MySQL优化
Hz488 人气:01. 一些常用的 MySQL 命令
#连接MySQL
mysql -h 127.0.0.1 -u UserName -p pwd -P 3306
#创建新用户
CREATE USER 'username'@'host' IDENTIFIED BY 'password';
#赋权限,%表示所有(host):
grant all privileges on *.* to 'username'@'%';
#修改密码
update user set password=password("123456") where user='root';
#查看当前用户的权限
show grants for root@"%";
#显示所有数据库
show databases;
#打开数据库
use dbname;
#查看库中有哪些表
show tables
#显示表mysql数据库中user表的列信息)
describe user
#查看连接(包括用户、正在执行的操作、状态等)
show processlist
#刷新连接
flush privileges
#关闭某连接
kill id
#查询库中所有的表
select * from information_schema.tables where table_schema='zhebase';
#查询表信息(字段,字段类型,是否为空,编码,备注等)
select * from information_schema.columns where table_schema='zhebase' and table_name='student_inndb';
#查看MySQL权限 Host列表示那个Ip可以连接,User表示用户,后面的字段是权限
select * from mysql.user;
#查看全局服务器关闭非交互连接之前等待活动的秒数
show global variables like "wait_timeout";
#设置全局服务器关闭非交互连接之前等待活动的秒数(默认8小时不发送命令自动断连)
set global wait_timeout=28800; 
开发当中我们大多数时候用的都是长连接,把连接放在 Pool 内进行管理,但是长连接有时候会导致 MySQL 占用内存飙升,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。 怎么解决这类问题呢? 1、定期断开长连接。 使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。 2、如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。 这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
为什么说MySQL查询缓存是否鸡肋?
- 使用场景极少,表一改动就需要重新维护
- innodb,MyISAM 等引擎层有 buffer_pool 会自动缓存查询频繁的数据
- 可以使用第三方中间件代替
- LRU淘汰策略
#my.cnf配置文件中,一般将my.cnf参数 query_cache_type 设置成 DEMAND query_cache_type有3个值 0代表关闭查询缓存OFF,1代表开启ON,2(DEMAND)代表当sql语句中有SQL_CACHE 关键词时才缓存
2.MySQL的内部组件结构
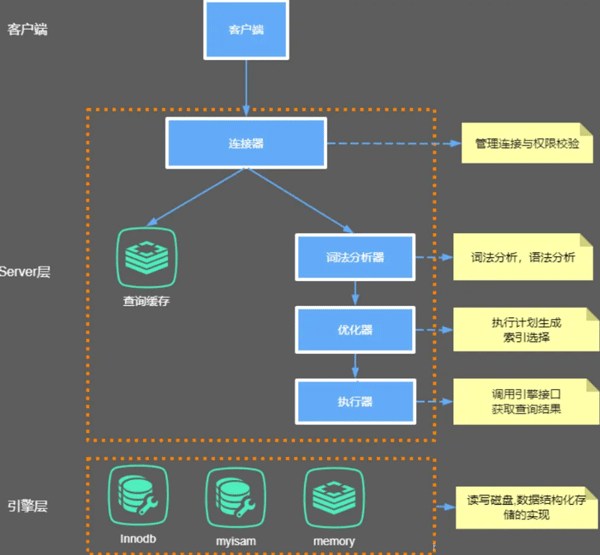
连接MySQL的过程:
- 1.完成经典的 TCP 握手建立连接
- 2.验证用户登录用户名密码
- 3.验证连接权限,是否运行该Ip连接(User表中的Host字段)
- 4.开辟专属 session 空间,连接后默认长连接,无操作8小时有效
- 5.将user表权限加入专属空间
- 6.每次执行命令在专属空间中查找是否有权限进行操作(权限修改后,如不重新连接,权限仍然不会改变,即使刷新连接也是如此)
MySQL优化器与执行计划
工作过程:
- 1.词法分析、语法分析、语义检查
- 2.预处理阶段(查询重写等)
- 3.查询优化阶段(可详细划分为逻辑优化、物理优化两部分)
- 4.查询优化器优化依据,来自于代价估算器估算结果(它会调用统计信息作为计算依据)
- 5.交由执行器执行
SQL执行过程
- 1.客户端提交一条语句
- 2.先在查询缓存(相当于一个Map,SQL语句是Key,结果集是Map)查看是否存在对应的缓存数据,如有则直接返回(一般有的可能性极小,因此一般建议关闭查询缓存)。MySQL 8.0开始取消了缓存器,5.0 默认关闭
- 3.交给解析器处理,解析器会将提交的语句生成一个解析树。
- 4.预处理器会处理解析树,形成新的解析树。这一阶段存在一些SQL改写的过程。
- 5.改写后的解析树提交给查询优化器。查询优化器生成执行计划。
- 6.执行计划交由执行引擎调用存储引擎接口,完成执行过程。这里要注意,MySQL的Server层和Engine层是分离的。
- 7.最终的结果由执行引擎返回给客户端,如果开启查询缓存的话,则会缓存
词法分析器原理
词法分析器分成6个主要步骤完成对sql语句的分析 1、词法分析 2、语法分析 3、语义分析 4、构造执行树 5、生成执行计划 6、计划的执行
查询优化器
- 负责生成 SQL 语句的有效执行计划的数据库组件
- 优化器是数据库的核心价值所在,它是数据库的“大脑”
- 优化SQL,某种意义上就是理解优化器的行为
- 优化的依据是执行成本(CBO)
- 优化器工作的前提是了解数据,工作的目的是解析SQL,生成执行计划
- 只要有WHERE的地方就会用到查询优化器,并非SELECT独有
举例:
Select EMPLOYEE.Name , WELFARE.Bonus From EMPLOYEE , WELFARE Where EMPLOYEE.Seniority > 5 And EMPLOYEE.Seniority = WELFARE.Seniority ; Select EMPLOYEE.Name , WELFARE.Bonus From EMPLOYEE , WELFARE Where EMPLOYEE.Seniority > 5 And EMPLOYEE.Seniority = WELFARE.Seniority And EMPLOYEE.Seniority > 5;
查询重写: 因为第一条将EMPLOYEE中Seniority > 5 的行与 WELFARE 中的所有行作外连接再来找 Seniority 相等的行,而第二条则是将 EMPLOYEE 中 Seniority > 5 的行和 WELFARE 中 Seniority > 5 的行作外连接再来找 Seniority 相等的行,第二条语句只有更少的行参与外连接,效率更高。写 SQL 时查询优化器自动重写。
4. SQL执行顺序
(7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP <group_by_list> (6) HAVING <having_condition> (9) ORDER BY <order_by_list> (10) LIMIT <limit_number>
5.MySQL数据类型选择
在设计表时,选择数据类型时一般先确定大的类型(数字,字符串,时间,二进制),然后再根据有无符号、取值范围、是否定长等确定具体的数据类型。在设计时,尽量使用更小的数据类型以达到更优的性能。并且在定义时尽量使用 NOT NULL,避免 NULL 值。
数值类型
首先了解:
- 1 byte = 8 bit (1字节等于8位,当需要符号时,符号占用1位)
- float 的指数位有8位,尾数位有23位,符号位 1 位,float 的指数范围,为 -127~+128,按补码的形式来划分。有效位数 7 位
- double 有效位数 15 位
- 对DECIMAL(M,D) ,如果 M>D,为 M+2 否则为 D+2 字节
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 字节 | [27,27-1] | [0,28-1] | 小整数值 |
| SMALLINT | 2 字节 | [215,215-1] | [0,216-1] | 大整数值 |
| MEDIUMINT | 3 字节 | [223,223-1] | [0,224-1] | 大整数值 |
| INT/INTEGER | 4 字节 | [231,231-1] | [0,232-1] | 大整数值 |
| BIGINT | 8 字节 | [263,263-1] | [0,264-1] | 极大整数值 |
| FLOAT | 4 字节 | 约-3.40E+38 ~ 3.40E+38 | 约0~3.40E+38 | 单精度浮点数值 |
| DOUBLE | 8 字节 | 约1.7E-308~1.7E+308 | 约0~1.7E+308 | 双精度浮点数值 |
| DECIMAL | DECIMAL(M,D) | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
建议:
- 如果整型数据没有负数,如ID号,建议指定为UNSIGNED无符号类型,容量可以扩大一倍。
- 建议使用TINYINT代替ENUM、BITENUM、SET。
- 避免使用整数的显示宽度,不要用INT(10)类似的方法指定字段显示宽度,直接用 INT。使用显示宽度后会不足自动填充0,但对查询无影响,查询结果不会自动填充0。
- DECIMAL最适合保存准确度要求高,而且用于计算的数据,比如价格。但是在使用DECIMAL类型的时候,注意长度设置。
- 建议使用整型类型来运算和存储实数。
- 整数通常是最佳的数据类型,因为它速度快,并且能使用AUTO_INCREMENT。
日期和时间
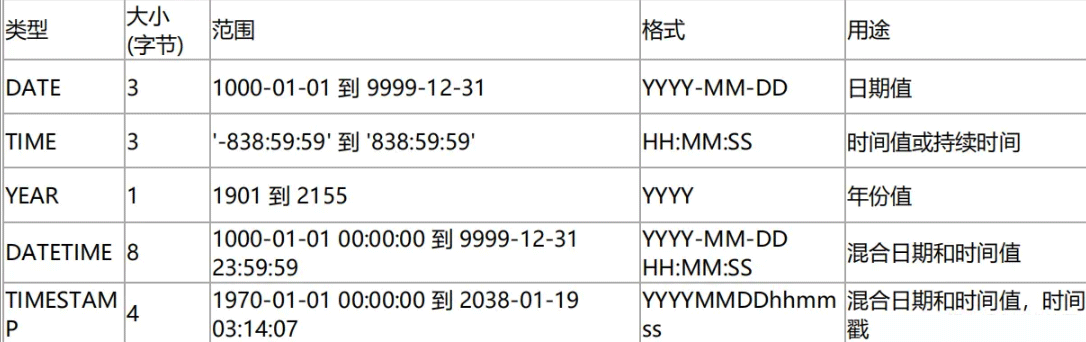
建议:
- MySQL 能存储的最小时间粒度为秒。
- 建议用 DATE 数据类型来保存日期。MySQL 中默认的日期格式是 yyyy-MM-dd。
- 用 MySQL 的内时间类型 DATE、TIME、DATETIME 来存储时间,而不是使用字符串。
- 当数据格式为 TIMESTAMP 和 DATETIME 时,可以用 CURRENT_TIMESTAMP 作为默认(MySQL5.6以后), MySQL 会自动返回记录插入的确切时间。
- TIMESTAMP 是 UTC 时间戳,与时区相关。
- DATETIME 的存储格式是一个 YYYYMMDD HH:MM:SS 的整数,与时区无关。
- 除非有特殊需求,一般的公司建议使用 TIMESTAMP,比DATETIME更节约空间,大公司使用DATETIME,因为要用考虑 TIMESTAMP 将来的时间上限(1970-2037)问题。
- 不要使用 Unix 的时间戳保存为整数值,处理起来极其不方便。
字符串
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串,char(n)当插入的字符串实际长度不足n时, 插入空格进行补充保存。在进行检索时,尾部的空格会被去掉。 |
| VARCHAR | 0-65535 字节 | 变长字符串,varchar(n)中的n代表最大列长度,插入的字符串实际长度不足n时不会补充空格 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16777215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16777215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294967295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294967295字节 | 极大文本数据 |
建议
- 字符串的长度相差较大用 VARCHAR;字符串短,且所有值都接近一个长度用 CHAR。
- CHAR 和 VARCHAR 适用于包括人名、邮政编码、电话号码和不超过255个字符长度的任意字母数字组合。那些 要用来计算的数字不要用 VARCHAR 类型保存,因为可能会导致一些与计算相关的问题。换句话说,可能影响到计算的准确性和完整性。
- 尽量少用 BLOB 和 TEXT,如果实在要用可以考虑将 BLOB 和 TEXT 字段单独存一张表,用 id 关联。
- BLOB 系列存储二进制字符串,与字符集无关。TEXT 系列存储非二进制字符串,与字符集相关。
- BLOB 和 TEXT 都不能有默认值。
6.MySQL优化
MySQL优化分类
- 减少磁盘IO 全表扫描 临时表 日志、数据块 fsync
- 减少网络带宽 返回数据过多 交互次数过多
- 降低CPU消耗 排序分组:order by, group by 聚合函数:max,min,count,sum.. 逻辑读
优化方法
- 创建索引减少扫描量
- 调整索引减少计算量
- 索引覆盖(减少不必访问的列,避免回表查询)
- SQL改写
- 干预执行计划
SQL优化原则
减少访问量: 数据存取是数据库系统最核心功能,所以 IO 是数据库系统中最容易出现性能瓶颈,减少 SQL 访问 IO 量是 SQL 优化的第一步;数据块的逻辑读也是产生CPU开销的因素之一。
- 减少访问量的方法:创建合适的索引、减少不必访问的列、使用索引覆盖、语句改写。
减少计算操作: 计算操作进行优化也是SQL优化的重要方向。SQL 中排序、分组、多表连接操作等计算操作都是十分消耗 CPU 的。
- 减少 SQL 计算操作的方法:排序列加入索引、适当的列冗余、SQL 拆分、计算功能拆分。
EXPLAIN 查看执行计

type列,连接类型。一个好的SQL语句至少要达到range级别。杜绝出现all级别。
- 1. system:表只有一行记录,const类型的特例,基本不会出现,可以忽略
- 2. const:通过索引一次就查询出来了,const用于比较primary key或者unique索引。只需匹配一行数据,所有很快。如果将主键置于where列表中,mysql就能将该查询转换为一个const
- 3. eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键 或 唯一索引扫描。
- 4. ref:非唯一性索引扫描,返回匹配某个单独值的所有行。本质是也是一种索引访问,它返回所有匹配某个单独值的行,然而他可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体。
- 5. range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。一般就是在where语句中出现了bettween、<、>、in等的查询。这种索引列上的范围扫描比全索引扫描要好。只需要开始于某个点,结束于另一个点,不用扫描全部索引
- 6. index:Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常为ALL块,应为索引文件通常比数据文件小。(Index与ALL虽然都是读全表,但index是从索引中读取,而ALL是从硬盘读取)
- 7. all:Full Table Scan,遍历全表以找到匹配的行
key列,使用到的索引名。如果没有选择索引,值是NULL。 key_len列,索引长度。 rows列,扫描行数。该值是预估值。 extra列,详细说明。注意,常见的不太友好的值,如下:Using filesort,Using temporary。
processlist干预执行计划
- show [full] processlist
- information_schema.processlist copy to tmp table: 出现在某些alter table语句的copy table操作 Copying to tmp table on disk: 由于临时结果集大于tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存 converting HEAP to MyISAM: 线程正在转换内部MEMORY临时表到磁盘MyISAM临 时表 Creating sort index: 正在使用内部临时表处理select查询 Sorting index: 磁盘排序操作的一个过程 Sending data : 正在处理SELECT查询的记录,同时正在把结果发送给客户端 Waiting for table metadata lock: 等待元数据锁
SELECT语句务必指明字段名称
SELECT * 增加很多不必要的消耗(CPU、IO、内存、网络带宽) 直接使用select字段名称还增加了使用覆盖索引的可能性
- 如果排序字段没有用到索引,就尽量少排序
- 分页时要选择合理的方式
select id,name from customer limit 100000, 10 //查询从十万条开始的20条数据
上述代码,随着分页的后移,效率越来越慢,优化方法如下:可以取上一页的最大行数的 id(前提是ID 递增,且非联合主键,一般不建议设置联合主键,主键前面都可以加上ID作为主键),然后根据这个最大的 ID 来限制下一页的起点。或者通过索引查 id,在通过id查询出数据
合理使用in和exits
select * from A where id in (select id from B) select * from A where exists(select id from B where id=A.id)
in先执行子查询再执行主查询,exits先执行主查询再执行子查询。如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists
原则:小表驱动大表
关于not in 和not exists
如果查询语句使用了 not in 那么内外表都会放弃索引进行全表扫描;而 not extsts 的子查询依然能用到表上的索引。所以 not exists 都比 not in 要快。也可以使用一些方法转换逻辑来进行优化
//原SQL语句: select name from A where A.id not in (select B.id from B) //优化后的SQL语句: select name from A Left join B on where A.id = A.id where B.id is null
order by排序字段和where条件要匹配(关于联合索引)
当 where 条件和 order by 排序字段不匹配时,即使where条件中用到了索引,但执行 order by 时仍然会进行全表扫描(索引只能生效一个,且遵循最左匹配原则);order by后的索引生效时(索引本质是倒排表)效率会得到极大的提升。
select a,b,c from customer where a = 'xxx' and b = 'xxx' order by c;
- 1.最左前缀匹配原则:在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边
- 开始匹配。
- 2.当a,b,c为联合索引时遵循最左匹配原则,即:a,ab,abc索引都会生效,但b,c,bc,ac等不会生效(执行计划会使用到,
- type列为index,扫描索引树,效率相对于最左匹配的索引效率极低),所以定要注意索引顺序,最常用的最段要放在最前面。
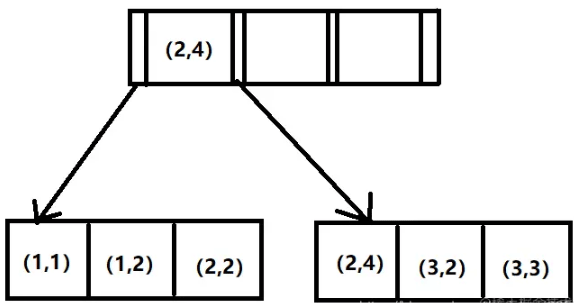
- 3.例如,创建一个a,b联合索引,它的索引树图如下。由图可以看出a值是有序的(1,1,2,2,3,3),b值是无序的,但是在a值相等的情况下b值又是有序的。由此可以看出MySQL创建联合索引时首先会对联合索引的最左边第一个字段排序,在第一个字段的排序基础上,然后在对第二个字段进行排序。所以b单独作为条件时,索引是无效的。
- 4.当a,b,c三个索引都用到时,只有全匹配,无论顺序如何,索引是有效的,MySQL执行计划会对其进行优化,自动使用最优方案执行。
不建议使用%前缀模糊查询
使用like '%name%'或者like '%name'会导致索引失效而导致全表扫描。但使用like 'name%'不会。
解决方法:
- - 1.使用全文索引
- - 2.使用Elasticsearch等搜索工具(不怎么修改的字段才建议使用,实际是倒排索引)
注意: 1.全文索引的存储引擎一定是Myisam,InnoDB没有全文索引 2.全文索引对中文不太友好
//创建全文索引
ALTER TABLE cust ADD FULLTEXT INDEX idx_cust_address ('cust_address');
//使用全文索引
select name from cust where match(cust_address) against('湖南');倒排索引是一种索引数据结构:从文本数据内容中提取出不重复的单词进行分词,每1个单词对应1个ID对单词进行区分,还对应1个该单词在那些文档中出现的列表 把这些信息组建成索引。倒排索引还记录了该单词在文档中出现位置、频率(次数/TF)用于快速定位文档和对搜素结果进行排序。
关于范围查询
对于联合索引来说,如果存在范围查询,比如between、>、<等条件时,会造成后面的索引字段失效
避免在where子句中对字段进行null值判断及!=和<>
对于null的判断以及!=和<>会导致引擎放弃使用索引而进行全表扫描。
关于OR
尽量使用union all或者是union方式来代替or。 union和union all的区别主要是union需要将结果集合并后再进行过滤操作过滤掉重复数据,这就会涉及到排序,增加大量的CPU运算,加大资源消耗及延迟。使用union all的前提条件是两个结果集没有重复数据。
只需要一条数据的时候,使用limit 1
可以使EXPLAIN中type列达到const类型
分段查询
在一些用户选择页面中,可能一些用户选择的时间范围过大,造成查询缓慢。主要的原因是扫描行数过多。这个时候可以通过程序,分段进行查询,循环遍历,将结果合并处理进行展示。
避免在where子句中对字段进行表达式及函数操作
应避免在where子句中对字段进行函数等操作,这将导致引擎放弃使用索引而进行全表扫描。
//原SQL select id,name from customer where salary/2 > 5000; //优化后 select id,name from customer where salary > 5000*2;
尽量使用 inner join,避免 left join
参与联合查询的表至少为2张表,一般都存在大小之分。如果连接方式是inner join,在没有其他过滤条件的情况下,MySQL会自动选择小表作为驱动表,但是left join在驱动表的选择上遵循的是左边驱动右边的原则,即left join左边的表名为驱动表。
IN包含的值不应过多
MySQL对于IN做了相应的优化,即将IN中的常量全部存储在一个数组里面,而且这个数组是排好序的。但是如果数值较多,产生的消耗也是比较大的。再例如:select id from t where num in(1,2,3) 对于连续的数值,能用between就不要用in了。或者使用连接来替换。
关于索引
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
- 并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的。当数据列差不多时(如男、女等)索引也无法优化查询效率。
- 索引并不是越多越好,经常进行查询的列建议添加索引,但经常进行修改的列不建议添加索引。在增删改操作会对索引进行维护,降低执行效率,且索引需要占用数据库资源
加载全部内容