Pandas添加行列数据
CHD托马斯 人气:4前言
发现自己学习python 的各种库老是容易忘记,所有想利用这个平台,记录和分享一下学习时候的知识点,以后也能及时的复习,最近学习pandas,那我们来看看pandas添加数据的一些方法
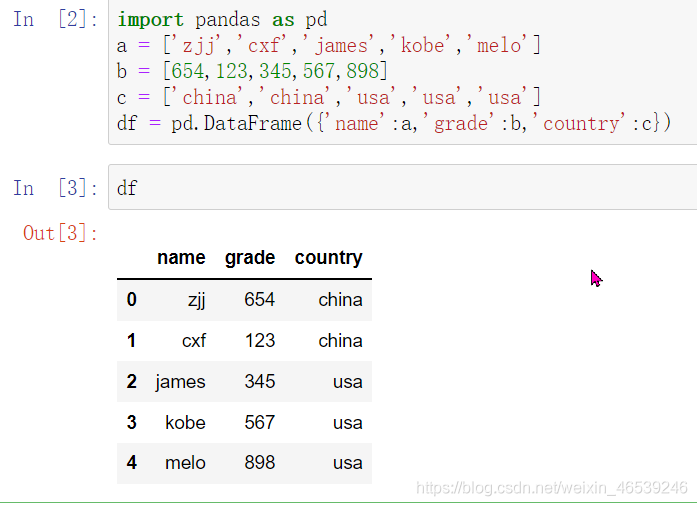
创建一个dataframe
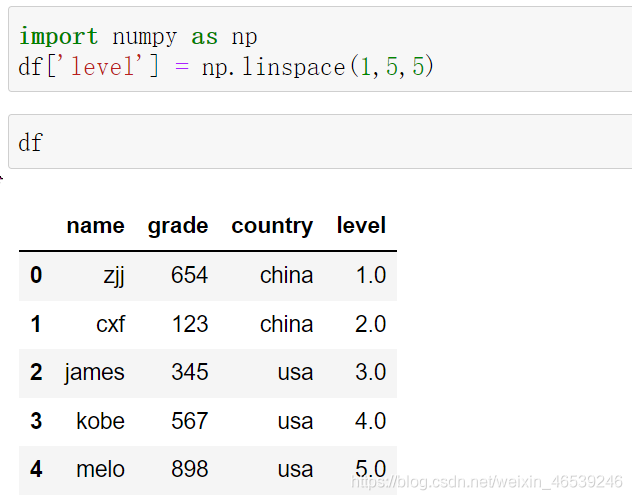
1. 增加列数据
为dataframe增加一列新数据,需要确保增加列的长度与原数据保持一致
如果是增加一列相同数据可以直接输入
df['level'] = 1
插入的数据是需要通过源数据进行计算的(eval这个方法感觉比较好用)
df.eval('grade_level = grade * level',inplace = True)

使用insert函数可以在指定列添加列数据,这个函数有好几个参数,使用更加灵活
df.insert(loc, column, value, allow_duplicates=False)
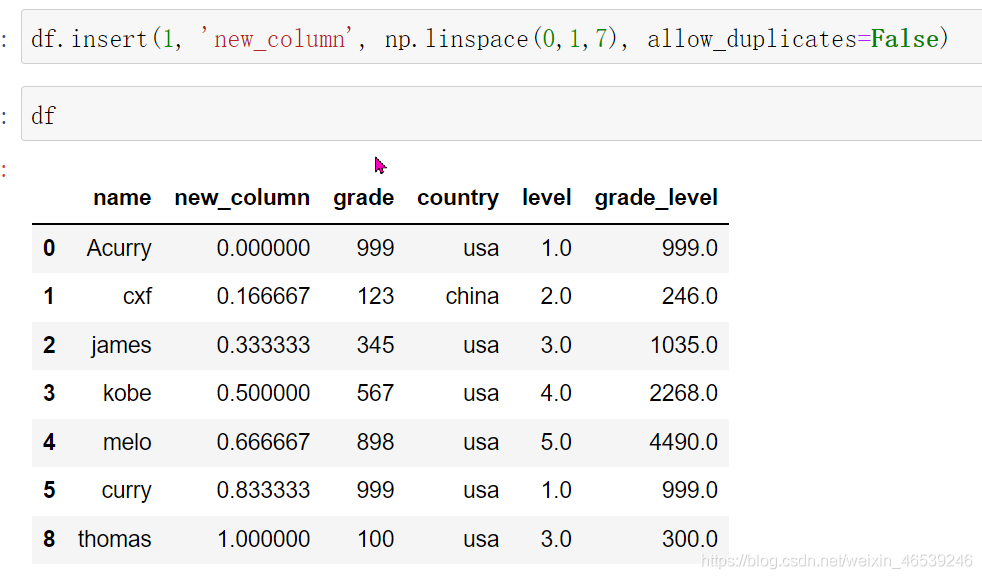
增加列数据的方法还有很多,我只把自己比较常用的记录了下来
2. 增加行数据
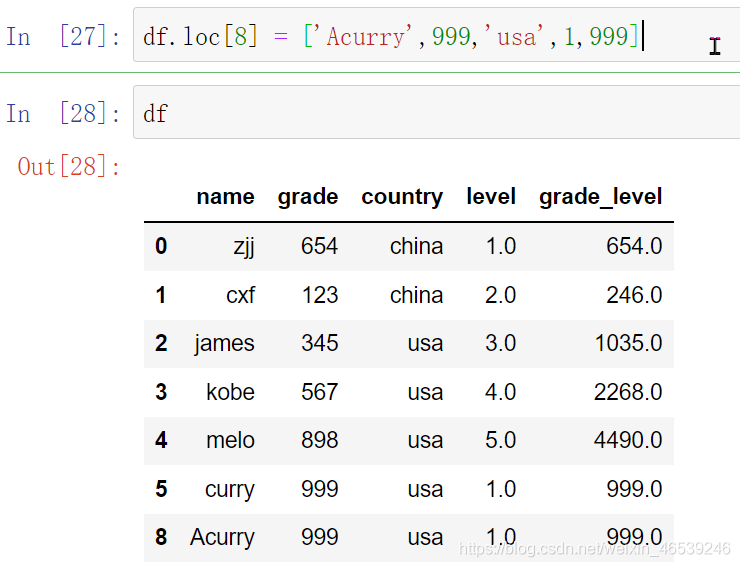
比较多的方法有 loc 、iloc、append都行,先看loc这个方法,它是通过 df.loc[index名称] = [对应的数据],这个方法要主要index如果是与原表中有重复,则会将原数据修改,如果没有重复的话,就是在最后面添加对应数据,其中的index名称是根据输入的写入,需要注意!
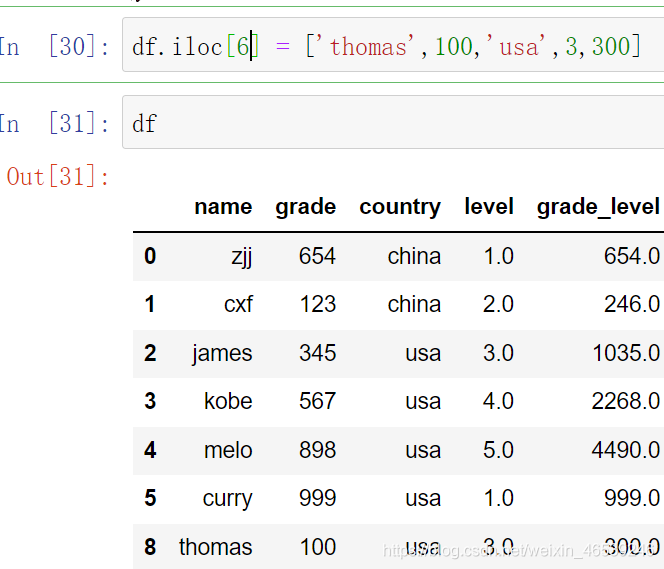
第二个是通过df.iloc[index位置] = [对应数据] 进行修改这个方法是对原有数据进行修改,并不是增加一行数据
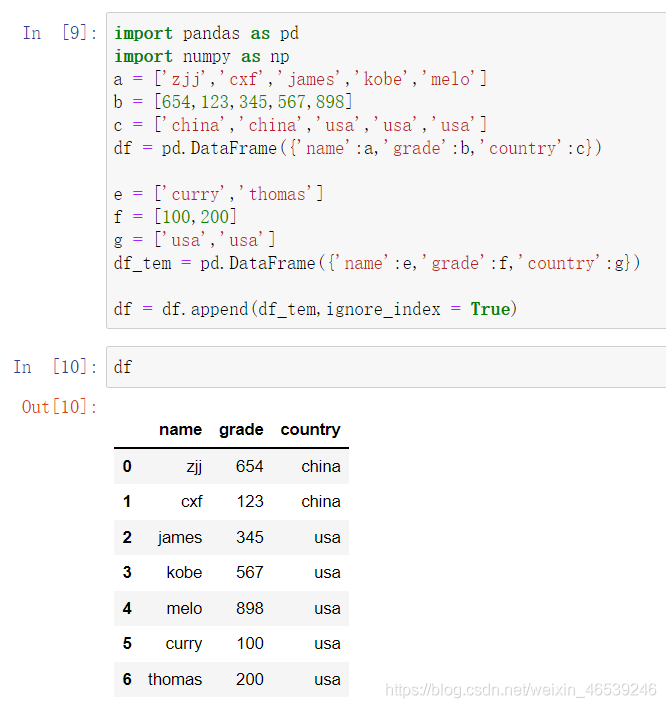
使用append()函数添加一行数据,其中ignore_index=True,否则报错

append()往往做法比较多的是添加一个另外一个dataframe的数据到原来数据上,爬虫时候用得比较多,将每一页的数据保存到一个临时的dataframe中,将这个临时的dataframe数据插入到总的dataframe后面,最后得到总的数据,且效率较高
当然还有concat、merge等方法可以达到相同的效果,下次有机会在继续学习
补充:pandas根据现有列新添加一列
pandas中一个Dataframe,经常需要根据其中一列再新建一列,比如一个常见的例子:需要根据分数来确定等级范围,下面我们就来看一下怎么实现。
def getlevel(score):
if score < 60:
return "bad"
elif score < 80:
return "mid"
else:
return "good"
def test():
data = {'name': ['lili', 'lucy', 'tracy', 'tony', 'mike'],
'score': [85, 61, 75, 49, 90]
}
df = pd.DataFrame(data=data)
# 两种方式都可以
# df['level'] = df.apply(lambda x: getlevel(x['score']), axis=1)
df['level'] = df.apply(lambda x: getlevel(x.score), axis=1)
print(df)
上面代码运行结果
name score level
0 lili 85 good
1 lucy 61 mid
2 tracy 75 mid
3 tony 49 bad
4 mike 90 good
要实现上面的功能,主要是使用到dataframe中的apply方法。
上面的代码,对dataframe新增加一列名为level,level由分数一列而来,如果小于60分为bad,60-80之间为mid,80以上为good。
其中axis=1表示原有dataframe的行不变,列的维数发生改变。
总结
加载全部内容