python pika库调用
IT之一小佬 人气:0前言:
python使用pika库调用rabbitmq的参数有三种方式,分别如下所述:
1、应答参数
auto_ack=False ch.basic_ack(delivery_tag=method.delivery_tag)
生产者模式:
示例代码:
import pika
# 1.连接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.124.104'))
channel = connection.channel()
# 2.创建队列
channel.queue_declare(queue='hello')
# 3.向指定队列插入数据
channel.basic_publish(exchange='', # 简单模式
routing_key='hello', # 指定队列
body='Hello World!') # 向队列中添加的数据
print(" [x] Sent 'Hello World!'")运行结果:

消费者模式:
示例代码:
import pika
# 1.连接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.124.104'))
channel = connection.channel()
# 2.创建队列
# 注意:这一步不是必须的,但是如果消费者先启动而不是生成者先启动时,这时队列中还没有hello队列,这时就会报错
channel.queue_declare(queue='hello')
# 3.确定回调函数
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
# 4.确定监听队列参数
channel.basic_consume(queue='hello',
auto_ack=False, # 手动应答方式
on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
# 5.正式监听
channel.start_consuming()运行结果:

注意:添加应答参数的好处是当消费者处理回调函数的时,万一程序报错,此时数据就会消失的。使用应答方式后,消费者程序万一报错,修改完程序后重新启动程序还是可以继续消费上一次的数据的。使用应答参数后,没处理完一条数据都会给队列一个反馈消息的,也就是说消费完一条消息后队列才会删除这条消息。这种方式效率会降低一些,根据项目中数据的重要性可以选择是否需要这个参数。
2、持久化参数
#声明queue
channel.queue_declare(queue='hello2', durable=True) # 若声明过,则换一个名字
channel.basic_publish(exchange='',
routing_key='hello2',
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)生成者方式:
示例代码:
import pika
# 1.连接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.124.104'))
channel = connection.channel()
# 2.创建持久化队列
# 注意:非持久化队列不能变持久化队列,反之也是这样的,所有创建队列中不能创建和非持久化队列重名的队列
channel.queue_declare(queue='hello2', durable=True)
# 3.向指定队列插入数据
channel.basic_publish(exchange='', # 简单模式
routing_key='hello2', # 指定队列
body='Hello World!', # 向队列中添加的数据
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
print(" [x] Sent 'Hello World!'")运行结果:

消费者方式:
示例代码:
import pika
# 1.连接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.124.104'))
channel = connection.channel()
# 2.创建持久化队列
# 注意:非持久化队列不能变持久化队列,反之也是这样的,所有创建队列中不能创建和非持久化队列重名的队列
# 注意:这一步不是必须的,但是如果消费者先启动而不是生成者先启动时,这时队列中还没有hello2队列,这时就会报错
channel.queue_declare(queue='hello2', durable=True)
# 3.确定回调函数
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
# 4.确定监听队列参数
channel.basic_consume(queue='hello2', # 指定队列
auto_ack=False, # 手动应答方式
on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
# 5.正式监听
channel.start_consuming()运行结果:

注意:加入持久化参数的好处,当rabbitmq队列万一崩了时,此时队列中的所有数据都会丢失,rabbitmq队列中的数据是保存在内存中,当加入持久化参数后,数据将会保存在硬盘中,rabbitmq崩了或者重启不会丢失数据。
3、分发参数
有两个消费者同时监听一个的队列。其中一个线程sleep2秒,另一个消费者线程sleep1秒,但是处理的消息是一样多。这种方式叫轮询分发(round-robin)不管谁忙,都不会多给消息,总是你一个我一个。想要做到公平分发(fair dispatch),必须关闭自动应答ack,改成手动应答。使用basicQos(perfetch=1)限制每次只发送不超过1条消息到同一个消费者,消费者必须手动反馈告知队列,才会发送下一个。
channel.basic_qos(prefetch_count=1)
生产者模式:
示例代码: 【为了产生多条数据,将此程序执行多次】
import pika
# 1.连接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.124.104'))
channel = connection.channel()
# 2.创建队列
channel.queue_declare(queue='hello3')
# 3.向指定队列插入数据
channel.basic_publish(exchange='', # 简单模式
routing_key='hello3', # 指定队列
body='Hello World666!', # 向队列中添加的数据
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
print(" [x] Sent 'Hello World!'")运行结果:

消费者模式:
示例代码1:
import pika
# 1.连接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.124.104'))
channel = connection.channel()
# 2.创建队列
# 注意:这一步不是必须的,但是如果消费者先启动而不是生成者先启动时,这时队列中还没有hello2队列,这时就会报错
channel.queue_declare(queue='hello3')
# 3.确定回调函数
def callback(ch, method, properties, body):
import time
time.sleep(15)
print(" [x] Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
# 公平分发,若不加下面这行代码,默认是轮询分发
channel.basic_qos(prefetch_count=1)
# 4.确定监听队列参数
channel.basic_consume(queue='hello3', # 指定队列
auto_ack=False, # 手动应答方式
on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
# 5.正式监听
channel.start_consuming()运行结果:
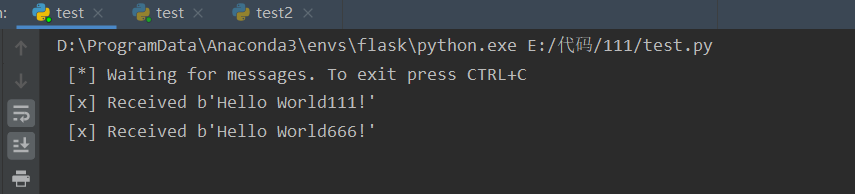
示例代码2:
import pika
# 1.连接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.124.104'))
channel = connection.channel()
# 2.创建队列
# 注意:这一步不是必须的,但是如果消费者先启动而不是生成者先启动时,这时队列中还没有hello2队列,这时就会报错
channel.queue_declare(queue='hello3')
# 3.确定回调函数
def callback(ch, method, properties, body):
import time
time.sleep(3)
print(" [x] Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
# 公平分发,若不加下面这行代码,默认是轮询分发
channel.basic_qos(prefetch_count=1)
# 4.确定监听队列参数
channel.basic_consume(queue='hello3', # 指定队列
auto_ack=False, # 手动应答方式
on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
# 5.正式监听
channel.start_consuming()注意:当一个py文件执行多次时,会有下面提示:
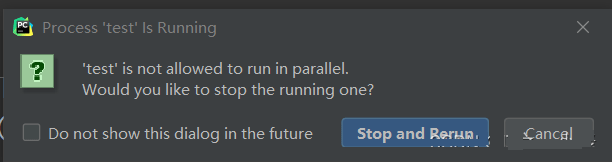
运行结果:
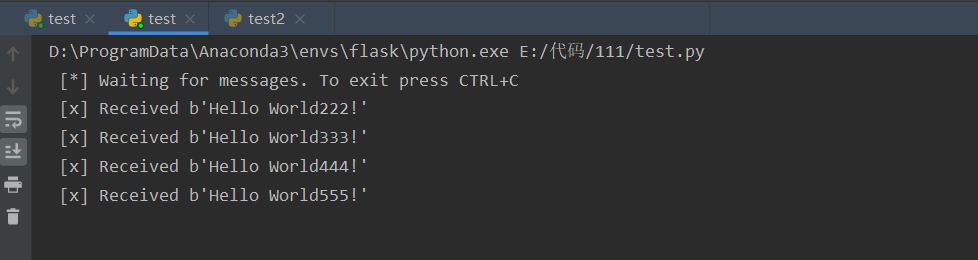
加载全部内容