分布式爬虫scrapy-redis踩坑
Indra_ran 人气:0一、安装redis
因为是在CentOS系统下安装的,并且是服务器。遇到的困难有点多不过。
1.首先要下载相关依赖
首先先检查是否有c语言的编译环境,你问我问什么下载这个,我只能说它是下载安装redis的前提,就像水和鱼一样。
rpm -q gcc```
如果输出版本号,则证明下载好了,否则就执行下面的命令,安装gcc,
2.然后编译redis
下载你想要的redis版本注意下面的3.0.6是版本号,根据自己想要的下载版本号,解压
yum install gcc-c++ cd /usr/local/redis wget http://download.redis.io/releases/redis-3.0.6.tar.gz tar zxvf redis-3.0.6.tar.gz make && make install
什么?你问我没有redis文件夹怎么办,mkdir创建啊!!!
一定要先进入目录再去执行下载编译,这样下载的redis才会进入系统变量。
redis-server redis-cli
启动服务你是下面这样的吗?
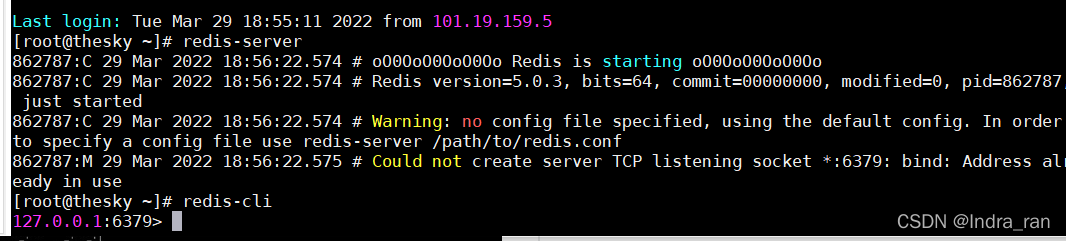
是的就不正常了!!你才下载好了,你会发现你可以开启服务了,但是退不出来,无法进入命令行了,变成下面的这鬼摸样了,别急,你还没配置好,慢慢来。
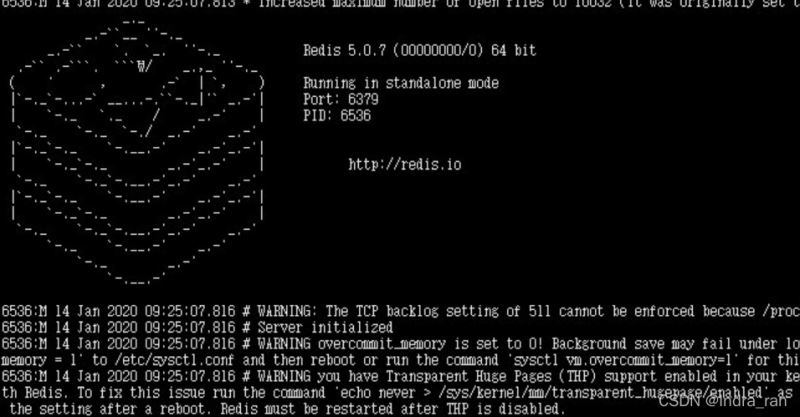
还记得你刚刚创建的redis文件夹吗?进入那里面,找到redis.conf,修改这个配置文件。
redis-server redis-cli
找到这三个并改正。
- 首先将bind进行注释,因为如果不注释的话,你就只能本机访问了,我相信你下载肯定不只是自己访问吧。这就意味着所有ip都可以访问这个数据库,但你又问了,这会不会影响安全性能呢?答:你都是租的服务器了,就算你想让别人访问,你还有安全组规则限制的啊,你问我什么是安全组?快去百度!!
- 将守护模式关闭,这样你才能远程读写数据库
- 开启后台模式,你才能像我那样,而不是退不出来
保存退出,重启redis,这样,redis就配置好了,还可以设置密码,但是我懒,不想设置。
至此数据库配置成功
二、scrapy框架出现的问题
1.AttributeError: TaocheSpider object has no attribute make_requests_from_url 原因:
新版本的scrapy框架已经丢弃了这个函数的功能,但是并没有完全移除,虽然函数已经移除,但是还是在某些地方用到了这个,出现矛盾。
解决方法
自己在相对应的报错文件中重写一下这个方法
就是在
def make_requests_from_url(self,url): return scrapy.Request(url,dont_filter=True)
2.ValueError: unsupported format character : (0x3a) at index 9 问题:
我开起了redis的管道,将数据保存在了redis中,但是每次存储总是失败报错。
原因:
我在settings.py文件中重写了保存的方法,但是保存的写法不对导致我一直以为是源码的错误
# item存储键的设置 REDIS_ITEMS_KEY = '%(spider):items'
源码是
return self.spider % {"spider":spider.name}
太坑了,我为了这个错误差点重写了一个scrapy框架…
注意!如果你觉得你的主代码一点问题都没有,那就一定是配置文件的问题,大小写,配置环境字母不对等
三、scrapy正确的源代码
1.items.py文件
import scrapy
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
lazyimg = scrapy.Field()
title = scrapy.Field()
resisted_data = scrapy.Field()
mileage = scrapy.Field()
city = scrapy.Field()
price = scrapy.Field()
sail_price = scrapy.Field()
2.settings.py文件
# Scrapy settings for myspider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'myspider'
SPIDER_MODULES = ['myspider.spiders']
NEWSPIDER_MODULE = 'myspider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# Obey robots.txt rules
# LOG_LEVEL = "WARNING"
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'myspider.middlewares.MyspiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'myspider.middlewares.MyspiderDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
LOG_LEVEL = 'WARNING'
LOG_FILE = './log.log'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 指定管道 ,scrapy-redis组件帮我们写好
ITEM_PIPELINES = {
"scrapy_redis.pipelines.RedisPipeline":400
}
# 指定redis
REDIS_HOST = '' # redis的服务器地址,我们现在用的是虚拟机上的回环地址
REDIS_PORT = # virtual Box转发redistribution的端口
# 去重容器类配置 作用:redis的set集合来存储请求的指纹数据,从而实现去重的持久化
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
# 使用scrapy-redis的调度器
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
# 配置调度器是否需要持久化,爬虫结束的时候要不要清空redis中请求队列和指纹的set集合,要持久化设置为True
SCHEDULER_PERSIST = True
# 最大闲置时间,防止爬虫在分布式爬取的过程中关闭
# 这个仅在队列是SpiderQueue 或者 SpiderStack才会有作用,
# 也可以阻塞一段时间,当你的爬虫刚开始时(因为刚开始时,队列是空的)
SCHEDULER_IDLE_BEFORE_CLOSE = 10
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'3.taoche.py文件
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
from ..items import MyspiderItem
import logging
log = logging.getLogger(__name__)
class TaocheSpider(RedisCrawlSpider):
name = 'taoche'
# allowed_domains = ['taoche.com'] # 不做域名限制
# start_urls = ['http://taoche.com/'] # 起始的url应该去redis(公共调度器) 里面获取
redis_key = 'taoche' # 回去redis(公共调度器)里面获取key为taoche的数据 taoche:[]
# 老师,我给你找一下我改的源码在哪里,看看是那的错误吗
rules = (
# LinkExtractor 链接提取器,根据正则规则提取url地址
# callback 提取出来的url地址发送请求获取响应,会把响应对象给callback指定的函数进行处理
# follow 获取的响应页面是否再次经过rules进行提取url
Rule(LinkExtractor(allow=r'/\?page=\d+?'),
callback='parse_item',
follow=True),
)
def parse_item(self, response):
print("开始解析数据")
car_list = response.xpath('//div[@id="container_base"]/ul/li')
for car in car_list:
lazyimg = car.xpath('./div[1]/div/a/img/@src').extract_first()
title = car.xpath('./div[2]/a/span/text()').extract_first()
resisted_data = car.xpath('./div[2]/p/i[1]/text()').extract_first()
mileage = car.xpath('./div[2]/p/i[2]/text()').extract_first()
city = car.xpath('./div[2]/p/i[3]/text()').extract_first()
city = city.replace('\n', '')
city = city.strip()
price = car.xpath('./div[2]/div[1]/i[1]/text()').extract_first()
sail_price = car.xpath('./div[2]/div[1]/i[2]/text()').extract_first()
item = MyspiderItem()
item['lazyimg'] = lazyimg
item['title'] = title
item['resisted_data'] = resisted_data
item['mileage'] = mileage
item['city'] = city
item['price'] = price
item['sail_price'] = sail_price
log.warning(item)
# scrapy.Request(url=function,dont_filter=True)
yield item4.其余文件
- 中间件没有用到所以就没有写
- 管道用的是scrapy_redis里面的,自己也就不用写
总结
加载全部内容