Java集合类List
世界尽头与你 人气:01.集合框架体系
集合框架被设计成要满足以下几个目标。
- 该框架必须是高性能的。基本集合(动态数组,链表,树,哈希表)的实现也必须是高效的。
- 该框架允许不同类型的集合,以类似的方式工作,具有高度的互操作性。
- 对一个集合的扩展和适应必须是简单的。
为此,整个集合框架就围绕一组标准接口而设计。你可以直接使用这些接口的标准实现,诸如: LinkedList, HashSet, 和 TreeSet 等,除此之外你也可以通过这些接口实现自己的集合。
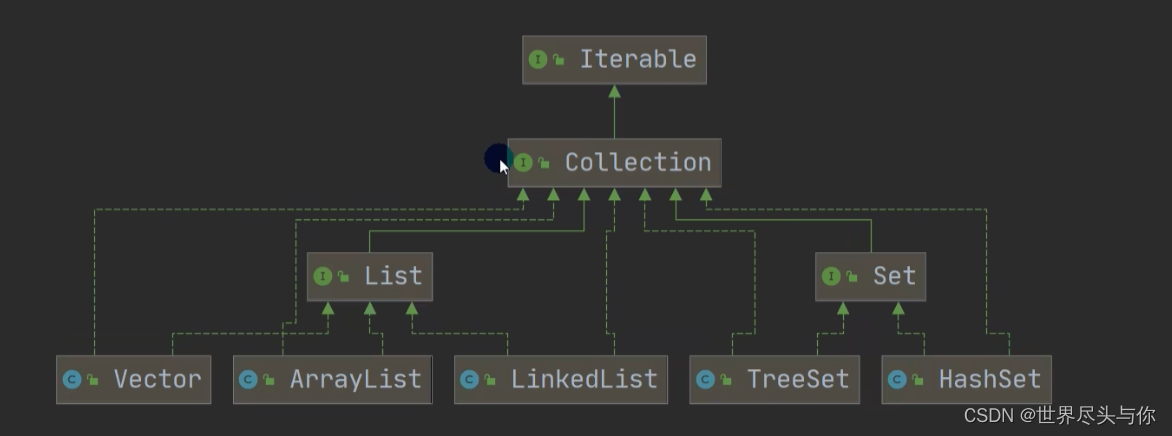
Collection接口的实现子类
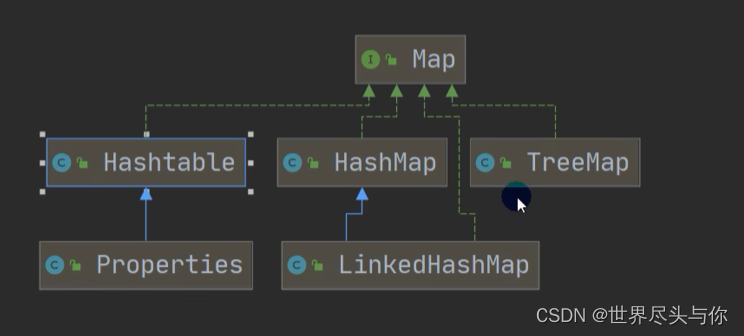
Map接口的实现子类
体系图
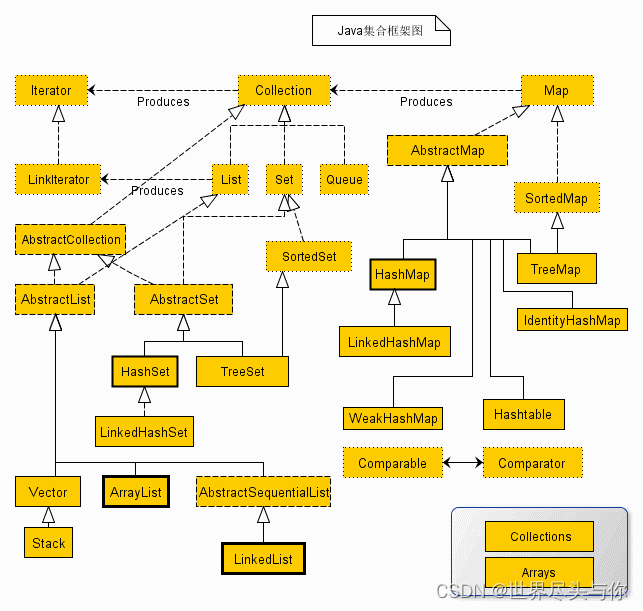
从上面的集合框架图可以看到,Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
2.Collection接口
该接口定义:
public interface Collection<E> extends Iterable<E>
Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素, Java不提供直接继承自Collection的类,只提供继承于的子接口(如List和set)。
Collection 接口存储一组不唯一,无序的对象。
Collection接口的常用方法:
import java.util.ArrayList;
import java.util.List;
/**
* Collection接口的实现类
* Java不提供直接继承自Collection的类,只提供继承于的子接口
* 所以我们以ArrayList为例子演示Collection接口的抽象方法
*/
public class CollectionTest {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
// 添加
list.add("dahe");
list.add(521);
list.add(true);
System.out.println(list);
// 删除
// 删除第一个元素
list.remove(0);
// 删除指定的元素
list.remove(true);
System.out.println(list);
// 查找
System.out.println(list.contains(521));
// 元素个数
System.out.println(list.size());
// 判空
System.out.println(list.isEmpty());
// 清空
list.clear();
// 添加多个元素(可以添加另一个实现了Collection接口的对象)
ArrayList arrayList = new ArrayList();
arrayList.add("tiktok直播");
arrayList.add("tiktok广告投放");
list.addAll(arrayList);
System.out.println(list);
// 查找多个元素是否都存在
System.out.println(list.containsAll(arrayList));
// 删除多个元素
list.removeAll(arrayList);
System.out.println(list);
}
}输出:
[dahe, 521, true]
[521]
true
1
false
[tiktok直播, tiktok广告投放]
true
[]
3.迭代器
Java Iterator(迭代器)不是一个集合,它是一种用于访问集合的方法,可用于迭代 ArrayList 和 HashSet 等集合。
Iterator 是 Java 迭代器最简单的实现,ListIterator 是 Collection API 中的接口, 它扩展了 Iterator 接口。
迭代器 it 的两个基本操作是 next 、hasNext 和 remove。
- 调用 it.next() 会返回迭代器的下一个元素,并且更新迭代器的状态。
- 调用 it.hasNext() 用于检测集合中是否还有元素。
- 调用 it.remove() 将迭代器返回的元素删除。
代码DEMO示例:
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* 迭代器
*/
public class IteratorTest {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("三国演义","罗贯中",52.7));
col.add(new Book("小李飞刀","古龙",10.2));
col.add(new Book("红楼梦","曹雪芹",34.6));
System.out.println(col);
// 使用迭代器
Iterator iterator = col.iterator();
while (iterator.hasNext()) {
// 返回下一个元素,类型是Object
Object obj = iterator.next();
System.out.println(obj);
}
}
}
class Book {
private String name;
private String author;
private Double price;
public Book(String name, String author, Double price) {
this.name = name;
this.author = author;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
}输出:
[Book{name='三国演义', author='罗贯中', price=52.7}, Book{name='小李飞刀', author='古龙', price=10.2}, Book{name='红楼梦', author='曹雪芹', price=34.6}]
Book{name='三国演义', author='罗贯中', price=52.7}
Book{name='小李飞刀', author='古龙', price=10.2}
Book{name='红楼梦', author='曹雪芹', price=34.6}
我们还可以使用增强型for循环来遍历集合:(底层依然是迭代器,可以理解为简化版的迭代器遍历)
for (Object o : col) {
System.out.println(o);
}
4.List接口
List接口是Collection接口的子接口
List集合中元素有序(添加顺序和取出顺序一致),元素可以重复
List中的每个元素都有其顺序的索引
常用方法代码示例:
/**
* List接口,Collection接口的子接口
*/
import java.util.ArrayList;
import java.util.List;
public class ListTest {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
List list1 = new ArrayList();
list1.add("ceshi");
list1.add("tangseng");
// 添加元素
list.add("dahe");
list.add("tom");
list.add("dahe"); // 可以重复
// 指定位置插入元素
list.add(1,"qian");
// 加入多个元素,传入一个Collection对象
list.addAll(1,list1);
System.out.println(list);
// 取出指定索引的元素
System.out.println(list.get(0));
// 查找元素第一次出现的位置
System.out.println(list.indexOf("dahe"));
// 查找元素最后一次出现的位置
System.out.println(list.lastIndexOf("dahe"));
// 删除元素
list.remove(1);
System.out.println(list);
// 元素替换
list.set(1,"marry");
System.out.println(list);
// 返回子集合,0到1的元素集合
List returnList = list.subList(0,2);
System.out.println(returnList);
}
}输出:
[dahe, ceshi, tangseng, qian, tom, dahe]
dahe
0
5
[dahe, tangseng, qian, tom, dahe]
[dahe, marry, qian, tom, dahe]
[dahe, marry]
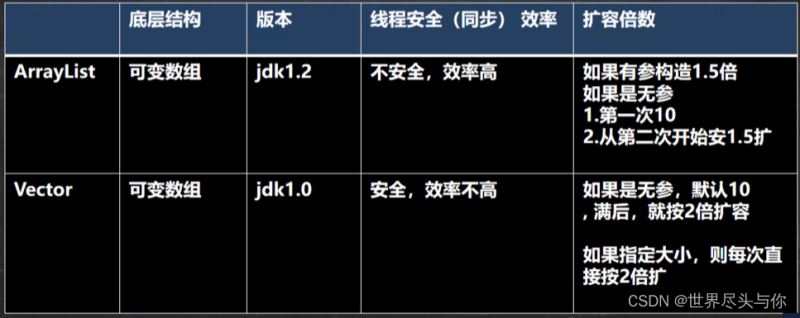
5.ArrayList
ArrayList是由数组来进行数据存储的,为线程不安全,效率较高多线程场景建议使用vector
例如ArrayList add方法的源码:(并没有synchronized进行修饰)
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
ArrayList扩容机制
使用无参构造器
当我们使用ArrayList的无参构造器的时候,进入源码分析:
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
这里的elementData是ArrayList存放数据的数组,可以看出当我们调用无参构造的时候,数组初始化为DEFAULTCAPACITY_EMPTY_ELEMENTDATA,那这一长串代表什么呢?
继续步入
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
1
该值为空,那么我们可以得出结论,当调用ArrayList的无参构造时,存储数组的默认空间大小为0,也就是空
同时,我们追入elementData数组,可以发现他是Object数组,这也就解释了为什么ArrayList可以加入任意类型的元素,因为Object是万物之父!
transient Object[] elementData; // non-private to simplify nested class access
添加数据之前的准备
接下来,当我们使用add方法,比如操作下面这行代码:
arrayList.add(521);
首先,ArrayList会对521进行装箱操作:
@IntrinsicCandidate
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
继续步入,进入如下代码:
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
我们来仔细看一下这段代码,首先:
modCount++;
在所有的集合实现类中(Collection与Map中),都会有一个 modCount 的变量出现,它的作用就是记录当前集合被修改的次数。此处将修改次数 + 1,防止多线程操作异常
随后,进入真正添加数据的add重载方法:
add(e, elementData, size);
开始添加数据
在真正添加数据的部分,代码如下:
可以看到,首先需要判断elementData数组的容量是否充足,如果容量已经满了的话,就执行grow方法进行扩容,否则就加入数据,size + 1
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
那他是怎么进行扩容的呢?
我们进入grow方法看一下:
private Object[] grow() {
return grow(size + 1);
}
继续步入到grow的重载方法:
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
获取老的容量
如果一次也没有扩容过,则扩容大小为DEFAULT_CAPACITY和minCapacity较大的一个,DEFAULT_CAPACITY被定义为10,而我们此时的minCapacity为1,所以第一次扩容的大小为10
如果老的容量大于0或者elementData数组不是初始化状态的数组(也就是已经第一次扩容过)
那么通过位运算进行扩容到原容量的1.5倍
注意:IDEA在debug默认情况下显示的数据是简化的,如果需要看完整的数据,需要进行设置
使用指定大小的构造器
原理操作和上面类似,只不过它初始的容量为指定的容量,需要扩容时扩容为原容量的1.5倍
ArrayList使用实例
ArrayList arrayList = new ArrayList();
arrayList.add(521);
arrayList.add(null);
arrayList.add("武松");
arrayList.add(null);
System.out.println(arrayList);
输出:
[521, null, 武松, null]
6.Vector
vector底层同样是一个对象数组
protected Object[] elementData;
和ArrayList不同的是,它是线程同步的,也就是线程安全的
Vector和ArrayList的区别:
7.LinkedList
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址。
链表可分为单向链表和双向链表。
一个单向链表包含两个值: 当前节点的值和一个指向下一个节点的链接。
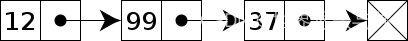
一个双向链表有三个整数值: 数值、向后的节点链接、向前的节点链接。

Java LinkedList(链表) 类似于 ArrayList,是一种常用的数据容器。
与 ArrayList 相比,LinkedList 的增加和删除的操作效率更高,而查找和修改的操作效率较低。
LinkedList的底层是一个双向链表
增加元素源码分析
在LinkedList链表中,存在几个必知的概念 --> First:链表头节点;Last:链表尾节点;next:该节点下一个节点地址;prev:该节点前一个节点地址
LinkedList linkedList = new LinkedList(); // 增 linkedList.add(521); linkedList.add(1314); System.out.println(linkedList);
首先:调用LinkedList的无参构造,这里什么也没有捏
public LinkedList() {
}
随后,和ArrayList和Vector一样,进行装箱操作
开始添加操作:
public boolean add(E e) {
linkLast(e);
return true;
}
为了方便理解,我们需要知道一下Node的构造器内容:
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
继续步入:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
这里是关键,接下来我们来分析一下上面的这段代码:
首先,将last的值赋给l,新建一个Node节点,将last指向新建的Node节点,随后进行分支判断,将first也指向新建的Node节点
最后,链表大小 + 1 ,修改次数 + 1
经过了上面的修改,现在的first和last都指向新建的节点,该节点的next和prev都为null
以上是链表中只有一个元素的情况,那么再次向链表添加元素呢?我们再来浅浅看一下
第二次添加节点,l被置为上一个节点的地址,随后会被添加到新节点的prev属性中:

还需要更新一下last的值为新添加进来的节点的地址:

随后,将上一个节点的next值置为当前新加的节点地址:

最后,更新size和modCount即可!
删除元素源码分析
// 删除最后一个节点 linkedList.remove();
进行源码分析,步入:
public E remove() {
return removeFirst();
}
继续步入:
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
Java的设计者在这里获取了链表头节点的地址,以备后续进行删除,随后检查了一个头节点为空的异常,在unlinkFirst方法,将会真正执行删除的操作!
继续步入:
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
开头,获取头节点的值,以备在后续返回:
final E element = f.item;
先获取一下头节点后面的节点的地址,保存下来,然后将头节点的数据和next置空,请求GC进行回收:
final Node<E> next = f.next; f.item = null; f.next = null; // help GC
头节点更新为原头节点的下一个节点,并作节点个数判断:
first = next;
if (next == null)
last = null;
else
next.prev = null;
最后,更新size和modCount,返回element
LinkedList使用Demo
import java.util.LinkedList;
/**
* LinkedList
*/
public class LinkedListTest {
@SuppressWarnings({"all"})
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
// 增
linkedList.add(521);
linkedList.add(1314);
System.out.println(linkedList);
// 删除头节点
linkedList.remove();
System.out.println(linkedList);
// 修改
linkedList.set(0,999);
System.out.println(linkedList);
// 查找
System.out.println(linkedList.get(0));
}
}输出:
[521, 1314]
[1314]
[999]
999
8.ArrayList和LinkedList的选择
以下情况使用 ArrayList :
- 频繁访问列表中的某一个元素。
- 只需要在列表末尾进行添加和删除元素操作。
以下情况使用 LinkedList :
- 你需要通过循环迭代来访问列表中的某些元素。
- 需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
在实际开发中,ArrayList用的最多,因为大部分的业务是查询业务!
另外,ArrayList和LinkedList都是线程不安全的,推荐在单线程场景下使用
加载全部内容