Redis ZSet使用
北极星小王子 人气:0一、题目
ZSet能用在哪些场景?跳表查找的过程,时间复杂度
二、ZSet 简单使用
举个例子,fruit-price 是一个有序集合键,这个有序集合以水果名为成员,水果价钱为分值,保存了 130 款水果的价钱:
redis>ZADD fruit-price 5 "banana" redis>ZADD fruit-price 6.5 "cherry" redis>ZADD fruit-price 8 "apple" redis> ZRANGE fruit-price 0 2 WITHSCORES 1) "banana" 2) "5" 3) "cherry" 4) 6.5 5) "apple" 6) "8" redis> ZCARD fruit-price (integer)130
三、ZSet 结构
ZSet 结构即支持单个元素查询,又支持范围查询,是如何实现的呢?
Redis 中有两种数据结构来支持 ZSet 的功能,一个是字典 dict ,一个是 zskipList; 字典保存着从 member 到 score 的映射,跳跃表按 score 从小到大保存所有集合元素
先看下 ZSet 在代码中的定义:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
dict 各种编程语言中都有实现。可以保证 O(1) 的时间复杂度; 我们继续看 zskiplist 的定义:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
zskiplist 是 Redis 对 skiplist 做了变种,skiplist 就是我们常说的跳表;
四、跳跃表
跳跃表的特点
- 由许多层结构组成,每层都是一个有序链表
- 最底层的链表包含所有元素
- 如果一个元素出现在 level i 层的链表中,则它在 level i 之下的链表中也都会出现
- 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素
查找过程
- 跳表的查找会从顶层链表的头部元素开始遍历该链表,直到找到元素大于或等于目标元素的节点,如果当前元素正好等于目标,那么就直接返回它;
- 如果当前元素大于目标或到达链表尾部,则移动到前一个节点的位置,然后垂直下降到下一层;
- 正因为 Skiplist 的搜索过程会不断地从一层跳跃到下一层的,所以被称为跳跃表;
举例说明
假设链接包含 1-10,共 10 个元素。我们要找到第 9 个,需要从 header 遍历,共 9 次才能找到:
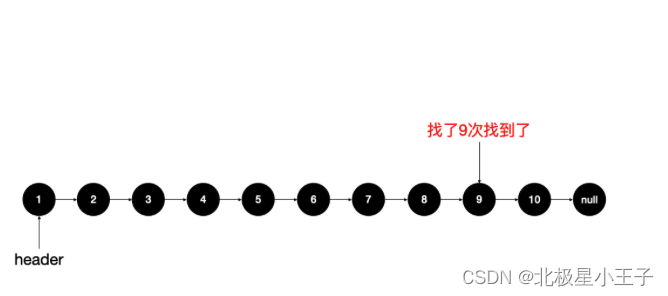
一次只能比较一个数,最坏的情况下时间复杂度是 O(n),如果我们一次可以比较 2 个元素就好了:
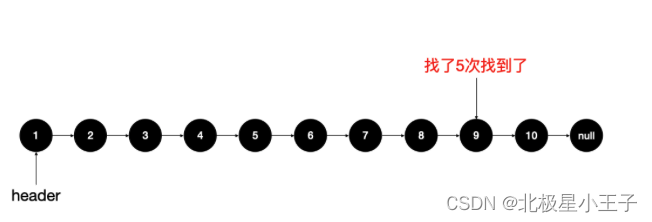
一次查找 2 个的话,我们只找了 5 次就找到了。所以就有了类似下面的结构,在链表上增加一层减少了元素个数的 “链表”:
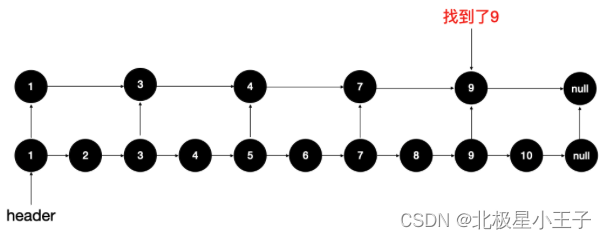
如果增加两层 “链表”,只查找 3 次就可以找到:
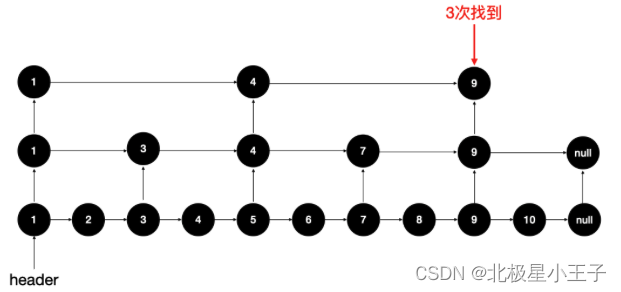
即便是我们找元素 8,也只需要遍历 1 -> 4 -> 7 -> 8,共 4 次查询;
这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到 O(log n)
ZskipList 插入过程:
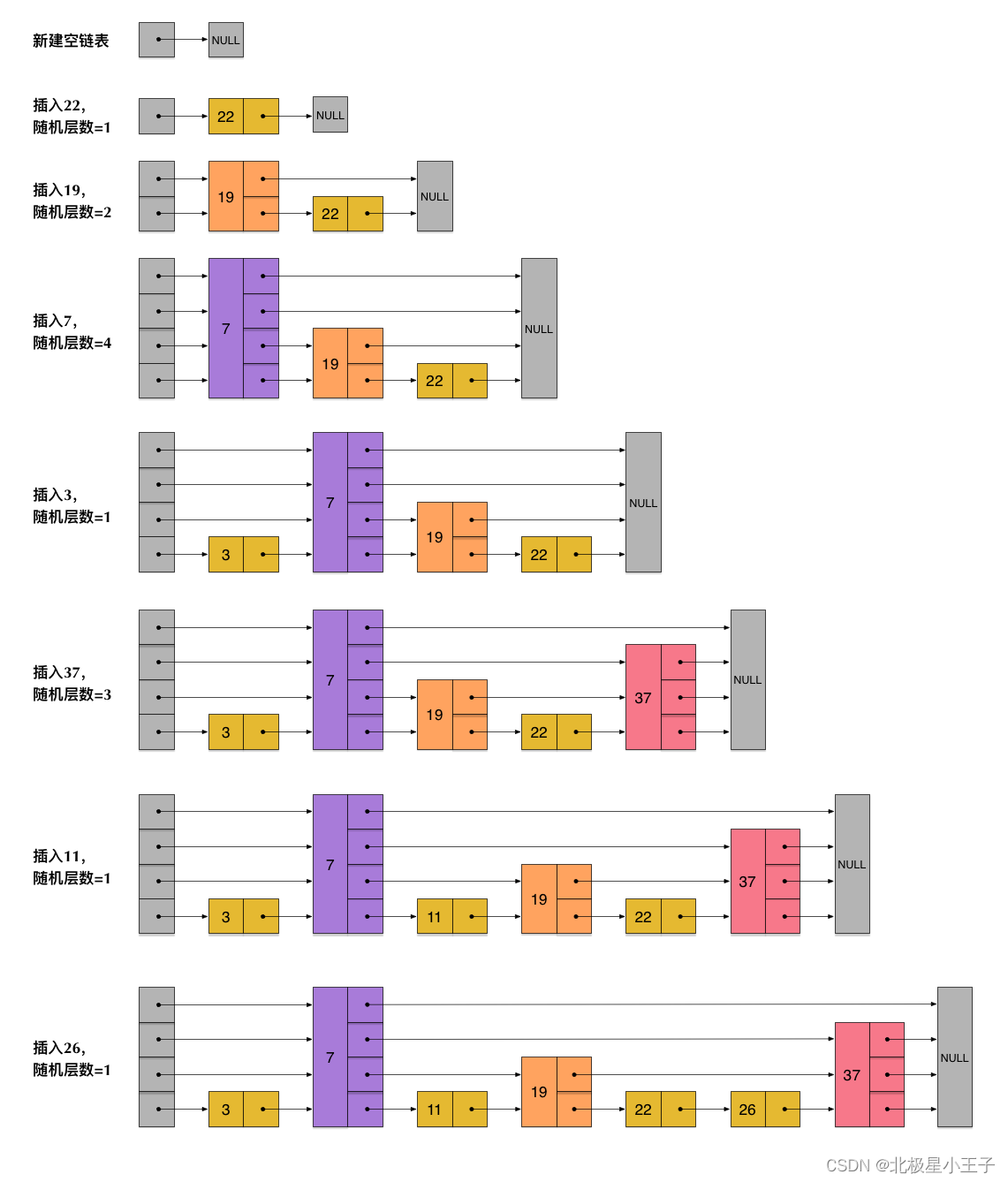
从上面 Skiplist 的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。 因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度
Redis 初始化的时候,只判断存储的元素长度是否大于 64 个字节。大于 64 个字节选择 Zkiplist,否则 Ziplist。当执行增删改查的方法,根据是 ziplist 还是 zkiplist 选择不同的实现。只需要记住 zset,在两种情况下使用 ziplist:
保存的元素个数不足 128 个;单个元素的大小超过 64 byte;
ziplist 编码的有序集合使用紧挨在一起的压缩列表节点来保存,第一个节点保存 member,第二个保存 score。ziplist 内的集合元素按 score 从小到大排序,score 较小的排在表头位置
为什么采用跳跃表
- 跳表就是这样的一种数据结构,结点是跳过一部分的,从而加快了查询的速度。类似于 HashMap 中,Java 8 中当哈希冲突个数大于 7 个的时候,转换为红黑树;
- 跳表跟红黑树两者的算法复杂度差不多,为什么 Redis 要使用跳表而不使用红黑树呢?跳表相对于红黑树,代码简单;
- 如果我们要查询一个区间里面的值,用平衡树实现可能会麻烦。删除一段区间时,如果是平衡树,就会相当困难,毕竟涉及到树的平衡问题,而跳表则没有这种烦恼;
五、场景案例
1、信息统计
假设我们有某个班级所有学生的语文成绩,想统计、查询区间范围、查询单个学生成绩、满足高性能读取这些需求, Redis 的 zset 结构无疑是最好的选择。Redis 提供了丰富的 API。示例
ZADD yuwen 90 s01 89 s03 99 s02 74 s04 97 s05
以 yuwen 为 key 分别存储了 s01 到 s06 共计 6 名学生的分数,我们可以查询任一学生的成绩:
ZSCORE yuwen s03
可以按照排序返回指定区间内的所有元素
ZRANGE yuwen 1 2 withscores
可以访问指定分数区间内的所有元素
ZRANGEBYSCORE yuwen 90 100 withscores
可以统计指定区间内的个数
ZCOUNT yuwen 80 90
2、排行榜
- 经常浏览技术社区的话,应该对 “1小时最热门” 这类榜单不陌生。如何实现呢?如果记录在数据库中,不太容易对实时统计数据做区分;
- 我们以当前小时的时间戳作为 zset 的 key,把贴子 ID 作为 member ,点击数评论数等作为 score,当 score 发生变化时更新 score;
- 利用 ZREVRANGE 或者 ZRANGE 查到对应数量的记录;
加载全部内容