LyScript应用层钩子扫描器
lyshark 人气:0Capstone 是一个轻量级的多平台、多架构的反汇编框架,该模块支持目前所有通用操作系统,反汇编架构几乎全部支持,本篇文章将运用LyScript插件结合Capstone反汇编引擎实现一个钩子扫描器。
要实现应用层钩子扫描,我们需要得到程序内存文件的机器码以及磁盘中的机器码,并通过capstone这个第三方反汇编引擎,对两者进行反汇编,最后逐条对比汇编指令,实现进程钩子扫描的效果。
LyScript项目地址:https://github.com/lyshark/LyScript
通过LyScript插件读取出内存中的机器码,然后交给第三方反汇编库执行,并将结果输出成字典格式。
#coding: utf-8
import binascii,os,sys
import pefile
from capstone import *
from LyScript32 import MyDebug
# 得到内存反汇编代码
def get_memory_disassembly(address,offset,len):
# 反汇编列表
dasm_memory_dict = []
# 内存列表
ref_memory_list = bytearray()
# 读取数据
for index in range(offset,len):
char = dbg.read_memory_byte(address + index)
ref_memory_list.append(char)
# 执行反汇编
md = Cs(CS_ARCH_X86,CS_MODE_32)
for item in md.disasm(ref_memory_list,0x1):
addr = int(pe_base) + item.address
dasm_memory_dict.append({"address": str(addr), "opcode": item.mnemonic + " " + item.op_str})
return dasm_memory_dict
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
pe_base = dbg.get_local_base()
pe_size = dbg.get_local_size()
print("模块基地址: {}".format(hex(pe_base)))
print("模块大小: {}".format(hex(pe_size)))
# 得到内存反汇编代码
dasm_memory_list = get_memory_disassembly(pe_base,0,pe_size)
print(dasm_memory_list)
dbg.close()
效果如下:
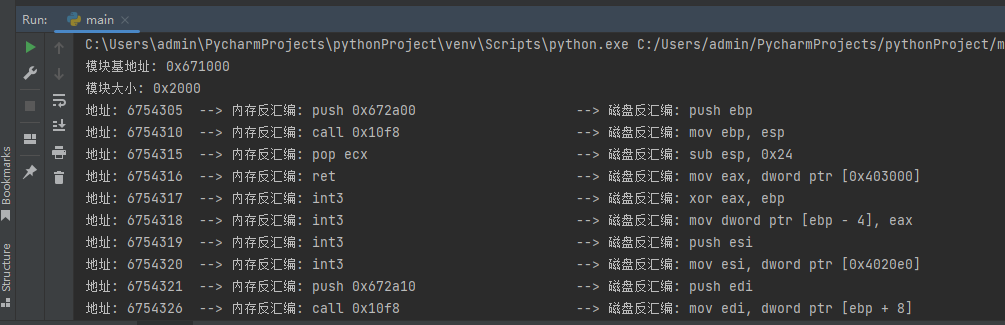
我们将文件反汇编也写一下,然后让其对比,这样就可以实现扫描内存与文件中的汇编指令是否一致。
#coding: utf-8
import binascii,os,sys
import pefile
from capstone import *
from LyScript32 import MyDebug
# 得到内存反汇编代码
def get_memory_disassembly(address,offset,len):
# 反汇编列表
dasm_memory_dict = []
# 内存列表
ref_memory_list = bytearray()
# 读取数据
for index in range(offset,len):
char = dbg.read_memory_byte(address + index)
ref_memory_list.append(char)
# 执行反汇编
md = Cs(CS_ARCH_X86,CS_MODE_32)
for item in md.disasm(ref_memory_list,0x1):
addr = int(pe_base) + item.address
dic = {"address": str(addr), "opcode": item.mnemonic + " " + item.op_str}
dasm_memory_dict.append(dic)
return dasm_memory_dict
# 反汇编文件中的机器码
def get_file_disassembly(path):
opcode_list = []
pe = pefile.PE(path)
ImageBase = pe.OPTIONAL_HEADER.ImageBase
for item in pe.sections:
if str(item.Name.decode('UTF-8').strip(b'\x00'.decode())) == ".text":
# print("虚拟地址: 0x%.8X 虚拟大小: 0x%.8X" %(item.VirtualAddress,item.Misc_VirtualSize))
VirtualAddress = item.VirtualAddress
VirtualSize = item.Misc_VirtualSize
ActualOffset = item.PointerToRawData
StartVA = ImageBase + VirtualAddress
StopVA = ImageBase + VirtualAddress + VirtualSize
with open(path,"rb") as fp:
fp.seek(ActualOffset)
HexCode = fp.read(VirtualSize)
md = Cs(CS_ARCH_X86, CS_MODE_32)
for item in md.disasm(HexCode, 0):
addr = hex(int(StartVA) + item.address)
dic = {"address": str(addr) , "opcode": item.mnemonic + " " + item.op_str}
# print("{}".format(dic))
opcode_list.append(dic)
return opcode_list
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
pe_base = dbg.get_local_base()
pe_size = dbg.get_local_size()
print("模块基地址: {}".format(hex(pe_base)))
print("模块大小: {}".format(hex(pe_size)))
# 得到内存反汇编代码
dasm_memory_list = get_memory_disassembly(pe_base,0,pe_size)
dasm_file_list = get_file_disassembly("d://win32project1.exe")
# 循环对比内存与文件中的机器码
for index in range(0,len(dasm_file_list)):
if dasm_memory_list[index] != dasm_file_list[index]:
print("地址: {:8} --> 内存反汇编: {:32} --> 磁盘反汇编: {:32}".
format(dasm_memory_list[index].get("address"),dasm_memory_list[index].get("opcode"),dasm_file_list[index].get("opcode")))
dbg.close()
此处如果一致,则说明没有钩子,如果不一致则输出,这里的输出结果不一定准确,此处只是抛砖引玉。
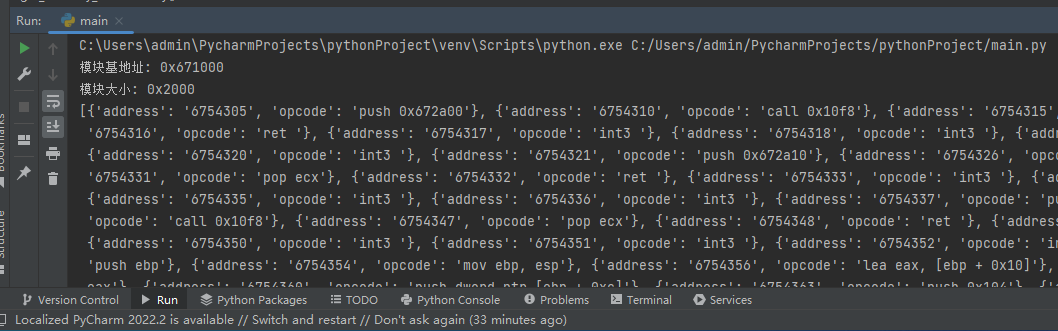
加载全部内容