Shell脚本讲解
大家好,我是好同学 人气:0一、Shell脚本基础概念
1.1 什么是shell?
shell英文翻译过来是外壳的意思,作为计算机语言来理解可以认为它是操作系统的外壳。我们可以通过shell命令来操作和控制操作系统,比如Linux中的shell命令就包括ls、cd、pwd等等。
shell是站在内核的基础上编写的一个应用程序,它连接了用户和Linux内核,从而让用户能够更加便捷、高效、安全的使用linux内核,这其实就是shell的本质。
使用专业术语的说法来解释,Shell其实是一个命令解释器,它通过接受用户输入的Shell命令来启动、暂停、停止程序的运行或对计算机进行控制。
1.2 什么是shell脚本
shell脚本就是由Shell命令组成的执行文件,将一些命令整合到一个文件中,进行处理业务逻辑,脚本不用编译即可运行。它通过解释器解释运行,所以速度相对来说比较慢。
1.3 shell脚本的意义
我们在1.2中也解释道shell脚本其实就是shell命令组成的文件,shell脚本可以记录命令执行的过程和执行逻辑,以便以后重复执行,还可以批量、定时处理主机,方便管理员进行设置或者管理。
二、创建一个简单的Shell脚本
2.1 创建一个shell脚本文件
在创建shell脚本时,我们默认新建一个以.sh/.script结尾的文件,主要是为了让程序员更加快捷的辨认出该文件是一个shell脚本文件。
我们创建一个test.sh的shell脚本文件,其中具体内容为下:
#!/bin/bash echo hello
- " # ”开头的就是注释,单行注释
- <<EOF … EOF 或 :<<! … ! :多行注释
- #!/bin/bash : 主要用于指定解释器
- Linux中提供的shell解释器有:
- /bin/sh
- /bin/bash
- /usr/bin/sh
- /usr/bin/bash
2.2 运行一个Shell脚本
我们根据脚本文件是否具有可执行权限,将运行一个shell脚本的方法分为两大类。
2.2.1 脚本文件无执行权限
这种情况下我们有三种方式来运行脚本:
手动在环境中开启指定解释器:sh test.sh

直接在当前环境中运行的shell中运行脚本:. test.sh

直接在当前环境中运行的shell中运行脚本:source test.sh

2.2.2 脚本文件有执行权限
在这一部分由于我们假设脚本文件有可执行器权限,所以我们使用chmod +x test.sh为我们的test.sh文件增加了可执行权限。
我们知道当一个文件具有可执行权限时我们可以使用该文件的路径名直接运行该文件,有两种方式可以运行脚本:
1.绝对路径名运行脚本文件
绝对路径就是从根目录下开始记录文件路径名,是文件在计算机上真正存在的路径。(如果不知道你的文件路径名,可以在当前位置的shell中使用pwd查询当前所在位置)

2../相对路径名的格式运行脚本文件
相对路径是指以当前的文件作为起点,相较于当前目录的位置而被指向并且加以引用的文件资源。
比如我们知道test.sh文件的绝对路径为/home/westos/Desktop/textcpp/test.sh,那么当我们在testcpp文件夹中时,test.sh文件的相对路径为test.sh。
又因为.代表当前所在位置,故而为其实./test.sh其实就是该文件的绝对路径,只是表示的方式不同。

三、基本语法
3.1 变量
变量名其实就是一片内存区域的地址或者可以说是寻址符号,有了变量我们就可以使用一串固定的字符来表示不固定的目标。
3.1.1 变量类型
在shell中会同时存在三种类型变量。
- 局部变量:局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
- 环境变量:所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
- shell变量:shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
3.1.2 变量操作
- 创建普通变量:name=“test”,组要注意的是等号两边不能有空格。
- 创建局部变量:local name=“test”,使用local修饰的变量在函数体外无法访问,只能在函数体中使用。
- 创建只读变量:name=“only_read” -> readonly name,这种变量不可以被修改。
- 使用变量:echo $name或者echo ${name}
- 删除变量:unset name,删除之后的变量无法被访问,需要注意无法删除只读变量。
3.1.3 字符串变量
3.1.3.1 字符串变量的创建
- 使用单引号创建:var='test'。
这种方式创建的变量只能原样输出,变量无效,我们可以借用c中的“字符串常量”的定义理解这种特性。除此以外,单引号中不能出现单独的单引号,转义也是不可以的。 - 使用双引号创建:var="my name is ${name}",这种方式创建的字符串变量有效,也可以出现转义符。
3.1.3.2 拼接字符串
- 字面量拼接
str01="1""2"或者str01="1"'2',这样就将1和2两个字符拼接在了一起。需要注意的是两个串之间不可以有空格。 - 变量拼接
str03=${part01}${part02}或str04=${part01}"end"或str05="${part01} ${part02}"这三种方式都可以拼接字符串变量。 - 命令拼接
str02= date“end”,这里的date是一个shell命令,需要使用引用,具体如下:
str02=`date`"end"
3.1.3.3 获取字符串长度
1.使用wc -L命令
wc -L可以获取到当前行的长度,因此对于单独行的字符串可以用这个简单的方法获取,另外wc -l则是获取当前字符串内容的行数。
echo "abc" |wc -L
2.使用expr length可以获取string的长度
expr length ${<!--{C}%3C!%2D%2D%20%2D%2D%3E-->str}3.awk获取域的个数
但是如果大于10个字符的长度时是否存在问题需要后面确认
echo "abc" |awk -F "" '{print NF}'4.通过awk+length的方式获取字符串长度
echo “Alex”|awk '{print length($0)}'5.通过echo ${#name}的方式
name=Alex
echo ${#name}
3.1.3.4 提取子字符串
1.如下方式:
| 代码 | 意义 |
|---|---|
| ${varible##*string} | 从左向右截取最后一个string后的字符串 |
| ${varible#*string} | 从左向右截取第一个string后的字符串 |
| ${varible%%string*} | 从右向左截取最后一个string后的字符串 |
| ${varible%string*} | 从右向左截取第一个string后的字符串 |
例,如下代码:
$ MYVAR=foodforthought.jpg
$ echo ${MYVAR##*fo}
运行结果为rthought.jpg
2.使用${varible:n1:n2}
截取变量varible从n1到n2之间的字符串,可以根据特定字符偏移和长度,来选择特定子字符串,如下代码:
$ EXCLAIM=cowabunga
$ echo ${EXCLAIM:0:3}
运行结果最终显示cow。
3.1.4 数组
如果说变量是存储单个变量的内存空间,那么数组就是多个变量的集合,它存储多个元素在一片连续的内存空间中。在bash中,只支持一维数组,不支持多维数组。
3.1.3.1 数组定义与引用
定义一个数组方式如下:
数组名=(元素1 元素2 元素3 ... 元素n)
指定数组对应下标的元素进行赋值:
数组名[下标]=值
同时指定多个数组元素进行赋值:
数组名=([下标1]=值1 [下标2]=值2 ... [下标n]=值n)
引用数组对应下标的元素:
${数组名[下标]}
3.1.3.2 遍历数组元素
使用for(或while循环)循环遍历数组元素:
#!/bin/bash
a=(1 2 3 4 5 6)
for((i=0; i<10; i++))
do
echo "a[$i]=${a[$i]}"
done
除此以外我们还可以使用${a[*]}或者${a[@]}来遍历数组元素,具体代码如下:
#!/bin/bash
a=(1 2 3 4 5 6)
echo ${a[*]}
echo ${a[@]}3.1.3.3 获取数组长度
我们可以使用#来获取数组长度,需要注意的是在shell脚本中我们越界访问数组时是不会报错的。
#!/bin/bash
a=(1 2 3 4 5 6)
echo ${a[*]}
echo "a len: ${#a[*]}"
我们先使用其获取数组中的元素后使用#获取元素个数即可。
3.1.3.4 合并数组
我们可以如下进行拼接:
#!/bin/bash
a=(1 2 3 4 5 6)
b=("hello" "zhaixue.cc")
c=(${a[*]} ${b[*]})
这样我们就将两个数组拼接起来了。
3.1.3.5 删除数组元素
如果我们想要删除某个数组元素,具体代码如下:
#!/bin/bash
a=(1 2 3 4 5 6)
echo ${a[*]}
echo "a len: ${#a[*]}"
unset a[5]
echo ${a[*]}
echo "a len: ${#a[*]}"
执行结果如下:
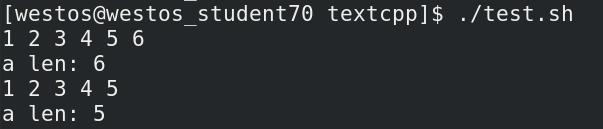
我们如果要删除整个数组,可以执行unset a,举例代码如下:
#!/bin/bash
a=(1 2 3 4 5 6)
echo ${a[*]}
echo "a len: ${#a[*]}"
unset a
echo ${a[*]}
echo "a len: ${#a[*]}"
3.1.5 变量传参
相关的变量含义为:
| 变量 | 含义 |
|---|---|
| $0 | 代表执行的文件名 |
| $1 | 代表传入的第1个参数 |
| $n | 代表传入的第n个参数 |
| $# | 参数个数 |
| $* | 以一个单字符串显示所有向脚本传递的参数。 |
| $@ | 与$*相同,但是使用时加引号,并在引号中返回每个参数 |
| $$ | 脚本运行的当前进程号 |
| $! | 后台运行的最后一个进程的ID |
| $? | 显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误。 |
3.2 运算符
原生的bash并不支持简单的数学运算,通常要通过其它命令来实现。
3.2.1 算数运算符
以下表格中的a和b都是变量。
| 运算 | shell中格式 |
|---|---|
| 加法 | expr $a + $b |
| 减法 | expr $a - $b |
| 乘法 | expr $a \* $b |
| 除法 | expr $b / $a |
| 取余 | expr $b % $a |
| 赋值 | a=$b |
| 相等 | [ $a == $b ] |
| 不相等 | [ $a != $b ] |
需注意:
条件表法式需要放在方括号之间,并且要有空格。使用expr进行计算时需要使用反引号,为了让读者更容易理解,给出下列示例代码。
#!/bin/bash a=10 b=20 val=`expr $a + $b` echo "a + b : $val"
3.2.2 关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
| 运算 | shell中的实现 | 主要符号 |
|---|---|---|
| 检测两个数是否相等 | [ $a -eq $b ] | -eq |
| 检测两个数是否不相等 | [ $a -ne $b ] | -ne |
| 检测左边的数是否大于右边的 | [ $a -gt $b ] | -gt |
| 检测左边的数是否小于右边的 | [ $a -lt $b ] | -lt |
| 检测左边的数是否大于等于右边的 | [ $a -ge $b ] | -ge |
| 检测左边的数是否小于等于右边的 | [ $a -le $b ] | -le |
举例代码如下:
#!/bin/bash a=1 b=2 if [ $a != $b ] then echo "$a != $b : a 不等于 b" else echo "$a == $b: a 等于 b"
执行结果如下:

3.2.3 布尔运算符
具体如下:
| 运算 | shell中的实现 | 主要符号 |
|---|---|---|
| 非运算 | [ ! false ] | ! |
| 或运算 | [ $a -lt 20 -o $b -gt 100 ] | -o |
| 与运算 | [ $a -lt 20 -a $b -gt 100 ] | -a |
3.2.4 逻辑运算符
具体如下:
| 运算 | shell中的实现 | 主要符号 |
|---|---|---|
| 逻辑的 AND | [[ $a -lt 100 && $b -gt 100 ]] | && |
| 逻辑的 OR | [[ $a -lt 100 || $b -gt 100 ]] | || |
布尔运算符和逻辑运算符的区别:
语法上,逻辑运算需要双括弧,布尔运算只需要单大括弧功能上,逻辑运算具有特殊的短路功能,即是在AND运算中第一个表达式为false时则不执行第二个表达式,在OR运算中第一个表达式为true时不执行第二个表达式。
3.2.5 字符串运算符
下表列出了常用的字符串运算符:
| 运算 | shell中的实现 | 主要符号 |
|---|---|---|
| 检测两个字符串是否相等 | [ $a = $b ] | = |
| 检测两个字符串是否不相等 | [ $a != $b ] | != |
| 检测字符串长度是否为0 | [ -z $a ] | -z |
| 检测字符串长度是否不为 0 | [ -n “$a” ] | -n |
| 检测字符串是否为空 | [ $a ] | $ |
3.2.6 文件测试运算符
主要用于检测unix文件的各种属性:
| 运算 | shell中的实现 | 主要符号 |
|---|---|---|
| 检测文件是否是块设备文件 | [ -b $file ] | -b file |
| 检测文件是否是字符设备文件 | [ -c $file ] | -c file |
| 检测文件是否是目录 | [ -d $file ] | -d file |
| 检测文件是否是普通文件(既不是目录,也不是设备文件) | [ -f $file ] 返回 true | -f file |
| 检测文件是否设置了 SGID 位 | [ -g $file ] | -g file |
| 检测文件是否设置了粘着位(Sticky Bit) | [ -k $file ] | -k file |
| 检测文件是否是有名管道 | [ -p $file ] | -p file |
| 检测文件是否设置了 SUID 位 | [ -u $file ] | -u file |
| 检测文件是否可读 | [ -r $file ] | -r file |
| 检测文件是否可写 | [ -w $file ] | -w file |
| 检测文件是否可执行 | [ -x $file ] | -x file |
| 检测文件是否为空(文件大小是否大于0) | [ -s $file ] | -s file |
| 检测文件(包括目录)是否存在 | [ -e $file ] | -e file |
举例如下:
#!/bin/bash file="/home/westos/Desktop/textcpp/test.sh" if [ -r $file ] then echo "文件可读" else echo "文件不可读" fi
执行结果为:

3.2.7 运算指令
1.(( ))
我们可以直接使用双圆括弧计算其中的内容,如((var=a+b)),该指令经常在if/while等条件判断中需要计算时使用。
2.let
在计算表达式的时候我们可以直接使用let,如let var=a+b。
3.expr
在前面的内容中我们也提到了它,是非常常用的计算指令,使用时需要在外部增反引号
var=`expr a+b`
4.bc计算器
bc计算器支持shell中的小数进行运算,并且可以交互式或者非交互式的使用。基本使用方式为var=$(echo "(1.1+2.1)"|bc);
5.$[]
我们可以直接使用这种方式计算中括弧中的内容,如echo $[1+2]
3.3 控制语句
和其他语句不同,shell的流传呢个控制不可为空。接下来我们为大家介绍sehll中常用的语法。
3.3.1 if语句结构
3.3.1.1 if-fi
就类似于c中的if条件判断,如下:
if condition
then
command1
command2
...
commandN
fi
3.3.1.2 if-else-fi
代码如下:
if condition
then
command1
else
command2
fi
若condition成立则执行command1,否则执行command2。
3.3.1.3 if else-if else
代码如下:
if condition1
then
command1
elif condition2
then
command2
else
command3
fi
若condition1成立,执行command1,若condition1不成立,condition2成立执行command2,若两个condition都不成立就执行command3。
3.3.2 循环结构
3.3.2.1 for循环
格式为:
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
done
以上也可以写做一行,若变量var在列表中,则for循环执行一次所有命令。以以下代码作为测试:
#!/bin/bash
for loop in 1 2 3 4 5
do
echo "The value is: $loop"
done
执行结果为:
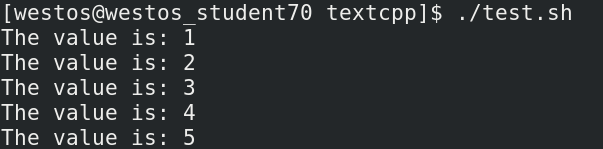
3.3.2.2 while循环
格式如下:
while condition
do
command
done
我们运行如下代码:
#!/bin/bash
int=1
while(( $int<=5 ))
do
echo $int
let "int++"
done
执行的最终结果为:
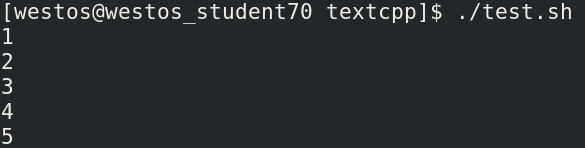
3.3.2.3 无限循环
我们可以以上两种语句给出无限循环的实现,首先看一下for循环如何实现:
for (( ; ; ))
除此以外我们也可以使用while循环实现如下:
while :
do
command
done
或者直接将while中的判断语句置为真:
while true
do
command
done
3.3.2.4 until循环
until 循环执行一系列命令直至条件为 true 时停止。语法格式如下:
until condition
do
command
done
3.3.2.5 跳出循环
在循环过程中,有时候需要在未达到循环结束条件时强制跳出循环,Shell使用两个命令来实现该功能:break和continue。
1.break跳出循环
当我们需要跳出当前循环,或者终止死循环时,我们就可以使用break来跳出循环。接下来我们运行如下代码:
#!/bin/bash
var=1
while(( $var < 5 ))
do
if(( $var>3 ))
then
echo "跳出循环"
break
fi
echo "$var"
var=`expr $var + 1`
done执行结果为:
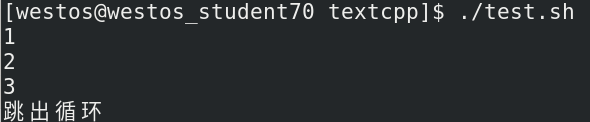
在该循环中var>3时break,而是直接跳出循环。
2.continue跳出循环
continue命令与break命令类似,只有一点差别,它不会跳出所有循环,仅仅跳出当前循环。 接下来我们运行如下代码:
#!/bin/bash
var=1
while(( $var < 5 ))
do
if(( $var>3 ))
then
echo "跳出循环"
continue
fi
echo "$var"
var=`expr $var + 1`
done
执行结果为:
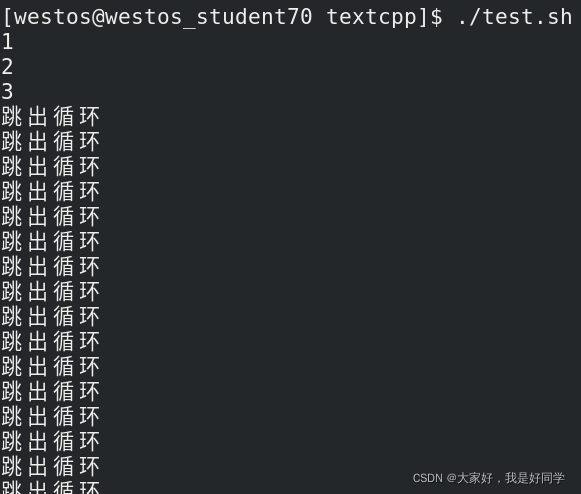
使用continue跳出的循环只是当前循环,无法跳出整个循环,由于在该代码中我们每次执行到continue就会跳出当前循环,无法执行 var=expr $var + 1,所以循环条件一直成立,就成了死循环。
3.3.3 case-esac多选择语句
case ... esac 为多选择语句,与其他语言中的switch ... case 语句类似,是一种多分支选择结构,每个 case 分支用右圆括号开始,用两个分号 ;;表示 break,即执行结束,跳出整个 case … esac 语句,esac(就是 case 反过来)作为结束标记。
case 要求取值后面必须为单词 in,每一模式必须以右括号结束。取值可以为变量或常数,匹配发现取值符合某一模式后,其间所有命令开始执行直至 ;;。
若检测匹配时无一匹配,使用*捕获该值,再执行后续命令。
语法格式如下:
case 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
*)
command1
esac
3.3.3 select-in语句
select in是shell中独有的一种循环,非常适合终端的交互场景,它可以显示出带编号的菜单,用户出入不同编号就可以选择不同的菜单,并执行不同的功能。
语法格式如下:
select var in seq
do
action
done
我们执行如下代码:
#!/bin/bash echo "What is your favourite OS?" select var in "Linux" "Gnu Hurd" "Free BSD" "Other"; do break; done echo "You have selected $var"
执行结果为:
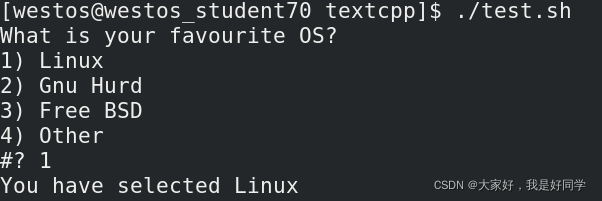
四、函数
函数其实就是将一段代码组合封装在一起实现某个特定的功能或返回某个特定的值。我们在定义函数时需要先起一个函数名,在使用的时候直接调用函数名即可。
4.1 定义函数
shell中定义函数格式如下:
[ function ] funname [()]
{
action;
[return int;]
}
注意:
1.以上的[ function ]也可以省略
2.当函数没有return时,默认返回最后一个命令的运行结果作为返回值。
4.2 函数参数
在shell中,调用函数时可以向其传递参数。在函数内部直接通过$n获取参数的值。我们给出示例如下:
#!/bin/bash
funWithParam(){
echo "第一个参数为 $1 !"
echo "第十个参数为 ${10} !"
}
funWithParam 1 2 3 4 5 6 7 8 9 34 73
需要注意$10不能返回第十个参数,当n>10的时候,需要使用$(n)来获取参数。
4.3 函数作用域
Shell脚本中执行函数时并不会开启子进程,默认在函数外部或函数内部定义和使用变量的效果相同。函数外部的变量在函数内部可以直接调用,反之函数内部的变量也可以在函数外部直接调用。但是这样会导致变量混淆、数据可能被错误地修改等等问题,那么如何解决这些问题呢?
系统为我们提供了一个local语句,该语句可以使在函数内部定义的变量仅在函数内部有效。定义时直接在变量前加local即可。
五、重定向
一个命令通常从一个叫标准输入的地方读取输入,默认情况下,这恰好是你的终端。同样,一个命令通常将其输出写入到标准输出,默认情况下,这也是你的终端。
一般情况下,每个 Unix/Linux 命令运行时都会打开三个文件:
- 标准输入文件(stdin):stdin的文件描述符为0,Unix程序默认从stdin读取数据。
- 标准输出文件(stdout):stdout 的文件描述符为1,Unix程序默认向stdout输出数据。
- 标准错误文件(stderr):stderr的文件描述符为2,Unix程序会向stderr流中写入错误信息。
但有些时候我们可能需要将数据从其它文件读入或读出,这就需要我们重定向。
5.1 输入重定向
我们可以让命令从文件中获取,这样本来的命令需要从标准输入stdin中获取,转换为从我们的指定文件中获取。这样本来需要从键盘输入的命令就会转移到文件读取内容。语法如下:
command1 < file
5.2 输出重定向
同输入重定向很相似,输出重定向也是将本来需要输出标准输出文件stdout中转化为我们的指定文件中。语法如下:
command1 > file
5.3 标准错误文件重定向
我们可以直接借助标准错误文件的文件描述符来重定向stderr,语法如下:
$ command 2>file
扩充一点,如果我们想将stdout标准输出文件和stderr标准错误文件合并重定向到一个指定文件中,语法如下:
$ command > file 2>&1
5.4 Here Document
Here Document 是 Shell 中的一种特殊的重定向方式,用来将输入重定向到一个交互式 Shell 脚本或程序。它的作用是将两个 delimiter 之间的内容(document) 作为输入传递给 command。基本语法如下:
command << delimiter documentdelimiter
注意:
结尾的delimiter 一定要顶格写,前面不能有任何字符,后面也不能有任何字符,包括空格和 tab 缩进。开始的delimiter前后的空格会被忽略掉。
5.5 /dev/null 文件
如果希望执行某个命令,但又不希望在屏幕上显示输出结果,那么可以将输出重定向到 /dev/null中,/dev/null 是一个特殊的文件,写入到它的内容都会被丢弃;如果尝试从该文件读取内容,那么什么也读不到。但是 /dev/null 文件非常有用,将命令的输出重定向到它,会起到"禁止输出"的效果。语法如下:
$ command > /dev/null
总结
加载全部内容