Pytorch LSTM输入输出参数
奥卡姆的剃刀 人气:01.Pytorch中的LSTM中输入输出参数
nn.lstm是继承nn.RNNBase,初始化的定义如下:
class RNNBase(Module):
...
def __init__(self, mode, input_size, hidden_size,
num_layers=1, bias=True, batch_first=False,
dropout=0., bidirectional=False):以下是Pytorch中的参数及其含义,解释如下:
input_size– 输入数据的大小,也就是前面例子中每个单词向量的长度hidden_size– 隐藏层的大小(即隐藏层节点数量),输出向量的维度等于隐藏节点数num_layers– recurrent layer的数量,默认等于1。bias– If False, then the layer does not use bias weights b_ih and b_hh. Default: Truebatch_first– 默认为False,也就是说官方不推荐我们把batch放在第一维,这个与之前常见的CNN输入有点不同,此时输入输出的各个维度含义为 (seq_length,batch,feature)。当然如果你想和CNN一样把batch放在第一维,可将该参数设置为True,即 (batch,seq_length,feature),习惯上将batch_first 设置为True。dropout– 如果非0,就在除了最后一层的其它层都插入Dropout层,默认为0。bidirectional– 如果设置为 True, 则表示双向 LSTM,默认为 False
2.输入数据(以batch_first=True,单层单向为例)
假设输入数据信息如下:
- 输入维度 = 28
nn.lstm中的API输入参数如下:
time_steps= 3 batch_first = True batch_size = 10 hidden_size =4 num_layers = 1 bidirectional = False
备注:先以简单的num_layers=1和bidirectional=1为例,后面会讲到num_layers与bidirectional的LSTM网络具体构造。
下在面代码的中:
lstm_input是输入数据,隐层初始输入h_init和记忆单元初始输入c_init的解释如下:
h_init:维度形状为 (num_layers * num_directions, batch, hidden_size):
- 第一个参数的含义num_layers * num_directions, 即LSTM的层数乘以方向数量。这个方向数量是由前面介绍的bidirectional决定,如果为False,则等于1;反之等于2(可以结合下图理解num_layers * num_directions的含义)。
batch:批数据量大小hidden_size: 隐藏层节点数
c_init:维度形状也为(num_layers * num_directions, batch, hidden_size),各参数含义与h_init相同。因为本质上,h_init与c_init只是在不同时刻的不同表达而已。
备注:如果没有传入,h_init和c_init,根据源代码来看,这两个参数会默认为0。
import torch from torch.autograd import Variable from torch import nn input_size = 28 hidden_size = 4 lstm_seq = nn.LSTM(input_size, hidden_size, num_layers=1,batch_first=True) # 构建LSTM网络 lstm_input = Variable(torch.randn(10, 3, 28)) # 构建输入 h_init = Variable(torch.randn(1, lstm_input.size(0), hidden_size)) # 构建h输入参数 -- 每个batch对应一个隐层 c_init = Variable(torch.randn(1, lstm_input.size(0), hidden_size)) # 构建c输出参数 -- 每个batch对应一个隐层 out, (h, c) = lstm_seq(lstm_input, (h_init, c_init)) # 将输入数据和初始化隐层、记忆单元信息传入 print(lstm_seq.weight_ih_l0.shape) # 对应的输入学习参数 print(lstm_seq.weight_hh_l0.shape) # 对应的隐层学习参数 print(out.shape, h.shape, c.shape)
输出结果如下:

输出结果解释如下:
(1)lstm_seq.weight_ih_l0.shape的结果为:torch.Size([16, 28]),表示对应的输入到隐层的学习参数:(4*hidden_size, input_size)。
(2)lstm_seq.weight_hh_l0.shape的结果为:torch.Size([16, 4]),表示对应的隐层到隐层的学习参数:(4*hidden_size, num_directions * hidden_size)
(3)out.shape的输出结果:torch.Size([10,3, 4]),表示隐层到输出层学习参数,即(batch,time_steps, num_directions * hidden_size),维度和输入数据类似,会根据batch_first是否为True进行对应的输出结果,(如果代码中,batch_first=False,则out.shape的结果会变为:torch.Size([3, 10, 4])),
这个输出tensor包含了LSTM模型最后一层每个time_step的输出特征,比如说LSTM有两层,那么最后输出的是![]() ,表示第二层LSTM每个time step对应的输出;另外如果前面对输入数据使用了torch.nn.utils.rnn.PackedSequence,那么输出也会做同样的操作编程packed sequence;对于unpacked情况,我们可以对输出做如下处理来对方向作分离output.view(seq_len, batch, num_directions, hidden_size), 其中前向和后向分别用0和1表示。
,表示第二层LSTM每个time step对应的输出;另外如果前面对输入数据使用了torch.nn.utils.rnn.PackedSequence,那么输出也会做同样的操作编程packed sequence;对于unpacked情况,我们可以对输出做如下处理来对方向作分离output.view(seq_len, batch, num_directions, hidden_size), 其中前向和后向分别用0和1表示。
h.shape输出结果是: torch.Size([1, 10, 4]),表示隐层到输出层的参数,h_n:(num_layers * num_directions, batch, hidden_size),只会输出最后一个time step的隐状态结果(如下图所示)
c.shape的输出结果是: torch.Size([1, 10, 4]),表示隐层到输出层的参数,c_n :(num_layers * num_directions, batch, hidden_size),同样只会输出最后一个time step的cell状态结果(如下图所示)
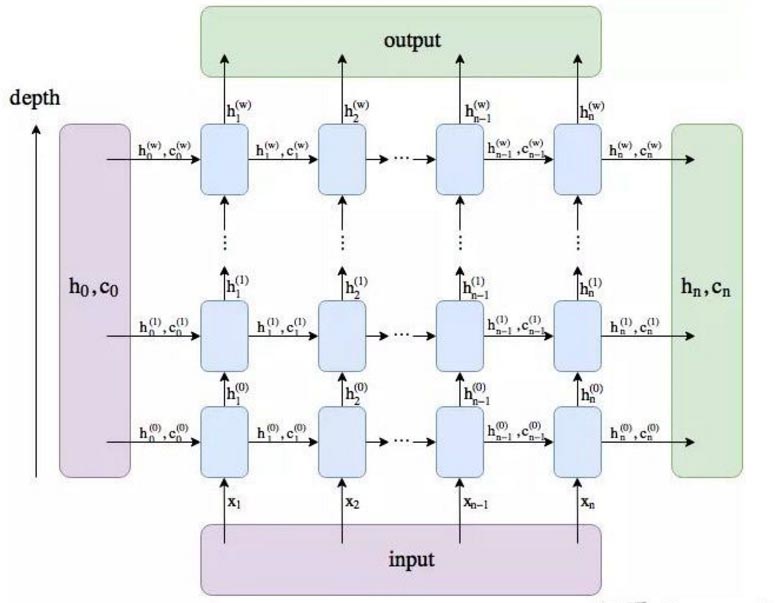
3.输入数据(以batch_first=True,双层双向)
'''
batch_first = True : 输入形式:(batch, seq, feature)
bidirectional = True
num_layers = 2
'''
num_layers = 2
bidirectional_set = True
bidirectional = 2 if bidirectional_set else 1
input_size = 28
hidden_size = 4
lstm_seq = nn.LSTM(input_size, hidden_size, num_layers=num_layers,bidirectional=bidirectional_set,batch_first=True) # 构建LSTM网络
lstm_input = Variable(torch.randn(10, 3, 28)) # 构建输入
h_init = Variable(torch.randn(num_layers*bidirectional, lstm_input.size(0), hidden_size)) # 构建h输入参数
c_init = Variable(torch.randn(num_layers*bidirectional, lstm_input.size(0), hidden_size)) # 构建c输出参数
out, (h, c) = lstm_seq(lstm_input, (h_init, c_init)) # 计算
print(lstm_seq.weight_ih_l0.shape)
print(lstm_seq.weight_hh_l0.shape)
print(out.shape, h.shape, c.shape)输出结果如下:

Pytorch-LSTM函数参数解释 图解
最近在写有关LSTM的代码,但是对于nn.LSTM函数中的有些参数还是不明白其具体含义,学习过后在此记录。
为了方便说明,我们先解释函数参数的作用,接着对应图片来说明每个参数的具体含义。
torch.nn.LSTM函数
LSTM的函数
class torch.nn.LSTM(args, *kwargs) # 主要参数 # input_size – 输入的特征维度 # hidden_size – 隐状态的特征维度 # num_layers – 层数(和时序展开要区分开) # bias – 如果为False,那么LSTM将不会使用偏置,默认为True。 # batch_first – 如果为True,那么输入和输出Tensor的形状为(batch, seq_len, input_size) # dropout – 如果非零的话,将会在RNN的输出上加个dropout,最后一层除外。 # bidirectional – 如果为True,将会变成一个双向RNN,默认为False。
LSTM的输入维度为 (seq_len, batch, input_size) 如果batch_first为True,则输入形状为(batch, seq_len, input_size)
seq_len是文本的长度;batch是批次的大小;input_size是每个输入的特征纬度(一般是每个字/单词的向量表示;
LSTM的输出维度为 (seq_len, batch, hidden_size * num_directions)
seq_len是文本的长度;batch是批次的大小;hidden_size是定义的隐藏层长度num_directions指的则是如果是普通LSTM该值为1; Bi-LSTM该值为2
当然,仅仅用文本来说明则让人感到很懵逼,所以我们使用图片来说明。
图解LSTM函数
我们常见的LSTM的图示是这样的:

但是这张图很具有迷惑性,让我们不易理解LSTM各个参数的意义。具体将上图中每个单元展开则为下图所示:
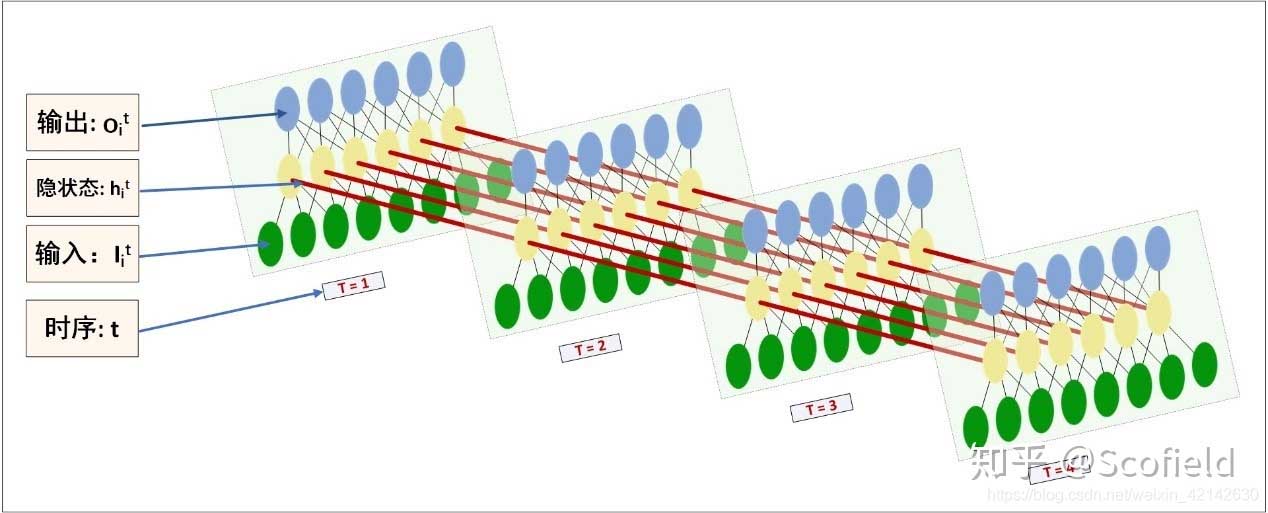
input_size: 图1中 xi与图2中绿色节点对应,而绿色节点的长度等于input_size(一般是每个字/单词的向量表示)。
hidden_size: 图2中黄色节点的数量
num_layers: 图2中黄色节点的层数(该图为1)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容