Golang scheduler
树獭叔叔 人气:01. 调度器scheduler的作用
我们都知道,在Go语言中,程序运行的最小单元是gorouines。
然而程序的运行最终都是要交给操作系统来执行的,以Java为例,Java中的一个线程对应的就是操作系统中的线程,以此来实现在操作系统中的运行。在Go中,gorouines比线程更轻量级,其与操作系统的线程也不是一一对应的关系,然而,最终我们想要执行程序,还是要借助操作系统的线程来完成,调度器scheduler的工作就是完成gorouines到操作系统线程的调度。
2. GMP模型
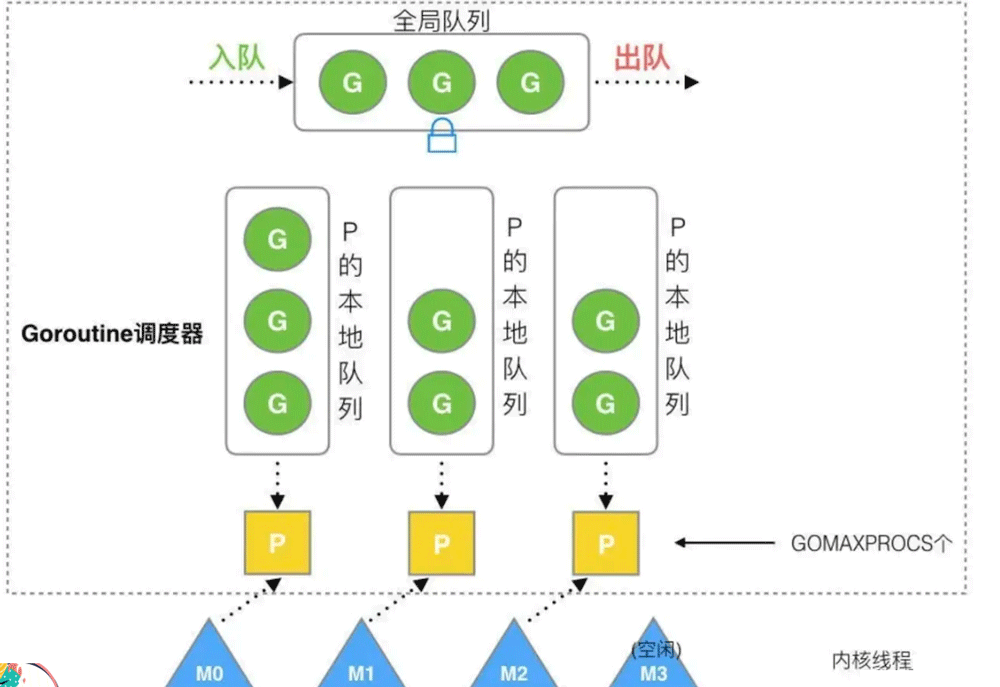
当我们运行go fun(){}时,会生成一个g,优先放置在创建他的p的本地队列中,如果本地队列已满,那么会放置在全局队列中。
g的运行需要借助p与m,p是执行器,只有获得p的g才能执行,p的执行需要挂在m上,m对应的是操作系统中的线程,p的数量与CPU的核数相同。
goroutine运行所需要的上下文信息都是存放在g的数据结构当中的,所以g可以依靠任意的p或者m执行,而对于操作系统而言,其并不能看到p与g的调度过程,这些过程对于操作系统线程来说都是连续的,所以省去了线程上下文切换的开销。
g的数据结构如下所示:
type g struct {
stack stack // g自己的栈
m *m // 执行当前g的m
sched gobuf // 保存了g的现场,goroutine切换时通过它来恢复
atomicstatus uint32 // g的状态Gidle,Grunnable,Grunning,Gsyscall,Gwaiting,Gdead
goid int64
schedlink guintptr // 下一个g, g链表
preempt bool //抢占标记
lockedm muintptr // 锁定的M,g中断恢复指定M执行
gopc uintptr // 创建该goroutine的指令地址
startpc uintptr // goroutine 函数的指令地址
}p的数据结构如下所示:
type p struct {
id int32
status uint32 // 状态
link puintptr // 下一个P, P链表
m muintptr // 拥有这个P的M
mcache *mcache
// P本地runnable状态的G队列
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr // 一个比runq优先级更高的runnable G
// 状态为dead的G链表,在获取G时会从这里面获取
gFree struct {
gList
n int32
}
gcBgMarkWorker guintptr // (atomic)
gcw gcWork
}m的数据结构如下所示:
type m struct {
g0 *g // g0, 每个M都有自己独有的g0
curg *g // 当前正在运行的g
p puintptr // 当前用于的p
nextp puintptr // 当m被唤醒时,首先拥有这个p
id int64
spinning bool // 是否处于自旋
park note
alllink *m // on allm
schedlink muintptr // 下一个m, m链表
mcache *mcache // 内存分配
lockedg guintptr // 和 G 的lockedm对应
freelink *m // on sched.freem
} 通过gmp模型,我们能解决gorouines到操作系统线程的映射问题,gorouines之间的切换是在用户态完成的,在操作系统的视角来看,线程的上下文切换并不频繁,因此就少了很多陷入内核的过程,所以有更好的并发效果。
3. 调度机制
1)work stealing机制
当一个p上的g执行完之后,他会尝试从其他的p队列中窃取g来执行,以减少操作系统线程的切换动作。
2)hand off机制
这个是针对m来说的,有的时候m可能因为g的信号调用而被操作系统阻塞,这个时候p就会挂载去另一个m继续执行可以执行的g,当阻塞的m就绪之后,会给p发信号,召唤他回来继续进行后续操作。
加载全部内容