apache kafka消费者组
字母哥哥 人气:0一个错误:多线程使用单一消费者
下图显现了一种错误的使用KafkaConsumer的方法
- 创建多个线程用来消费kafka数据
- 多线程使用同一个KafkaConsumer对象
- 在单线程中使用这个KafkaConsumer对象,完成数据拉取、处理、提交偏移量。
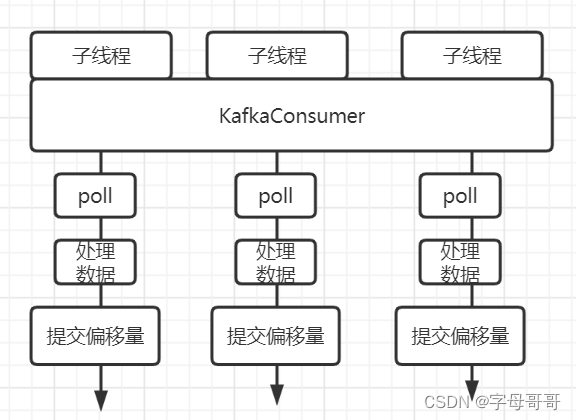
这种方式之所以错误的原因是:KafkaConsumer是线程不安全的,可能出现把同一批数据既给线程A处理,也交给线程B处理重复消费的问题。
一个误区:多线程就是消费者组
下图中体现的是一种正常的KafkaConsumer使用方式
- 使用一个KafkaConsumer拉取数据
- 拉取数据后将一个批次的数据交给一个线程去处理
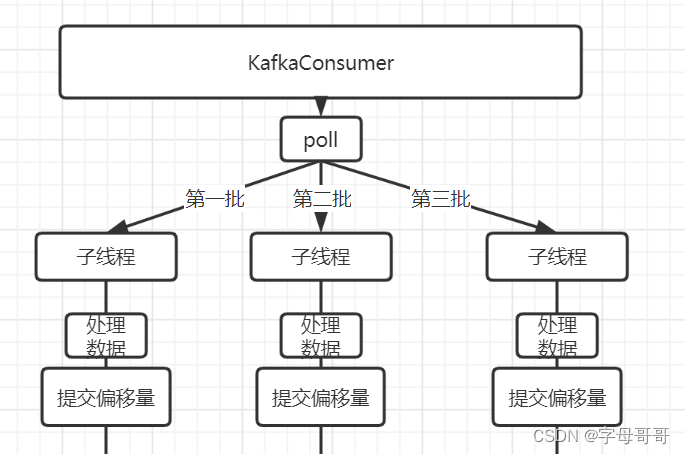
这个处理方式不是错误,但是他只是一个消费者在消费kafka消息队列中的数据,不是消费者组的方式消费数据。无法充分利用kafka分区提升消息处理的吞吐量。
常规正确做法:使用线程池实现消费者组
下面的方法是常规的正确实现方式
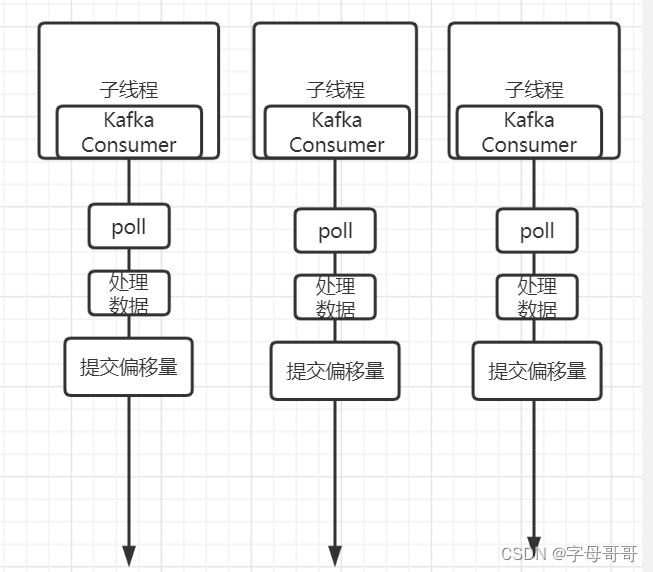
- 因为KafkaConsumer是线程不安全的,所以不能跨线程使用KafkaConsumer
- 每个线程持有一个KafkaConsumer对象
- 多个线程的实现可以使用线程池,线程池的线程数量等于消费者组内消费者的数量
public class MyConsumerGroup {
public void groupConsumer(){
ExecutorService executorService = Executors.newFixedThreadPool(6);
for (int i = 0; i < 6; i++) {
MyConsumer myConsumer = new MyConsumer();
executorService.execute(myConsumer);
}
}
}MyConsumer方法需要实现Runnable接口,并在run方法中调用MyConsumer#pollData。MyConsumer的代码参考本专栏的《消费者Java实现》( 集成apache kafka-clients实现数据消费者)
@Override
public void run() {
MyConsumer myConsumer = new MyConsumer();
myConsumer.pollData();
}加载全部内容