Python Requests库
阿呆小记 人气:0一、Requests库的7个主要的方法
1.request() | 构造请求,支撑以下的基础方法 |
2.get() | 获取HTML页面的主要方法,对应于http的get |
3.head() | 获取HTML页面的头部信息的主要方法,对应于http的head |
- | |
4.post() | 向HTML提交post请求的方法,对应于http的post |
- | |
- | |
5.put() | 向HTML提交put请求的方法,对应于http的put |
6.patch() | 向HTML提交局部修改的请求,对应于http的patch |
7.delete() | 向HTML提交删除请求,对应于http的delete |
以下代码是描述的request方法中的13个控制访问参数:
import requests
# **kwargs:控制访问的参数,均为可选项,不仅仅是针对request,其他六中方法依旧适用
# params:字典或字节序列,作为参数增加到URL中,可以通过该参数筛选数据
kv = {"key1":"value1","key2":"value2"}
r = requests.request('GET','http://python123.io/ws',params=kv)
print(r.url)
# http://python123.io//ws?key1=value1&key2=value2
# data:字典、字节序列或文件对象,作为Request的内容;提交时,作为数据内容添加到当前的连接下
kv = {"key1":"value1","key2":"value2"}
r = requests.request('POST','http://python123.io/ws',params=kv)
body = '主体内容'
r = requests.request('POST','http://python123.io/ws',params=body)
# json:JSON格式的数据,作为Request的内容
kv = {"key1":"value1"}
r = requests.request('POST','http://python123.io/ws',json=kv)
# headers:字典,HTTP定制头,模拟需要的浏览器来进行访问
hd = {"user-agent":"Chrome/10"}
r = requests.request('POST','http://python123.io/ws',headers=hd)
# cookies:字典或CookieJar,Request中的cookie
# auth:元组,支持HTTP认证功能
# files:字典类型,传输文件;将某个文件提交到连接上
fs = {"file":open('data.xls','rb')}
r = requests.request('POST','http://python123.io/ws',file=fs)
# timeout:设定超时时间,秒为单位;在规定的时间内没有接收到响应将会显示timeout异常
r = requests.request('POST','http://www.baidu.com',timeout=10)
# proxies:字典类型,设定访问代理服务器,可以增加登录认证
pxs = {'http':'http://user:pass@10.10.10.1:1234', #当我们进入HTTP协议的网站时增加登录认证
'https':'https://10.10.10.1.4321' } #当我们进入HTTPS协议的网站时,直接使用代理服务器的IP地址;可以有效掩盖爬虫的原IP地址
r = requests.request('GET','http://python123.io/ws',proxies=pxs)
# allow_redirects:True/False,默认为True,重定向开关
# stream:True/False,默认为True,获取内容立刻下载的开关
# verify:True/False,默认为True,认证SSL证书开关
# cert:本地SSL证书路径二、Response对象的属性
status_code | HTTP请求的返回状态码,200表示成功,400表示失败 |
text | HTTP响应内容的字符串形式,即URL对应的页面内容 |
encoding | 从HTTPheader中猜测的响应内容编码方式 |
- | |
apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
- | |
content | HTTP响应内容的二进制形式 |
import requests
#构造一个向服务器请求资源的Response对象
r = requests.get(url="http://www.baidu.com")
print(r.status_code) #打印请求状态码
#200
print(type(r)) #打印请求对象类型
#<class 'requests.models.Response'>
print(r.headers) #打印请求对象的头部信息
#{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sat, 27 Jun 2020 09:03:41 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:32 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
print(r.text)
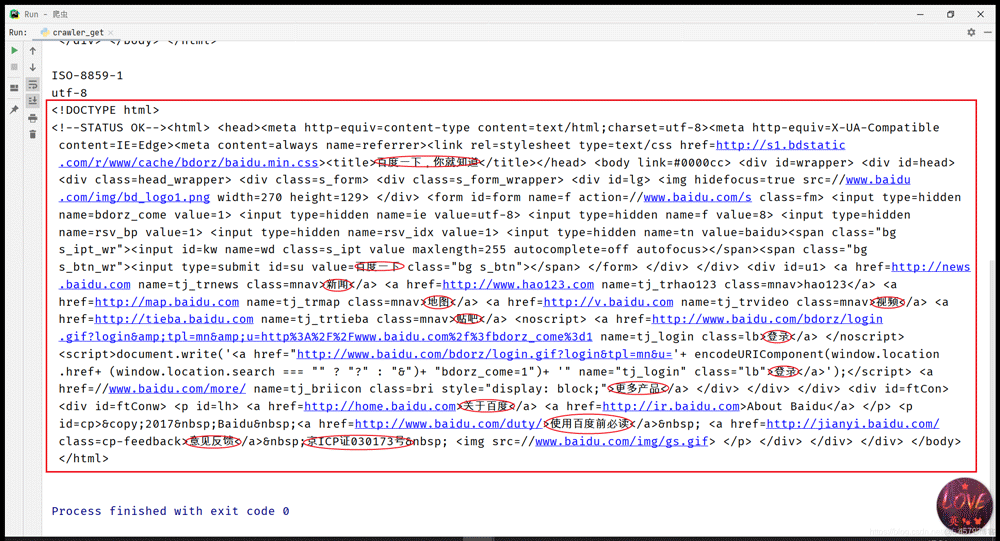
print(r.encoding) #ISO-8859-1
print(r.apparent_encoding) #备用编码utf-8
r.encoding = "utf-8"
print(r.text)

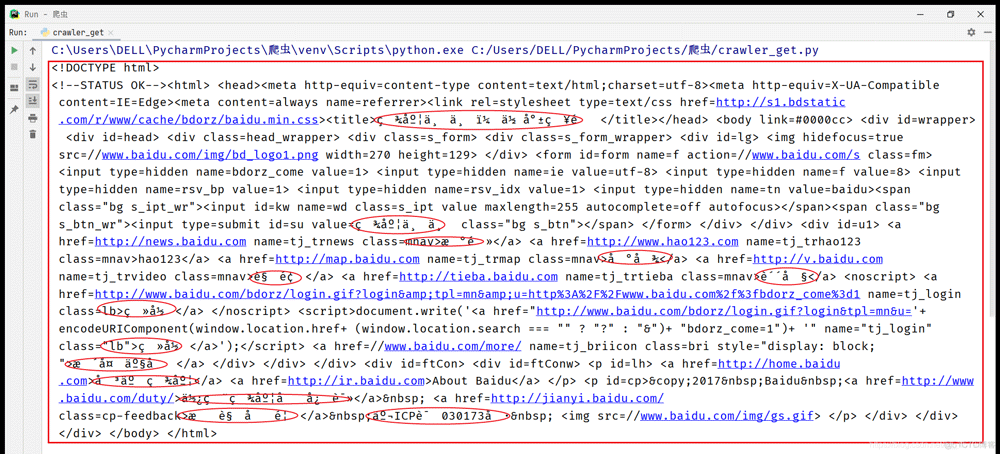
直接解析会出现乱码,将字符设为apparent_encoding时会结局问题。
三、爬取网页通用代码
try: r = requests.get(url,timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "产生异常!"
作用:r.raise_for_status()函数判断当前请求返回状态码,当返回状态码不为200时,产生异常并能够被except捕获
import requests # (定义方法)封装函数 def getHTMLText(url): try: r = requests.get(url,timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "代码错误,产生异常!" if __name__ =="__main__": url = "http://www.baidu.com" print(getHTMLText(url)) #正常显示爬取的页面信息 if __name__ =="__main__": url = "www.baidu.com" #缺失了 print(getHTMLText(url)) #代码错误,产生异常!

四、Resquests库的常见异常
requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
requests.HTTPError | HTTP错误异常 |
requests.URLRequired | URL缺失异常 |
requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
requests.ConnectTimeout | 连接远程服务器超时异常 |
requests.Timeout | 请求URL超时,产生超时异常 |
五、Robots协议展示
import requests # (定义方法)封装函数 def getHTMLText(url): try: r = requests.get(url,timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "代码错误,产生异常!" if __name__ =="__main__": url = "http://www.baidu.com/robots.txt" print(getHTMLText(url)) #正常显示爬取的页面信息,显示出robots协议对于不同类型爬虫的限制
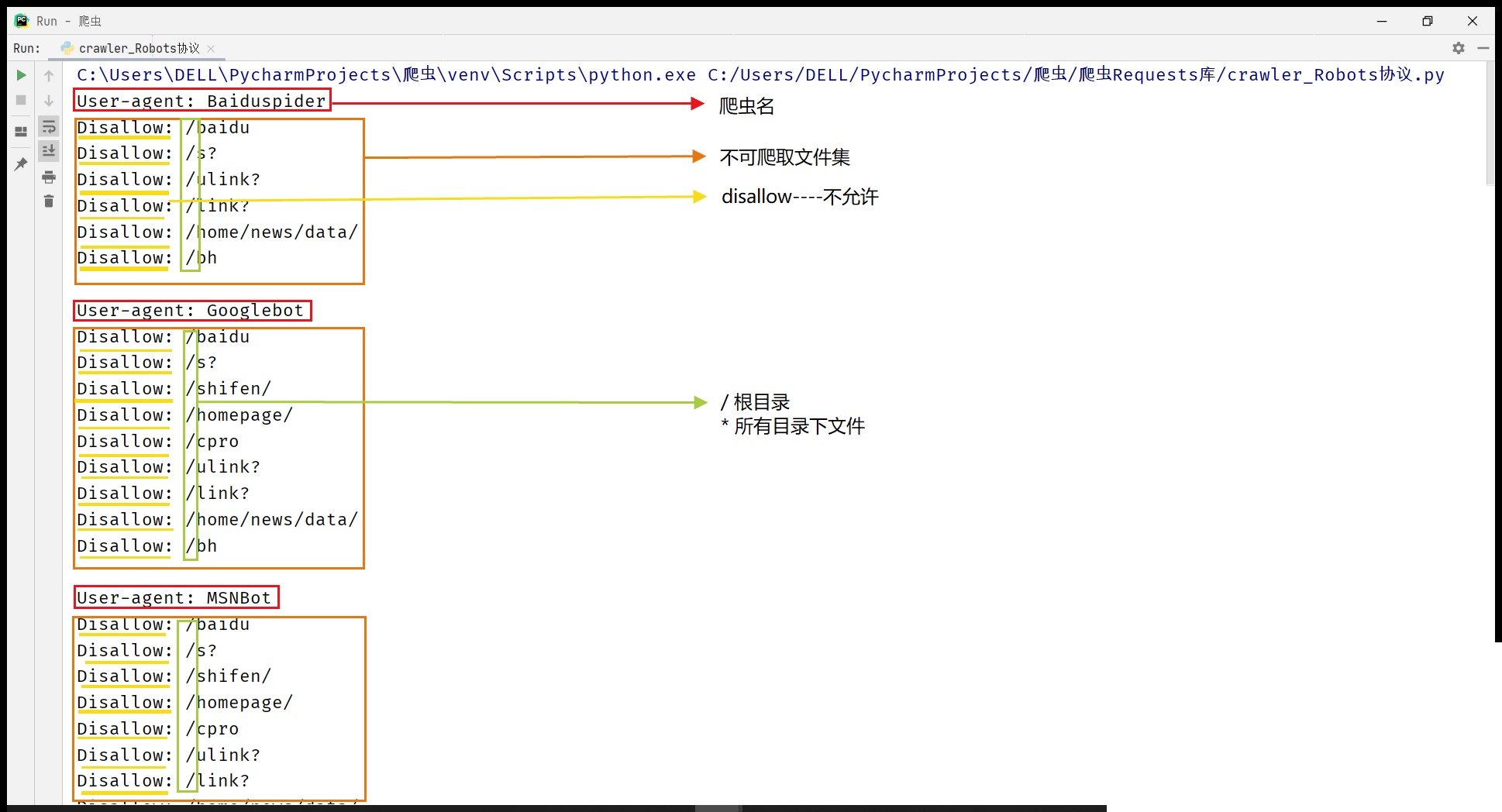
六、案例展示
1.爬取京东商品信息
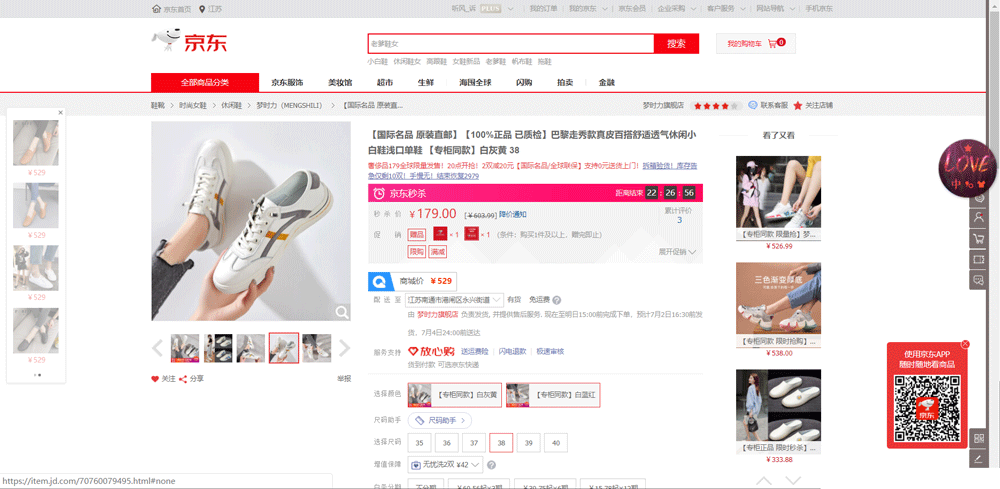
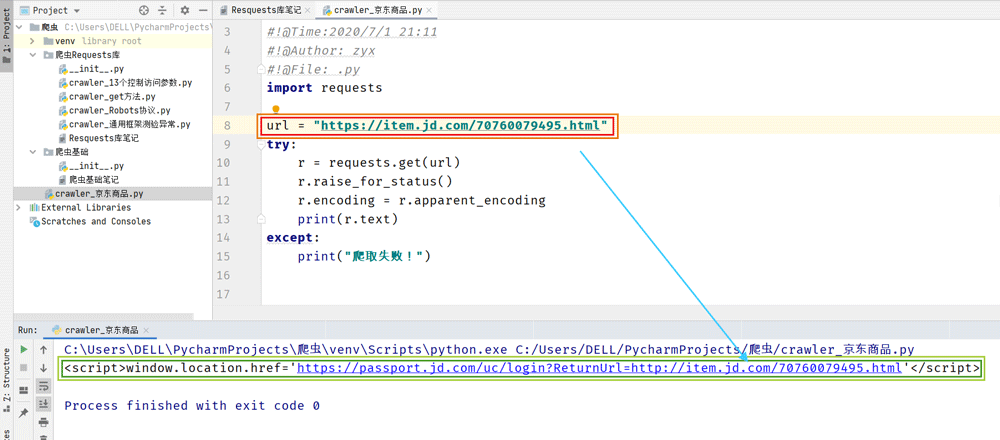
在爬取后,我们发现在控制台中返回了带有login?的一个href,并没有具体的信息内容。但是在爬取主页时,可以直接获取主页具体信息。个人认为是由于无法识别是否已经登陆而导致的,后续学习中会跟进知识点及解决方法。(若有大佬会的,感谢评论!)
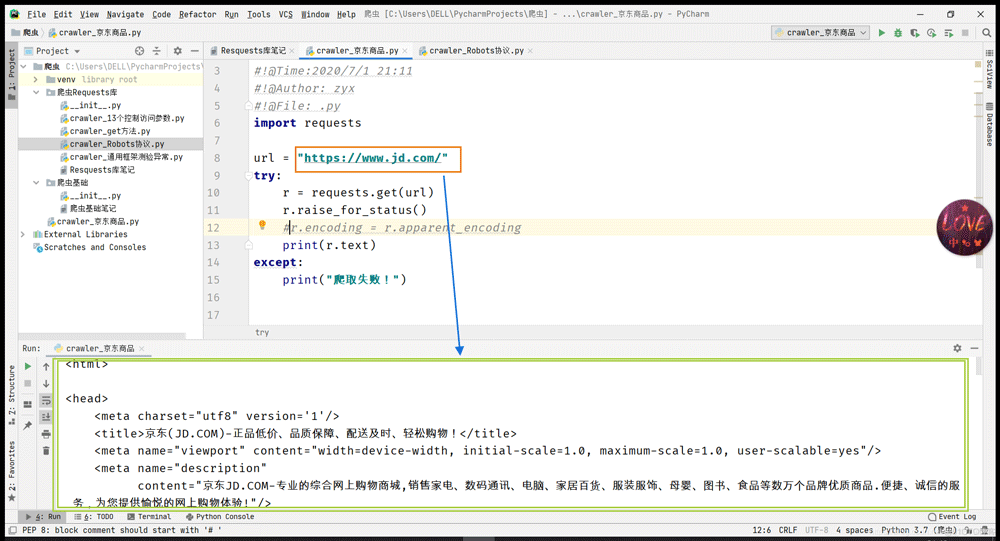
2.爬取网上图片并保存
import requests
import os
url = "http://image.ngchina.com.cn/2019/0523/20190523103156143.jpg"
root = "F:/图片/" #根目录
path = root + url.split('/')[-1] #以最后一个/后的文字命名
try:
if not os.path.exists(root): #如果不存在根目录文件,则创建根目录文件夹
os.mkdir(root) #该方法只能创建一级目录,如要创建多层,可以遍历循环创建
if not os.path.exists(path):
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content) #r.content返回的是2进制编码,将其写入
f.close()
print("文件已成功保存!")
else:
print("文件已存在~")
except:
print("爬取失败!!!")
加载全部内容