘性设置与事件总线
可以看到虽然 SharedFlow 不能平替 LiveData ,但是它在事件的发送与接收相关的配置与使用到时得天独厚,我们常用于事件总线的实现,例如SharedFlowBus,用于替代 EventBus
object FlowBus {
private val busMap = mutableMapOf<String, EventBus<*>>()
private val busStickMap = mutableMapOf<String, StickEventBus<*>>()
@Synchronized
fun <T> with(key: String): EventBus<T> {
var eventBus = busMap[key]
if (eventBus == null) {
eventBus = EventBus<T>(key)
busMap[key] = eventBus
}
return eventBus as EventBus<T>
}
@Synchronized
fun <T> withStick(key: String): StickEventBus<T> {
var eventBus = busStickMap[key]
if (eventBus == null) {
eventBus = StickEventBus<T>(key)
busStickMap[key] = eventBus
}
return eventBus as StickEventBus<T>
}
//真正实现类
open class EventBus<T>(private val key: String) : LifecycleObserver {
//私有对象用于发送消息
private val _events: MutableSharedFlow<T> by lazy {
obtainEvent()
}
//暴露的公有对象用于接收消息
val events = _events.asSharedFlow()
open fun obtainEvent(): MutableSharedFlow<T> = MutableSharedFlow(0, 1, BufferOverflow.DROP_OLDEST)
//主线程接收数据
fun register(lifecycleOwner: LifecycleOwner, action: (t: T) -> Unit) {
lifecycleOwner.lifecycle.addObserver(this)
lifecycleOwner.lifecycleScope.launch {
events.collect {
try {
action(it)
} catch (e: Exception) {
e.printStackTrace()
YYLogUtils.e("FlowBus - Error:$e")
}
}
}
}
//协程中发送数据
suspend fun post(event: T) {
_events.emit(event)
}
//主线程发送数据
fun post(scope: CoroutineScope, event: T) {
scope.launch {
_events.emit(event)
}
}
//自动销毁
@OnLifecycleEvent(Lifecycle.Event.ON_DESTROY)
fun onDestroy() {
YYLogUtils.w("FlowBus - 自动onDestroy")
val subscriptCount = _events.subscriptionCount.value
if (subscriptCount <= 0)
busMap.remove(key)
}
}
class StickEventBus<T>(key: String) : EventBus<T>(key) {
override fun obtainEvent(): MutableSharedFlow<T> = MutableSharedFlow(1, 1, BufferOverflow.DROP_OLDEST)
}
}
发送与接收消息
// 主线程-发送消息
FlowBus.with<String>("test-key-01").post(this@Demo11OneFragment2.lifecycleScope, "Test Flow Bus Message")
// 接收消息
FlowBus.with<String>("test-key-01").register(this) {
LogUtils.w("收到FlowBus消息 - " + it)
}
发送粘性消息
FlowBus.withStick<String>("test-key-02").post(lifecycleScope, "Test Stick Message")
// 接收粘性消息
FlowBus.withStick<String>("test-key-02").register(this){
LogUtils.w("收到粘性消息:$it")
}
看源码就知道粘性的实现就得益于 SharedFlow 的构造参数
replay的设置 ,代表重放的数据个数
replay 为0 代表不重放,也就是没有粘性
replay 为1 代表重放最新的一个数据,后来的接收器能接受1个最新数据。
replay 为2 代表重放最新的两个数据,后来的接收器能接受2个最新数据。
我们知道Flow的操作符有针对背压的处理,那么 SharedFlow 内部还对背压做了快速处理。我们只需要通过参数快速设置即可实现。
extraBufferCapacity的设置,额外数据的缓存
当上游事件发送过快,而消费太慢的情况,这种情况下,就需要使用缓存池,把未消费的数据存下来。
缓冲池容量 = replay + extraBufferCapacity
如果总量为 0 ,就 Int.MAX_VALUE
onBufferOverflow的设置
如果指定了有限的缓存容量,那么超过容量以后怎么办?
BufferOverflow.SUSPEND : 超过就挂起,默认实现
BufferOverflow.DROP_OLDEST : 丢弃最老的数据
BufferOverflow.DROP_LATEST : 丢弃最新的数据
总结
StateFlow 更加简便特定的场景使用,而 SharedFlow 更加的灵活,他们两者的侧重点也不同。
SharedFlow 基于缓存的处理可以实现一些特定的需求,如当发生订阅时,我需要将过去已经更新的N个值,同步给新的订阅者。比如有多个新的订阅者都想订阅这些改动的值。都可以使用 SharedFlow 来实现
而关于 SharedFlow、StateFlow、LiveData的对比,个人的结论是:根据不同的场景 LiveData StateFlow SharedFlow 都有自己特定的使用场景,谁也无法真的完全平替谁。谁也不是谁的超集,都有它们各自的有点和缺点,并不能完美覆盖所有场景,所以根据使用的场景不同按需选择即可。
关于StateFlow 与 SharedFlow 的实战,后面会总结一期。
加载全部内容