python爬取pixiv图片
EastMage 人气:0自从接触python以后就想着爬pixiv,之前因为梯子有点问题就一直搁置,最近换了个梯子就迫不及待试了下。
爬虫无非request获取html页面然后用正则表达式或者beautifulsoup之类现成工具截取我们想要的页面,pixiv也不例外。
首先我们来实现模拟登陆,虽然大多数情况不需要我们实现模拟登录,但如果你是会员之类的,登录和不登录网页就有区别。思路是登录时抓包抓到post请求,看pixiv构建的post的数据表格是什么格式,我们根据这个格式构建form,然后调用post方法去请求,再保存到session中,之后访问相关页面用session替代requests即可。
可以看到pixiv登录的网址如下,直接复制:

抓包找到提交数据的请求:
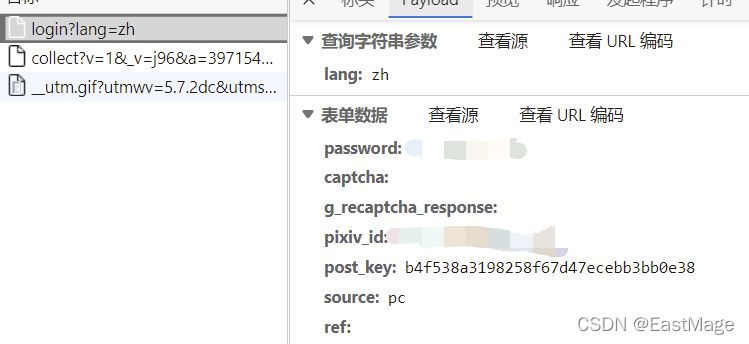
![]()
可以看到表单数据主要是这几个,经过几次尝试,我们在模拟的时候只需要构建password、pixiv_id、post_key再加上一个return_to(第二张)即可。pixiv_id就是我们的账号,password是密码,return_to照着填就行,但这个post_key却是随机的。
但我们也有办法,它是我们每次访问登录页面时动态生成的,这就好办了,再登录前先爬取一次登录前的页面,找到postkey。
看到下图红圈里面:
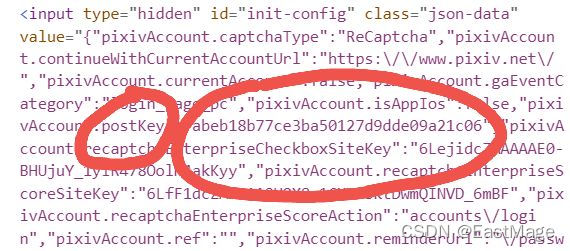
那就可以直接正则爬取:
def get_postkey():
login_url='https://accounts.pixiv.net/login?return_to=https%3A%2F%2Fwww.pixiv.net%2F&lang=zh&source=pc&view_type=page'
response=requests.get(url=login_url,headers=headers,verify=False)
html=response.text
# print(html)
postkey=re.findall('"pixivAccount.postKey":"(.*?)","pixivAccount.recaptchaEnterpriseCheckboxSiteKey"',html)
return postkey[0]然后我们就可以构建数据包:
pixiv_id="账号" # 你的pixiv账号 password='xxxxx' # 你的pixiv密码 return_to='https://www.pixiv.net/' post_key=get_postkey()
实例化一个session对象,然后post提交就能完成模拟登陆:
session=requests.Session()
form_data={
'pixiv_id':pixiv_id,
'password':password,
'return_to':return_to,
'post_key':post_key
}
login_url1='https://accounts.pixiv.net/login?return_to=https%3A%2F%2Fwww.pixiv.net%2F&lang=zh&source=pc&view_type=page'
res=session.post(url=login_url1,headers=headers,data=form_data)
# 至此模拟登录成功到此模拟登录就成功了,接下来就是爬我们想要的图片,以爬排行榜为例:
打开排行榜页面,鼠标悬停图片,右键检查,可以找到对应的代码位置:
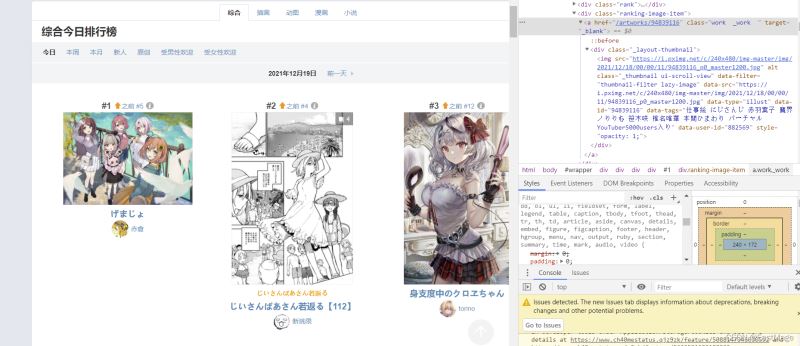
找到每张图片的相似结构,我们可以用BeautifulSoup 找到节点,然后正则爬我们想要的网址:
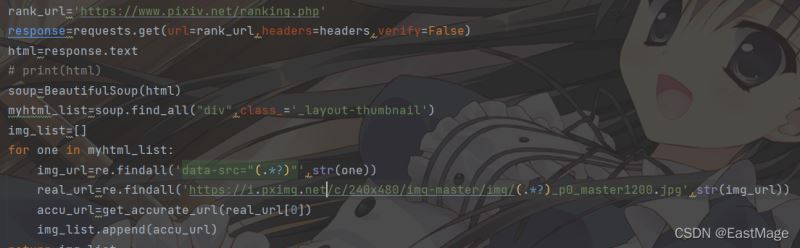
先找到包含每张图片各种信息的节点,通过类名查找,然后对于每一个节点进行正则提取,提取出对应图片的下载链接,不过需要特别注意的是,pixiv直接显示的图片源是骗你的,真正的图片链接的形式应该是:
https://i.pximg.net/img-original/img/xxxx/xx/xx/xx/xx/xx/xxxxxxxx_p0.png
这样的,直接把这个网址复制网页栏访问会显示403,因为pixiv限制了必须从pixiv网页点进这个网址,所以我们首先必须headers构建refer-to,然后通过排行榜提取到信息后还需要自己手动构建正确的网址:
headers = {'Referer': 'https://www.pixiv.net/',
}def get_accurate_url(url):
urll='https://i.pximg.net/img-original/img/' + str(url) + "_p0.jpg"
return urll这里的代码偷了个懒,全部当作jpg来处理,下载的时候再处理png的情况
下载的具体函数,我们对每一个网址的后续部分提取出来作名字,随机睡眠1到4秒防止pixiv认出我们是爬虫把我们ip给封了,之后就是对网址进行访问下载,这里如果访问返回的状态码是404说明它其实是个png格式的图片,所以对png格式的文件重新构建正确的网址即可:
def download(list,filename):
i=1
for url in list:
pic_name=re.findall("https://i.pximg.net/img-original/img/(.*?)_p0.jpg",str(url))
pic_name1=str(pic_name[0]).replace("/",".")
r = random.randint(1, 4)
time.sleep(r)
response=requests.get(url=url,headers=headers,verify=False)
if(response.status_code==404):
the_url='https://i.pximg.net/img-original/img/' + str(pic_name[0]) + "_p0.png"
response = requests.get(url=the_url, headers=headers, verify=False)
with open(path + filename + '/' + str(pic_name1) + '.png', 'wb') as f:
f.write(response.content)
print("第" + str(i) + "张图片已下载成功!!")
else:
with open(path + filename + '/' + str(pic_name1) + '.jpg', 'wb') as f:
f.write(response.content)
print("第" + str(i) + "张图片已下载成功!!")
i+=1最后就是成功下载排行榜的图片:
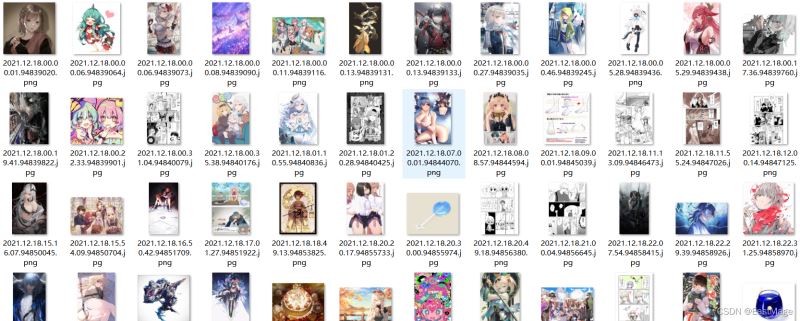
另外我在爬的时候发现pixiv很多网页获取时会隐藏body部分的内容,包括但不限于各个tag的网页和单个id图片的网页,一开始以为是没有登录的原因,但是实现登录后发现依然如此,推测可能是body部分内容是子网页或者javsscript生成之类的,反正前端有一万种方法达成这个目的,这个之后再研究怎么爬。
总结
加载全部内容