python自动更新
烟花散尽13141 人气:0前言
项目越来越多,版本管理越来越麻烦,在项目上我使用 maven version 来进行版本管理。主要还是在分布式项目中模块众多的场景中使用,毕竟各个模块对外的版本需要保持统一。
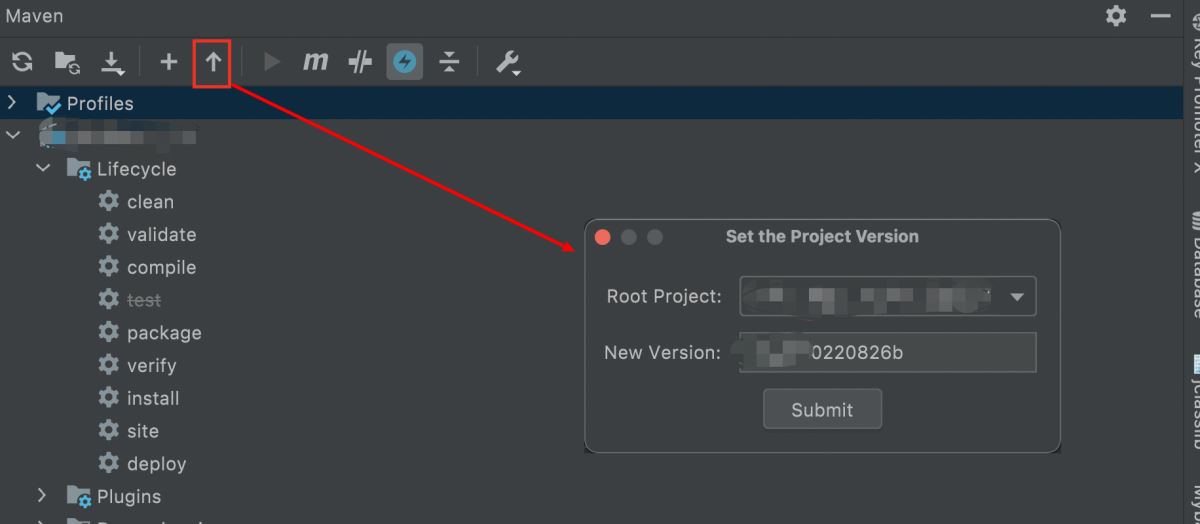
关于这个插件如何使用呢?也是非常的简单。只需要在maven视图中进行设置版本号即可将分模块项目的版本进行升级了。
除了idea插件外,maven本身也提供了一个版本管理工具 versions-maven-plugin 。 具体用法以后有机会在赘述。
自定义实现版本更新
- 作为一个专业懒人,我还是觉得idea的插件不够智能,确切的说还不够自动化。之前我已经动手实现了防 jenkins 自动打包上传启动服务的脚本的功能了,难道提交合并代码这种简单的事情还需要我自己处理吗。不得不承认代码冲突了的确还是需要认为干涉的,但是在平时开发中有多少概率会发生代码冲突呢?我们都是分工合作基本上代码冲突概率很低。
- 关于代码提交,自己分支如何合并到dev, 如何保证自己分支代码最新等等这些场景我们只需要通过脚本来进行自动化操作就行了。针对这些功能场景我大概写了两个脚本
batfhmerge.sh和batchgrade.sh就搞定了。 - 然而我想说的是关于项目的版本如何升级。上面也提到了我们分工合作就必然涉及到别人使用你的jar的场景了。你可以使用
SNAPSHOT版本来保证别人拉取到你最新的功能代码,但是有些公司会要求使用非SNAPSHOT版本进行管理也就是正式版本,这样做的好处就是容易找到之前的版本代码功能。
SHELL 实现
之前用SHELL 实现了自动更新置顶项目的版本号为最新日期后缀。虽然使用起来没发现有什么BUG, 但是感觉代码实现上还是很弱智的。
# 该脚本主要用来升级发包期间修改各服务版本
FILEPATH=$1
GROUPID=$2
ARTIFACTID=$3
FILENAME=$4
while getopts ":f:g:a:" opt
do
case $opt in
f)
FILENAME=$OPTARG
echo "您输入的文件配置:$FILENAME"
;;
g)
GROUPID=$OPTARG
echo "您输入的groupid配置:$GROUPID"
;;
a)
ARTIFACTID=$OPTARG
echo "您输入的artifactid配置:$ARTIFACTID"
;;
ff)
FILENAME=$OPTARG
echo "您输入的带修改文件为:$FILENAME"
;;
?)
echo "未知参数"
exit 1;;
esac
done
echo "开始修改版本号"
NEWCONTENT=1.2.5.$(date +%Y%m%d)
LINE=`cat ${FILENAME} | grep -n -A 1 '<groupId>'"${GROUPID}"'<\/groupId>'| grep -n '<artifactId>'"${ARTIFACTID}"'<\/artifactId>' | awk -F "[:-]+" '{print $2}'`
echo 具体行号:$LINE
if [[ -z $LINE ]]
then
echo 未匹配
exit
fi
VERSIONOLDCONTENT=`sed -n ''"$((LINE+1))"'p' ${FILENAME}| grep '[0-9a-zA-Z\.-]+' -Eo | sed -n '2p'`
echo ${VERSIONOLDCONTENT}
#gsed -i ''"$((LINE+1))"'c\'"${NEWCONTENT}"'' pom.xml
sed -i "" ''"$((LINE+1))"'s/'"${VERSIONOLDCONTENT}"'/'"${NEWCONTENT}"'/' ${FILENAME}- 其实逻辑很简单,主要就是寻找
groupId和artifactId,最后确定好version对应的行号将最新的日期后缀版本进行填充进去。 - 填充呢肯定需要三剑客中的
SED进行操作,那就需要先获取到以前的旧版本,然后进行替换操作。
为什么使用SHELL
- shell脚本作为后端程序猿必备技能选择他进行实现也是为了温故下shell的知识。基本上脚本离不开三剑客,换句话说会了三剑客你就可以做好半个运维工作了。
- 有了这个脚本我每次在功能开发完成之后,会通过SHELL脚本进行版本升级以及自己分支合并到dev分支,这样方便别人获取到最新的代码。
python实现
- SHELL脚本定制度很高,很难做到自动的兼容功能。比如上面我们在定位包的时候是通过grep进行定位的,正常情况下应该是没什么问题的,但是当pom.xml 出现被注释的同名坐标时或者说名称存在其他相似度的情况下很难保证SHELl脚本还能够正确的解析出来。
- 除此之外还有一个重要的原因就是SHELL脚本很难在windows 运行,为了能够兼顾到windows电脑我决定用python 进行重新实现该功能。
文件思考
- 与SHELL不同的是 python处理需要考虑文件格式的问题。SHELL中不管什么格式都是通过三剑客进行定位处理,这是他的优点也是他的缺点。
- 首先我们得知道
pom.xml文件他是一个 XML 格式的文件, XML=eXtensible Markup Language 。即是一种可扩展的标记语言。它与 JSON 一样主要用来存储和传输数据。在之前的Springboot章节中我们也实现了如何实现接口传递 XML 数据结构。
常见的 XML 编程接口有 DOM 和 SAX,这两种接口处理 XML 文件的方式不同,当然使用场合也不同。
Python 有三种方法解析 XML,SAX,DOM,以及 ElementTree:
### 1.SAX (simple API for XML ) Python 标准库包含 SAX 解析器,SAX 用事件驱动模型,通过在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件。 ### 2.DOM(Document Object Model) 将 XML 数据在内存中解析成一个树,通过对树的操作来操作XML。 ### 3.ElementTree(元素树)
而我所采用的就是最后一种方式 ElementTree 。
xml.etree.ElementTree
ElementTree在 python3中已经作为标准库存在了,所以这里不需要我们额外的安装。
基于事件和基于文档的APID来解析XML,可以使用XPath表达式搜索已解析的文件,具有对文档的增删改查的功能,该方式需要注意大xml文件,因为是一次性加载到内存,所以如果是大xml文件,不推荐使用该模块解析,应该使用sax方式
不能说最好只能说他是合适的工具,因为 pom.xml 文件不会很大的。ElementTree 通过 XPath 进行节点选择,所以关于xml 节点查找我们可以参考 xpath 语法即可。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.github.zxhTom</groupId>
<artifactId>bottom</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>bottom</name>
<url>http://maven.apache.org</url>
<description>最底层的繁琐封装</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<log4j2.version>2.10.0</log4j2.version>
</properties>
<dependencies>
<!-- 20180927提供了针对stirng bean list 等判断的操作。不用我们在详细的判断了 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.7</version>
</dependency>
<!-- 提供了针对list 等判断的操作。不用我们在详细的判断了 -->
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.1</version>
</dependency>
<!-- jsonobeject jar包依赖 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.28</version>
</dependency>
<!-- 日志记录 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j2.version}</version>
</dependency>
<!-- 通过反射获取标有注解的类 -->
<dependency>
<groupId>org.reflections</groupId>
<artifactId>reflections</artifactId>
<version>0.9.10</version>
</dependency>
</dependencies>
</project>上面的 pom.xml 摘自于 com.github.zxhTom 的 bottom 项目中。里面的恰好出现了注释,方便我们后期测试。
解析xml
import xml.etree.ElementTree as ET
with open('pom.xml', 'tr', encoding='utf-8') as rf:
tree = ET.parse(rf)
print(tree)
- 实际有效的内容就是
ET.parse即可解析出来 xml 。
查看pom.xml所有节点标签名称
import xml.etree.ElementTree as ET
with open('pom.xml', 'tr', encoding='utf-8') as rf:
tree = ET.parse(rf)
# 根据tree进行遍历
for node in tree.iter():
print(node.tag)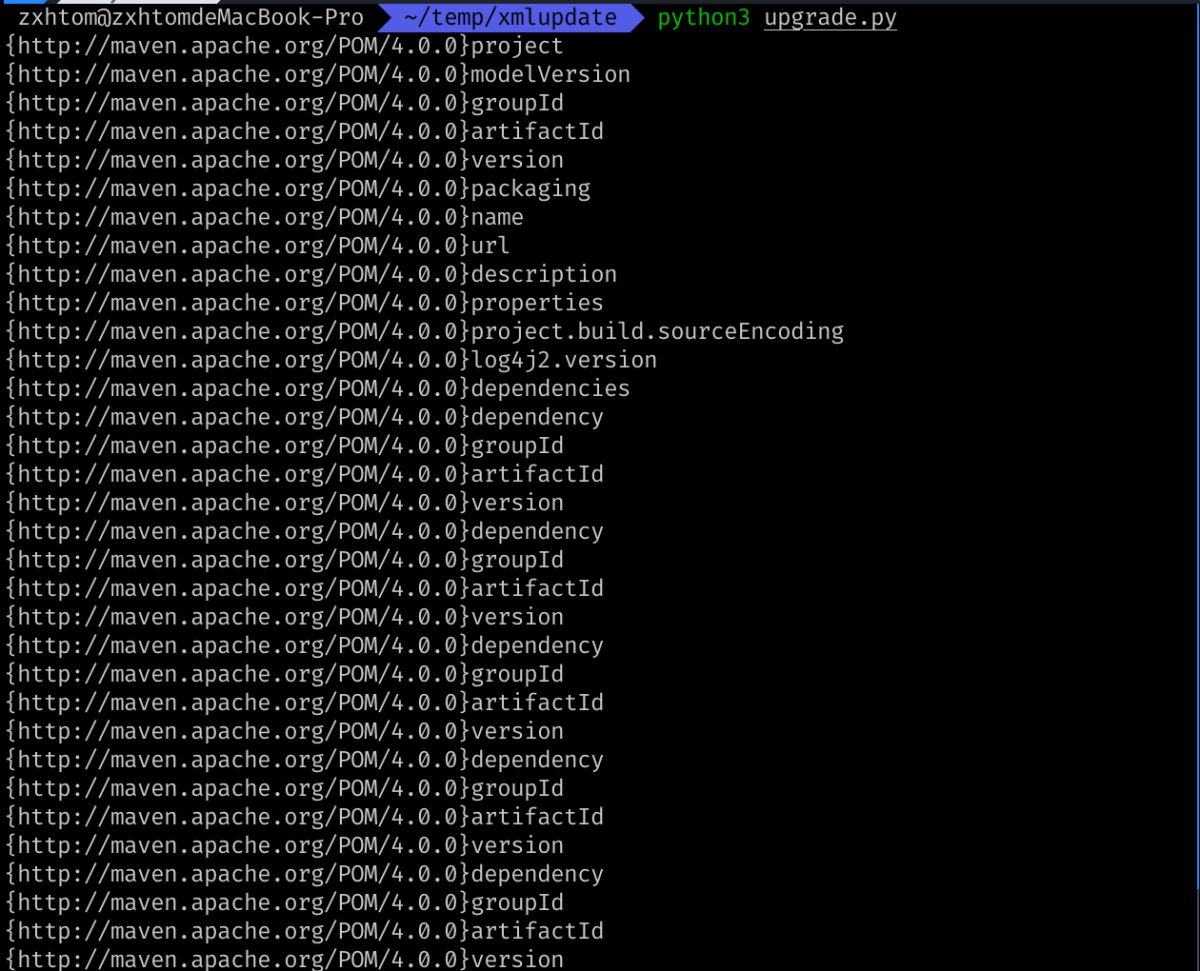
读取xml中dependency我想看下所有的 dependency 标签,只有这样我才能够匹配是否是我需要的那个maven坐标。
import xml.etree.ElementTree as ET
with open('pom.xml', 'tr', encoding='utf-8') as rf:
tree = ET.parse(rf)
# tree遍历
for node in tree.findall('.//dependency'):
print(node.tag)- 上述代码很明显是错误的,因为我们执行脚本后没有任何的输出,至于为什么是这样呢?你可以翻到上一节就可以看到我们在打印所有节点标签名称的时候前面好像都多了一串地址。
- 这个地址就是
pom.xml中的命名空间,在跟节点 project 标签中设置的xmlns属性。至于为什么需要这个呢?每个xml 标签内容都是自定义的,比如你可以将dependency用来做版本号的作用,只要你自己解析的时候注意就行了。而maven中将dependency作为引入坐标的概念,每个人的想法不一,所以引入命名空间,在指定的命名空间中标签的作用是唯一的,这就是xmlns存在的意义。
import xml.etree.ElementTree as ET
with open('pom.xml', 'tr', encoding='utf-8') as rf:
tree = ET.parse(rf)
# tree遍历
for node in tree.findall('.//{http://maven.apache.org/POM/4.0.0}dependency'):
print(node.tag)
读取com.alibaba.fastjson 的版本号
- 通过上面的内容我们知道在定位节点时候需要加入命名空间。
- 首先我们知道
com.alibaba.fastjson的版本号是1.2.28
import xml.etree.ElementTree as ET
with open('pom.xml', 'tr', encoding='utf-8') as rf:
tree = ET.parse(rf)
# tree遍历
for node in tree.findall('.//{http://maven.apache.org/POM/4.0.0}dependency'):
groupIdNode=node.find('.{http://maven.apache.org/POM/4.0.0}groupId')
artifactNode=node.find('.{http://maven.apache.org/POM/4.0.0}artifactId')
if(artifactNode.text=='fastjson' and groupIdNode.text=='com.alibaba'):
print(node.find('.{http://maven.apache.org/POM/4.0.0}version').text)- 通过
python3 upgrade.py即可打印出1.2.28。
保存xml
说了这么多,还记得我们一开始的任务吗,没错就是修改掉pom.xml 中指定jar的版本号。这里就将 com.alibaba.fastjson的版本号升级为1.2.29 吧。
import xml.etree.ElementTree as ET
with open('pom.xml', 'tr', encoding='utf-8') as rf:
tree = ET.parse(rf)
# tree遍历
for node in tree.findall('.//{http://maven.apache.org/POM/4.0.0}dependency'):
groupIdNode=node.find('.{http://maven.apache.org/POM/4.0.0}groupId')
artifactNode=node.find('.{http://maven.apache.org/POM/4.0.0}artifactId')
if(artifactNode.text=='fastjson' and groupIdNode.text=='com.alibaba'):
node.find('.{http://maven.apache.org/POM/4.0.0}version').text='1.2.29'
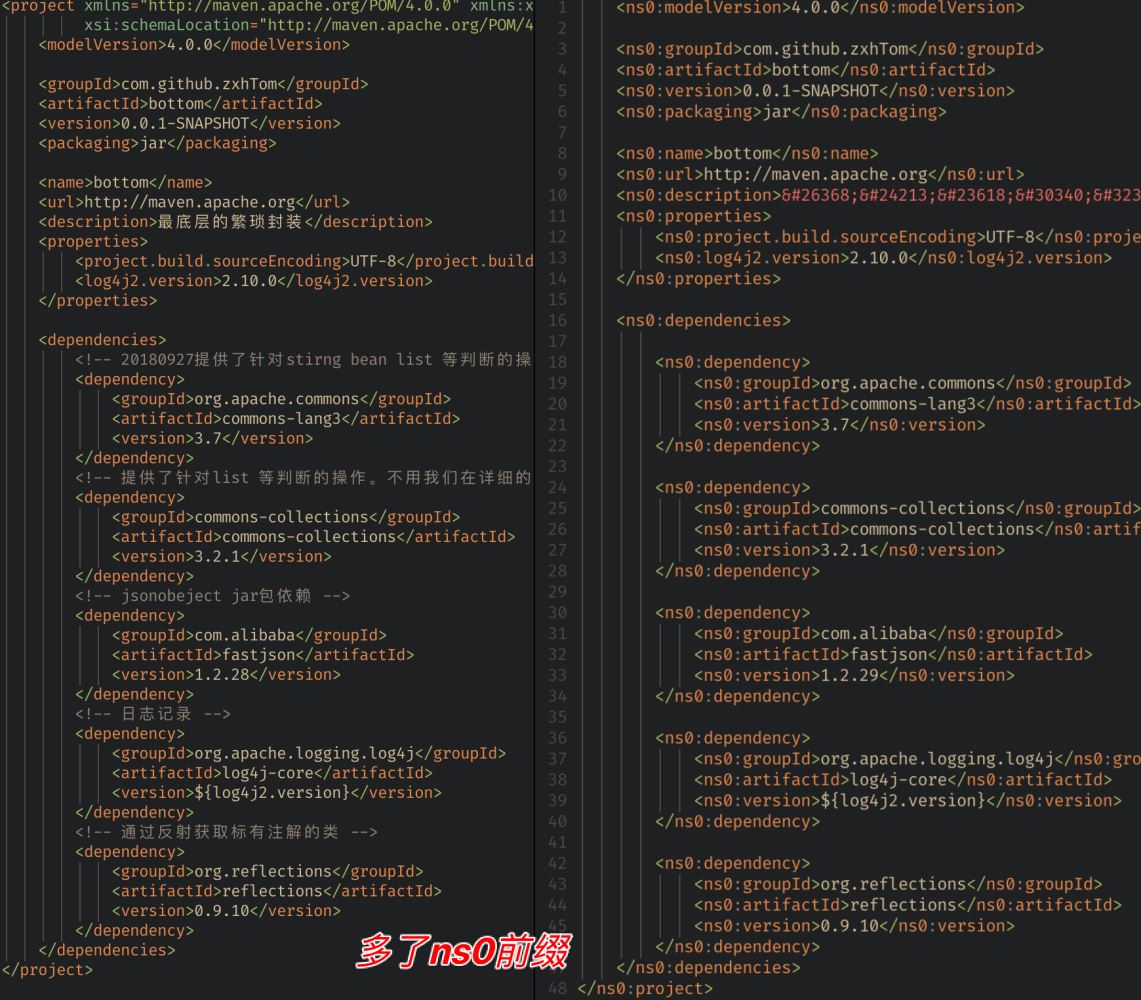
tree.write('pom.xml')- 修改还是很容易的,我们只需要将node.text进行重新赋值就行了。但是经过对比我发现保存后的
pom.xml好像并不是只改了version标签的内容。- 标签多了ns0前缀。
- 中文乱码
- 注释丢失
API追踪
def write(self, file_or_filename,
encoding=None,
xml_declaration=None,
default_namespace=None,
method=None, *,
short_empty_elements=True):上述提到了三个问题都是很常见的问题,因为我们打开 /Lib/xml/etree/ElementTree.py 源码就能够看到在写会 xml 文件的时候我们一共有7个参数可选,其中第一个self 没啥好说的。
| 属性 | 作用 |
|---|---|
| file_or_filename | 文件 |
| encoding | 输出的编码格式;默认US-ASCII |
| xml_declaration | 将XML声明添加到文件中: True添加;False不添加;None在非US-ASCII 或 UTF-8 或 Unicode时添加; 默认None |
| default_namespace | 默认的命名空间 |
| method | xml、 html 、 text。默认 xml |
| short_empty_elements | 空内容的标签时的处理 |
修改xml后节点多了
前缀ns0很明显是我们没有指定输出的默认命名空间导致程序自动生成一个前缀。
tree.write('pom.xml',default_namespace='http://maven.apache.org/POM/4.0.0')当我们指定了命名空间,这个时候再查看下文件节点的前缀问题就解决了。
中文乱码
中文乱码就是我们没有指定编码格式。大家都知道默认的 US-ASCII 都是人家老外的东西,我们国内想正常使用肯定还是需要 UTF-8 的。
tree.write('pom.xml',default_namespace='http://maven.apache.org/POM/4.0.0',encoding='UTF-8')这里我也就不截图了,笔者亲测是可以解决中文乱码的问题的。
标准化xml
这不算个问题,不知道你有没有发现上面我提供的 pom.xml 严格意义上来说不是一个标准的 xml 文件,就好比你上学不带红领巾就不是一个标准学生一样,上面的pom.xml 确实了xml的标准开头申明。不过没关系我们在wirte的时候注意到有一个参数 xml_declaration 就是控制是否生成标准申明的。
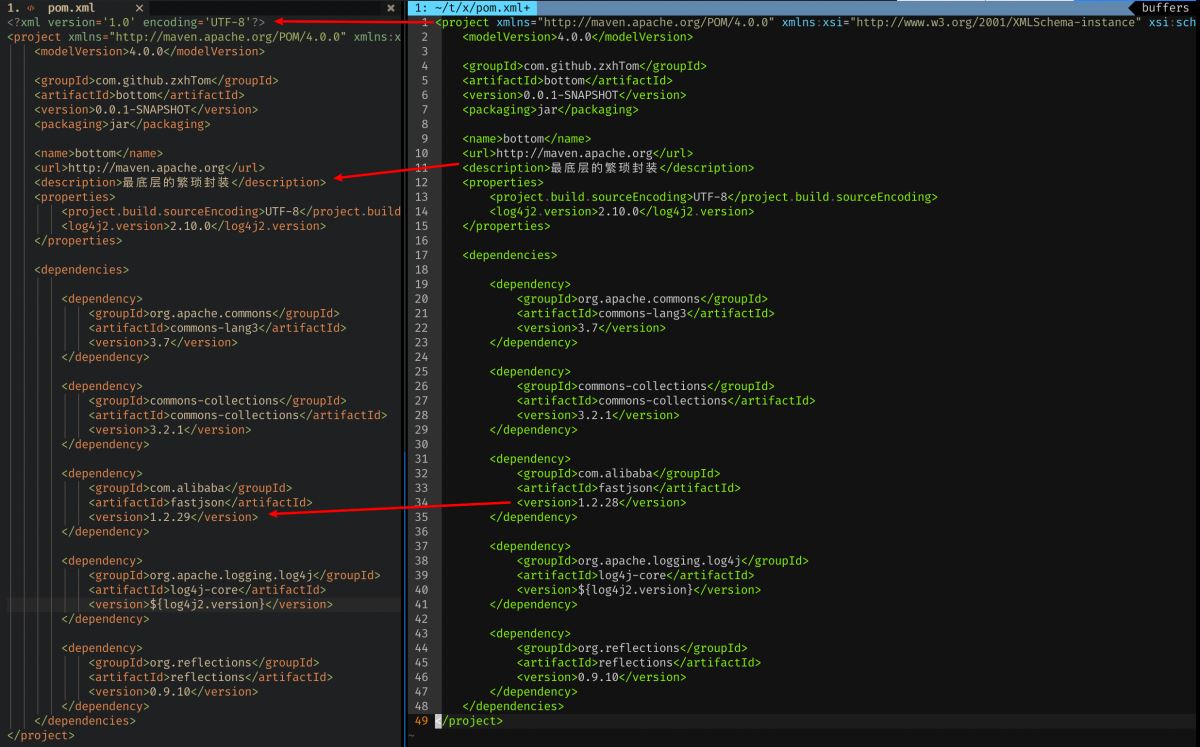
修改xml后原来的注释丢了
关于注释丢了这种问题,怎么说呢?无关紧要吧但是往往注释是进行解释说明的,为了追求完美我还是希望能够将注释保留下来。关于注释的问题我们还得简单查看下源码说明。
with open('pom.xml', 'tr', encoding='utf-8') as rf:
tree = ET.parse(rf)parse 对应的就是 ElementTree 的源码中 parse 中。
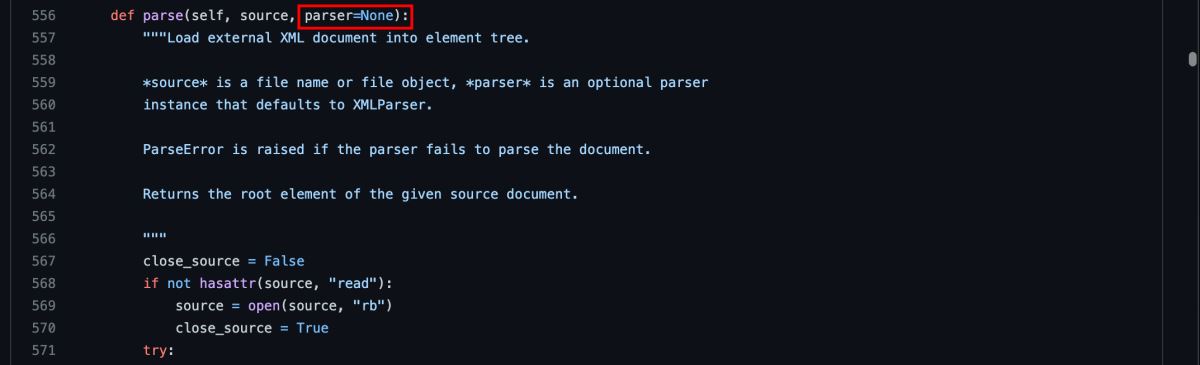



到了这里我们应该不难看出,在渲染的时候主要是通过 TreeBuilder 进行渲染的,其中 CommentHandler 就是 TreeBuilder.comment 进行的。那么我们继续查看下 TreeBuilder 的源码来查看为什么默认的 parser 没有保留下注释。

- 最终就是 _handle_single 方法进行创建节点的,comment中创建节点的工厂类是
_comment_factory, 而这个类就是产生 Comment 。 因为insert_comments=False , 所以默认的TreeBuilder对于注释只会产生一个空的Comment对象,所以我们通过ET.write出来的pom.xml中关于注释部分就是空白代替,就是因为这个原因。 - 到了这里想要保留注释也就变得非常简单了,那么我们只需要修改TreeBuilder就可以了。
class CommentedTreeBuilder (ET.TreeBuilder):
def comment(self,data):
self.start(ET.Comment,{})
self.data(data)
self.end(ET.Comment)- 上述代码类似于 Java中继承了 TreeBuilder 并且重写了 comment方法。主要的逻辑就是开头一个注释标签属性为空,结尾是一个注释标签结尾,中间的内容是我们注释的内容,所以综上就是保留下来注释。
- 重写了类之后我们还需要在ET中指定我们自定义的TreeBuilder 。
parser = ET.XMLParser(target=CommentedTreeBuilder()) tree = ET.parse(xml_path,parser=parser)
- 构建好tree之后其他就是一样的操作,最终倒出来的文件就是我们保留注释的xml 了。
获取不到子节点
就的版本是 getchildren , 但是在新版本中直接废弃了这个方法。而在新版本中是通过 iter(tag) 进行创建迭代器的。但tag=None或者 * 表示所有子孙节点,其他的情况就只查找指定tag 名称的集合。
优雅解析带命名空间的xml
还记得我们是如何解析获取到 pom.xml 中的标签的。
# tree遍历
for node in tree.findall('.//{http://maven.apache.org/POM/4.0.0}dependency'):
print(node.tag)这种方式我只想说NO , 每次在通过xpath 定位节点都需要添加前缀,这简直是个噩梦。
ns = {'real_mvn': 'http://maven.apache.org/POM/4.0.0',
'vistual': 'http://characters.zxhtom.com'}
# tree遍历
for node in tree.findall('.//real_mvn:dependency',ns):
print(node.tag)总结
- 本文主要是通过脚本实现pom.xml 的版本升级功能。SHELL通过三剑客定位到指定坐标进行版本更新,缺点是可能不兼容注释同内容的坐标,优点是修改内容范围小,不会造成大影响
- 而python实现的xml文件修改。他的优点是能够精准定位不会产生错误定位问题且支持注释内容保留,缺点是不适合操作大文件。
| 文件 | dependency数量 |
|---|---|
| knife4j-spring-ui-1.9.6.pom | 0 |
| spring-context-support-1.0.6.pom | 3 |
| spring-core-5.1.7.RELEASE.pom | 10 |
| springfox-swagger-common-3.0.0.pom | 11 |
其他说明
参考文章
加载全部内容