python操作XML文件
荼靡, 人气:0前言
可扩展标记语言,是一种简单的数据存储语言,XML被设计用来传输和存储数据
- 存储,可用来存放配置文件,例:java配置文件
- 传输,网络传输以这种格式存在,例:早期ajax传输数据等
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2026</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
1. 读取文件和内容
#导包
from xml.etree import ElementTree as ET
# ET去打开xml文件
tree = ET.parse("files/xo.xml")
# 获取根标签
root = tree.getroot()
print(root) # <Element 'data' at 0x7f94e02763b0>
2.读取节点数据
获取根标签
root = ET.XML(content)
查找节点【默认找第一个】 find()
country_object = root.find("country")
print(country_object) #<Element 'country' at 0x0000020D57DFB220>
获取节点标签 tag
country_object.tag #country
获取节点属性 attrib
country_object.attrib #{'name': 'Liechtenstein'}
获取节点文本 text
gdppc_object.text #141100
循环节点
# 获取data标签的孩子标签
for child in root:
print(child.tag, child.attrib)
#获取child标签的孩子标签
for node in child:
print(node.tag, node.attrib, node.text)
查找所有标签 iter()
# 获取data里面所有year标签
for child in root.iter('year'):
print(child.tag, child.text)
查找所有标签 findall()
# 查找所有的country标签
v1 = root.findall('country')
查找标签
# 查找country里面的rank标签,找第一个
v2 = root.find('country').find('rank')
3.修改和删除节点
【修改和删除内容只在内存中修改,没有存到文件中,都要重新保存文件】
修改节点内容
#修改rank文本
rank.text = "999"
tree = ET.ElementTree(root)
tree.write("new.xml", encoding='utf-8')
修改节点属性
#修改rank属性
rank.set('update', '2020-11-11')
tree = ET.ElementTree(root)
tree.write("new.xml", encoding='utf-8')
保存文件
tree = ET.ElementTree(root)
tree.write("new.xml", encoding='utf-8')
删除节点
root.remove( root.find('country') )
tree = ET.ElementTree(root)
tree.write("new.xml", encoding='utf-8')
4.构建文档 方式一ET.Element()
<home>
<son name="儿1">
<grandson name="儿11"></grandson>
<grandson name="儿12"></grandson>
</son>
<son name="儿2"></son>
</home>
from xml.etree import ElementTree as ET
#创建根标签
root=ET.Element('home')
# 创建大儿子,与root还没有关系
son1=ET.Element('son',{'name':'儿1'})
#创建小儿子,与root还没有关系
son2=ET.Element('son',{'name':'儿2'})
#创建2个孙子
grandson1=ET.Element('grandson',{'name':'儿11'})
grandson2=ET.Element('grandson',{'name':'儿12'})
# 创建两个孙子,与son1还没有关系
son1.append(grandson1)
son1.append(grandson2)
# 把儿子添加到根节点
root.append(son1)
root.append(son2)
#root节点放到根节点中
tree=ET.ElementTree(root)
#保存xml文件
# short_empty_elements=True,节点中没有元素,用简写方式显示例:<grandson name="儿11" />
tree.write('file/root.xml',encoding='utf-8',short_empty_elements=True)
方式二 标签.makeelement()
<famliy>
<son name="儿1">
<grandson name="儿11"></grandson>
<grandson name="儿12"></grandson>
</son>
<son name="儿2"></son>
</famliy>
from xml.etree import ElementTree as ET
# 创建根节点
root = ET.Element("famliy")
# 创建大儿子,与root还没有关系
son1 = root.makeelement('son', {'name': '儿1'})
#创建小儿子,与root还没有关系
son2 = root.makeelement('son', {"name": '儿2'})
# 创建两个孙子,与son1还没有关系
grandson1 = son1.makeelement('grandson', {'name': '儿11'})
grandson2 = son1.makeelement('grandson', {'name': '儿12'})
son1.append(grandson1)
son1.append(grandson2)
# 把儿子添加到根节点中
root.append(son1)
root.append(son2)
tree = ET.ElementTree(root)
tree.write('oooo.xml',encoding='utf-8')
方式三 标签.SubElement(),创建标签的子标签
<famliy>
<son name="儿1">
<age name="儿11">孙子</age>
</son>
<son name="儿2"></son>
</famliy>
from xml.etree import ElementTree as ET
# 创建根节点
root = ET.Element("famliy")
# 创建root节点的子标签大儿子
son1 = ET.SubElement(root, "son", attrib={'name': '儿1'})
# 创建root节点的子标签小儿子
son2 = ET.SubElement(root, "son", attrib={"name": "儿2"})
# 在大儿子中创建一个孙子
grandson1 = ET.SubElement(son1, "age", attrib={'name': '儿11'})
grandson1.text = '孙子'
et = ET.ElementTree(root) #生成文档对象
et.write("test.xml", encoding="utf-8")
方式四
<user><![CDATA[你好呀]]</user>
from xml.etree import ElementTree as ET
# 创建根节点
root = ET.Element("user")
#<![CDATA[你好呀]]直接添加到文本里
root.text = "<![CDATA[你好呀]]"
et = ET.ElementTree(root) # 生成文档对象
et.write("test.xml", encoding="utf-8")
补充:XML文件和JSON文件互转
记录工作中常用的一个小技巧
cmd控制台安装第三方模块:
pip install xmltodict
1、XML文件转为JSON文件
新建一个1.xml文件:
<note date="23/04/2022">
<to>tom</to>
<from>mary</from>
<msg>love</msg></note>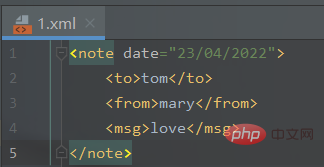
转换代码实现:
import jsonimport xmltodictdef xml_to_json(xml_str):
"""parse是的xml解析器,参数需要
:param xml_str: xml字符串
:return: json字符串
"""
xml_parse = xmltodict.parse(xml_str)
# json库dumps()是将dict转化成json格式,loads()是将json转化成dict格式。
# dumps()方法的ident=1,格式化json
json_str = json.dumps(xml_parse, indent=1)
return json_str
XML_PATH = './1.xml' # xml文件的路径with open(XML_PATH, 'r') as f:
xmlfile = f.read()
with open(XML_PATH[:-3] + 'json', 'w') as newfile:
newfile.write(xml_to_json(xmlfile))
输出结果(生成json文件):
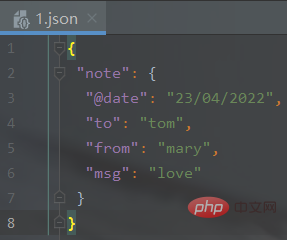
2、JSON文件转换为XML文件
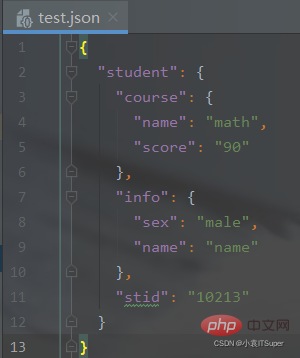
新建test.json文件:
{
"student": {
"course": {
"name": "math",
"score": "90"
},
"info": {
"sex": "male",
"name": "name"
},
"stid": "10213"
}}
转换代码实现:
import xmltodictimport jsondef json_to_xml(python_dict):
"""xmltodict库的unparse()json转xml
:param python_dict: python的字典对象
:return: xml字符串
"""
xml_str = xmltodict.unparse(python_dict)
return xml_str
JSON_PATH = './test.json' # json文件的路径with open(JSON_PATH, 'r') as f:
jsonfile = f.read()
python_dict = json.loads(jsonfile) # 将json字符串转换为python字典对象
with open(JSON_PATH[:-4] + 'xml', 'w') as newfile:
newfile.write(json_to_xml(python_dict))
输出结果(生成xml文件):
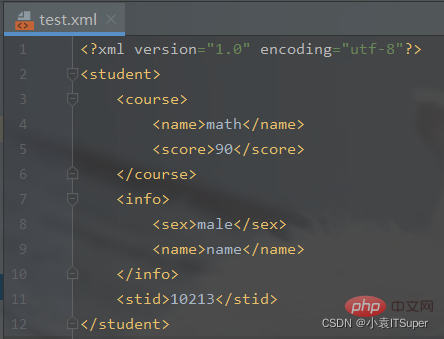
总结
加载全部内容