python自动化测试APScheduler Flask
opentest-oper@360.cn 人气:0使用背景
实际项目中,需要验证打点数据在各个系统中收集是否一致,而部分节点打点数据收集是通过异步任务实现的,等待时间比较久。为应对业务异步操作处理,实现异步数据的收集,经过调研后,选择了 APScheduler 框架。
什么是 APScheduler 框架?
APScheduler 是基于 Quartz(一个功能丰富的开源任务调度系统) 的一个 Python 定时任务框架,使用起来简单且方便,提供了基于日期、固定时间间隔以及 crontab 类型的任务,并且可以持久化任务,基于这些功能可以快速实现 python 的定时轮询任务系统。
使用 APScheduler 框架,可以通过 pip 安装
pip install apscheduler
APScheduler 框架包含四个组成部分
触发器 (trigger)触发器包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行;除了他们自己初始的配置,触发器本身是无状态的。
作业存储 (job store)作业存储存储被调度的作业,默认的作业存储是简单的将作业保存到内存中,如果选择其他方式也可以将作业保存到数据库中;一个作业数据的保存将会在持久化作业存储的时候被序列化,然后在加载时被反序列化;调度器无法分享同一个作业存储。
执行器 (executor)执行器处理作业的运行,一般通过在作业中提交制定好的可调用对象到一个线程中或者线程池中来执行;在作业完成时,执行器会去通知调度器。
调度器 (scheduler)调度器是 APScheduler 的核心,所有相关的组件都要通过它来定义,已配置好的任务也是要通过它来调度。
APScheduler 在 flask 中使用
因为 scheduler 任务需要耗费较多时间,因此当在项目中收到 flask 的接口请求后,可以通过线程异步处理耗时任务,先将 “正在处理” 作为接口结果返回,
示例代码结构如下:

编写任务函数,开始 APScheduler 的调度
在通过 flask 接口拿到需要的任务参数后,便可以创建调度任务。在创建调度任务之前,我们需要确定要选择哪一种调度器、job 存储、执行器和触发器,
调度器的选择主要基于编程环境以及 APScheduler 的用途,

这里我们根据需要选择 BackgroundScheduler。
在 job 存储的选择上,需要根据自己的 job 是否需要持久化,因为没有特殊的需求,所以使用默认的内存方式

执行器的选择需要依据 job 的类型,默认的线程池执行器apscheduler.executors.pool.ThreadPoolExecutor 已经可以满足大多数情况。
管理 job 的调度方式需要选择一个合适的触发器,APScheduler 内置三种触发器;

因为我们的自动化需要对各个子环节进行验证,当上一个环节成功后才能进行下一个环节的验证,因此选择 apscheduler.triggers.interval,以固定的时间间隔运行 job。
部分项目代码
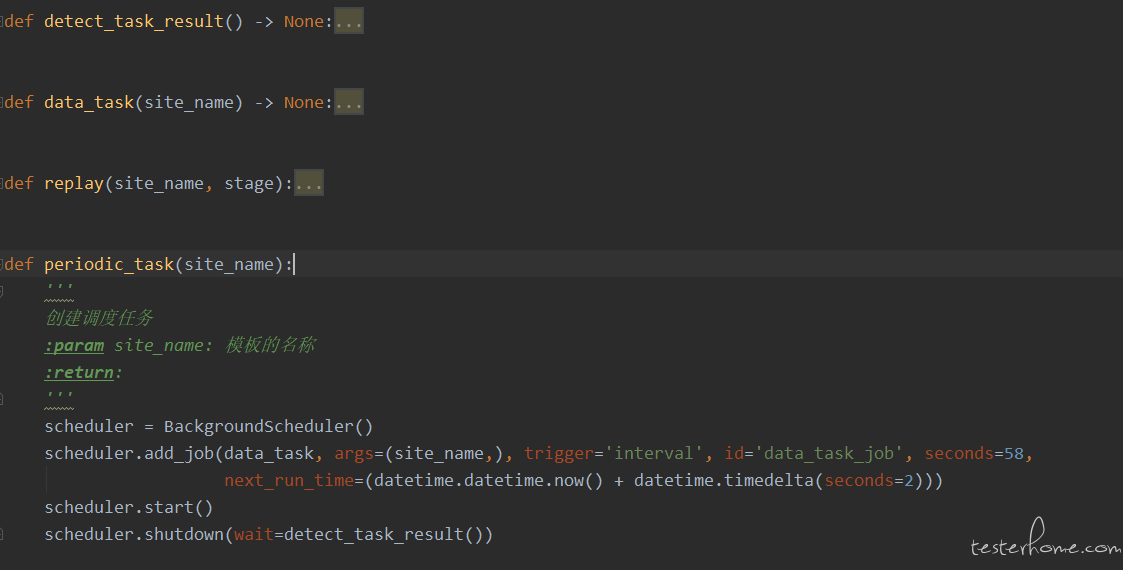
periodic_task 是项目中的任务调度函数;首先实例化了一个 BackgroundScheduler 调度器,接着向调度器添加 job,添加的 job 为 data_task 函数,同时定义了 job 的触发器,指定固定的时间间隔为 58 秒。
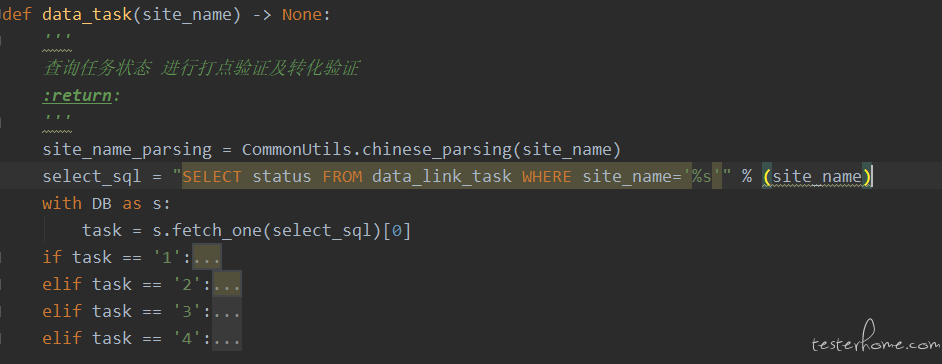
其中 data_task 描述了具体的 job 细节,即分别判断当前不同的任务节点执行相应的验证过程,并将每一步的验证状态记录到数据库中,这样在下一次执行 data_task 时,就可以去校验新的环节;
启动调度器使用 start 函数,结束调度器使用 shutdown 函数;
shutdown 函数可以指定停止条件,在本项目中,因为步骤比较多,一旦有环节出错,就需要结束任务,保存已验证的环节,因此在拿到任务结果时,不论是整个验证成功的结果,还是某个环节出错的结果,都会停止本次调度,结束掉本次验证。
总结
- APScheduler 在 flask 中使用需要用到线程池异步去处理耗时任务;
- 使用 APScheduler 需要配置好合适的调度器、job 存储、执行器和触发器;
- 在业务中验证复杂连续的步骤可以使用轮询的方式,并设置好任务结束的条件,不仅可以校验每一步的验证结果而且有环节出错也不影响整个流程。
加载全部内容