Java excel
Q C 人气:0前言
今天收到一个导入的任务,要求将excel数据保存到数据库中,不同于普通的导入,这个导入的数据是一个树形结构,如下图:
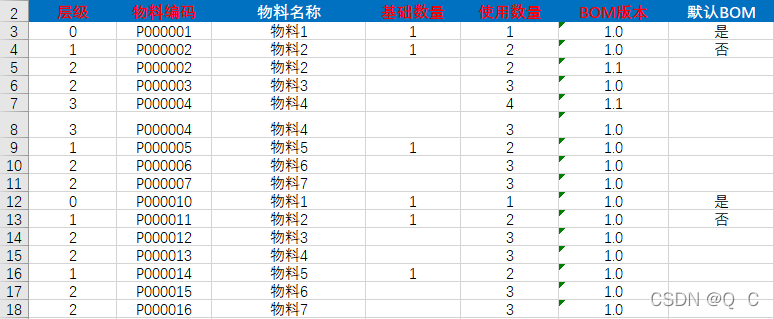
通过观察数据中的层级列我们发现表格数据由2棵树组成,分别是第3,4,5,6,7,8,9,10,11和12,13,14,15,16,17,18,它们由0作树的根节点,1为0的子节点,2为相邻1的子节点,由此得出第一颗树的结构为:
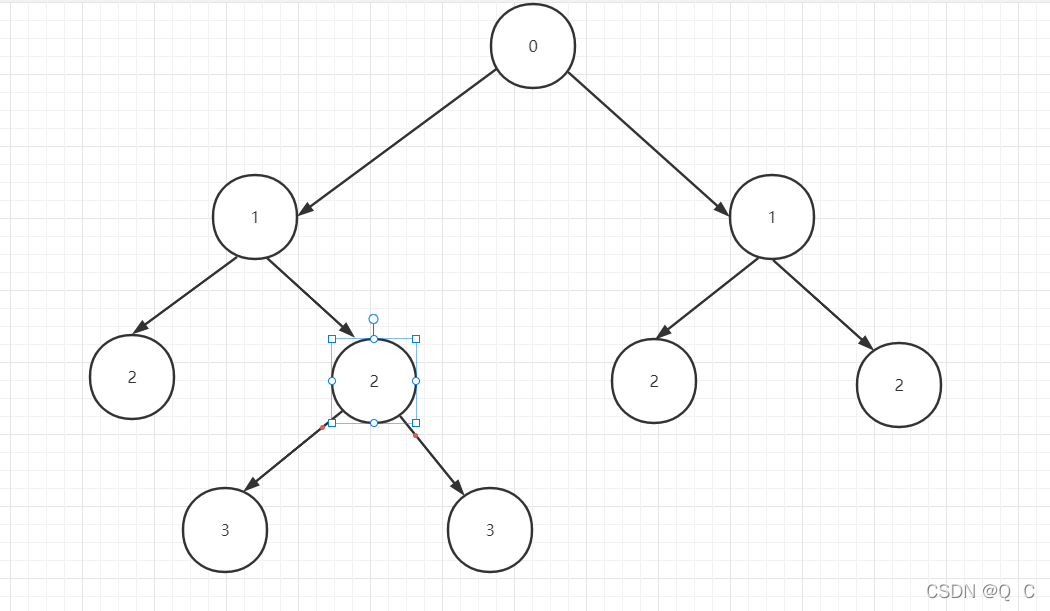
拆分原始数据
1.创建实体类
创建vo接收解析数据,在这里,我们只关心层级属性
@Excel(name = "层级")
private String hierarchy;
@Excel(name = "物料编码")
private String materialCode;
@Excel(name = "物料名称")
private String materialName;
@Excel(name = "基础数量")
private BigDecimal materialNum;
@Excel(name = "使用数量")
private BigDecimal useAmount;
@Excel(name = "BOM版本")
private String version;
@Excel(name = "默认BOM")
private String isDefaults;2.处理数据
将数据源拆分为若干棵树的数据集
代码如下(示例):
/**
* 将集合对象按指定元素分割存储
*
* @param materialVos 原始集合
* @param s 分割元素(这里是当集合对象层级为0时则分割,也就是树的根节点为0)
* @return 每棵树的结果集
*/
private List<List<MatMaterialBomImportVo>> subsection(List<MatMaterialBomImportVo> materialVos, String s) {
List<List<MatMaterialBomImportVo>> segmentedData = new ArrayList<>();
if (materialVos != null) {
//获取指定元素的数量,判断出最终将拆分为多少段
List<MatMaterialBomImportVo> collect = materialVos.stream().filter(bom -> s.equals(bom.getHierarchy())).collect(Collectors.toList());
int count = 0;
for (int i = 0; i < collect.size(); i++) {
List<MatMaterialBomImportVo> bomImportVo = new ArrayList<>();
boolean num = false;
//遍历数据源
for (; count < materialVos.size(); count++) {
//第一个必然为树的根节点,直接获取并跳过
if (count == 0) {
bomImportVo.add(materialVos.get(count));
continue;
}
//当数据源第n个等于根节点并且已经成功添加过数据时判断为一段数据的结束,跳出循环,
if (s.equals(materialVos.get(count).getHierarchy()) && num) {
break;
}
bomImportVo.add(materialVos.get(count));
num = true;
}
segmentedData.add(bomImportVo);
}
}
return segmentedData;
}手动设置每棵树每个节点的id以及父id
代码如下(示例):
for (List<MatMaterialBomImportVo> segmentedDatum : subsection(materialVos, "0")) {
//设置id以及父id
int i = 0;
for (MatMaterialBomImportVo vo : segmentedDatum) {
BeanTrim.beanAttributeValueTrim(vo);
vo.setPrimaryKey(i);
getParentId(vo, segmentedDatum);
i++;
}
}
/**
* 设置父id
*
* @param vo
* @param segmentedDatum
*/
private void getParentId(MatMaterialBomImportVo vo, List<MatMaterialBomImportVo> segmentedDatum) {
for (int j = vo.getPrimaryKey(); j >= 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
break;
}
if (j == 0) {
vo.setForeignKey(-1);
}
}
}说明:拆分为若干棵树后设置每条数据的虚拟id为自己的索引,每棵树的id互相隔离,
根据表格数据规律得出子节点只可能存在于自己节点以下,以及下一个相同节地以上,根据这个规律设置每个节点的父id
递归封装为树结构
代码如下(示例):
/**
* 递归遍历为树形结构
*
* @param vo 当前处理的元素
* @param segmentedDatum 每棵树的数据集
*/
private void treeData(MatMaterialBomImportVo vo, List<MatMaterialBomImportVo> segmentedDatum) {
for (int i = vo.getPrimaryKey(); i < segmentedDatum.size(); i++) {
if (i + 1 == segmentedDatum.size()) {
if (vo.getForeignKey() == null) {
getParentId(vo, segmentedDatum);
}
break;
}
int v = Integer.parseInt(vo.getHierarchy());
int vs = Integer.parseInt(segmentedDatum.get(i + 1).getHierarchy());
if (vs == v + 1) {
if (v > 1) {
vo.setForeignKey(segmentedDatum.get(i).getPrimaryKey());
for (int j = vo.getPrimaryKey(); j > 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
}
}
}
vo.getImportVoList().add(segmentedDatum.get(i + 1));
}
if (vs <= v) {
if (vo.getForeignKey() == null) {
for (int j = vo.getPrimaryKey(); j > 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
break;
}
}
}
break;
}
}
if (vo.getImportVoList() != null && vo.getImportVoList().size() > 0) {
for (MatMaterialBomImportVo matMaterialBomImportVo : vo.getImportVoList()) {
treeData(matMaterialBomImportVo, segmentedDatum);
}
}
}说明:我这里传进来的vo是没有设置id和父id的,只对数据源做了树拆分处理,因为业务需求,后面并没有使用这套递归的方法组装为树,所以递归代码可能有点误差,仅供参考
总结
这里主要针对导入数据为树形,以及没有具体的id以及父id的处理,在拆分开没棵树的数据并且每棵树的节点有了父子关系后就可以通过正常的流程处理
加载全部内容