python matplotlib绘制散点图
王小王_123 人气:0散点图
散点图是指在 回归分析中,数据点在直角坐标系平面上的 分布图,散点图表示因变量随 自变量而 变化的大致趋势,据此可以选择合适的函数 对数据点进行 拟合。
用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。散点图将序列显示为一组点。值由点在 图表中的位置表示。类别由图表中的不同标记表示。散点图通常用于比较跨类别的聚合数据。
下面给出一个散点图的具体代码案例
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.figure(figsize=(9,5), # (宽度 , 高度) 单位inch
dpi=120, # 清晰度 dot-per-inch
# facecolor='#CCCCCC', # 画布底色
# edgecolor='black',linewidth=0.2,frameon=True, # 画布边框
#frameon=False # 不要画布边框
)
# 设置全局中文字体
plt.rcParams['font.sans-serif'] = 'KaiTi' # 设置全局字体为中文 楷体
plt.rcParams['axes.unicode_minus'] = False # 不使用中文减号
#读取数据
crime=pd.read_csv("crimeRatesByState2005.csv")
print (list(crime.murder))#转化成列表
#删除state为United States的数据
crime2 = crime[crime.state != "United States"]
#删除state为District of Columbia的数据
crime2 = crime2[crime2.state != "District of Columbia" ]
z = list(crime2.population/10000)#取人口数据
#colors = np.random.rand(len(list(crime2.murder)))#根据谋杀率随机去颜色
cm = plt.cm.get_cmap('RdYlBu')#使用色谱RdYlBu
plt.scatter(list(crime2.murder), list(crime2.burglary), s=z,c=z,cmap = cm, linewidth = 0.5, alpha = 0.5)#绘制散点图
plt.xlabel("murder")
plt.ylabel("burglary")
plt.show()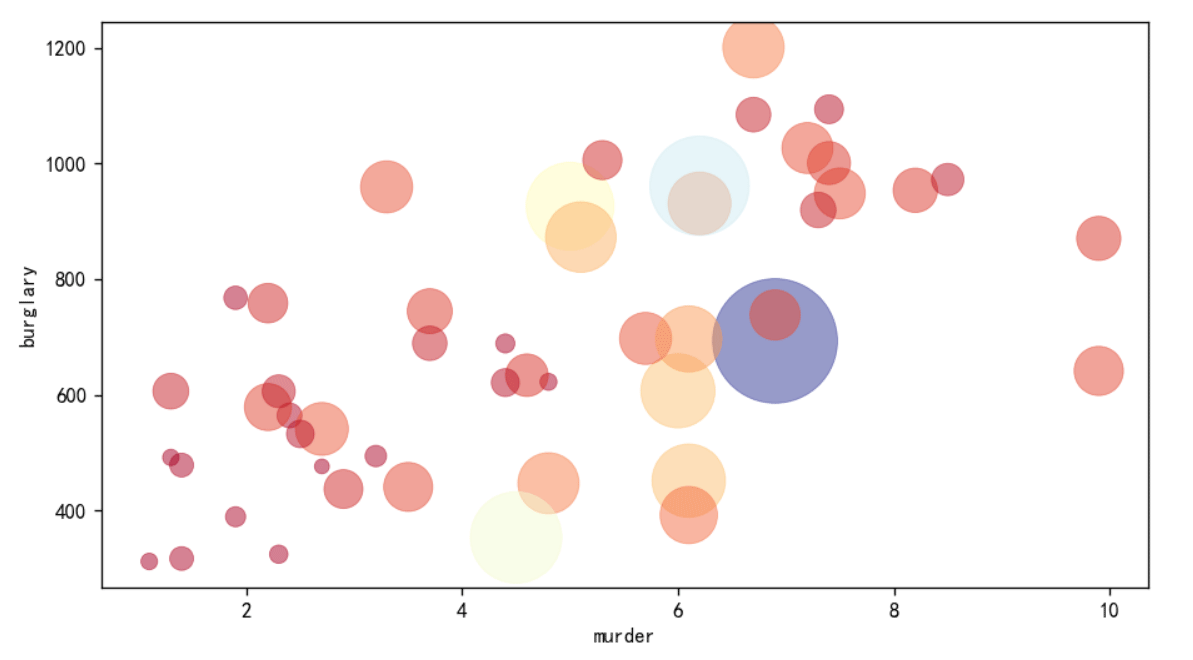
散点图一行代码显示
# 读取数据
df = pd.read_csv('iris.csv')
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length']
y = df['sepal_width']
# 根据X,Y值画散点图
plt.scatter(x,y)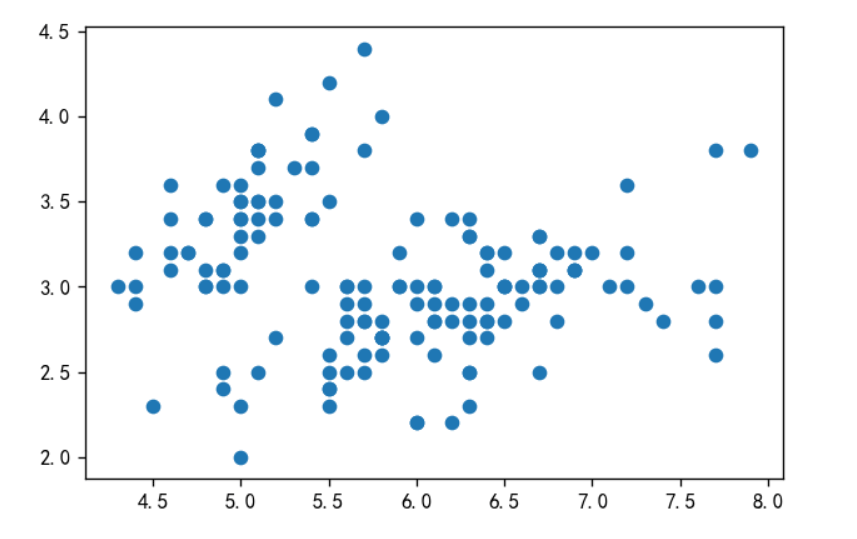
加颜色的散点图
# 读取数据
df = pd.read_csv('iris.csv')
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length']
y = df['sepal_width']
c = df['species'].map({'setosa':'r','versicolor':'g','virginica':'b'})
# 根据X,Y值画散点图, 用不同的颜色标识不同的分类
plt.scatter(x,y, c=c)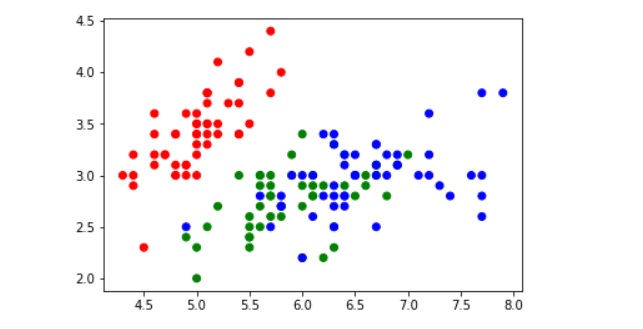
颜色深浅表示数值大小
# 读取数据
df = pd.read_csv('iris.csv')
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length']
y = df['sepal_width']
c = df['petal_length']
# 根据X,Y值画散点图, 用颜色的深浅表示花萼的长度
plt.scatter(x,y, c=c, cmap=plt.cm.RdYlBu)
散点图显示颜色和大小
# 读取数据
df = pd.read_csv('iris.csv')
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length'] # x 轴坐标
y = df['sepal_width'] # y 轴坐标
c = df['petal_length'] # 颜色color
s = df['petal_width'] # 大小size
# 根据X,Y值画散点图, 用颜色的深浅表示花萼的长度,用大小表示花萼的宽度
plt.figure(figsize=(5,5),dpi=100)
#plt.scatter(x,y, c=c, s=50) # 可以是标量,那么所有的点都一样
plt.scatter(x,y, c=c, s=s*30)
自定义图表散点图
# 读取数据
df = pd.read_csv('iris.csv')
def get_xycs(df):
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length'] # x 轴坐标
y = df['sepal_width'] # y 轴坐标
c = df['petal_length'] # 颜色color
s = df['petal_width'] # 大小size
return x,y,c,s
markers = {'setosa':'o', 'versicolor':'D', 'virginica':'*'}
# 根据X,Y值画散点图, 用颜色的深浅表示花萼的长度,用大小表示花萼的宽度, 每组数据只能是一种点样式
plt.figure(figsize=(5,5),dpi=100)
#plt.scatter(x,y, c=c, s=50) # 可以是标量,那么所有的点都一样
for sp in df['species'].unique():
x,y,c,s = get_xycs(df[df['species']==sp])
plt.scatter(x,y, c=c, s=s*30, cmap=plt.cm.seismic, marker=markers[sp],label=sp)
plt.legend()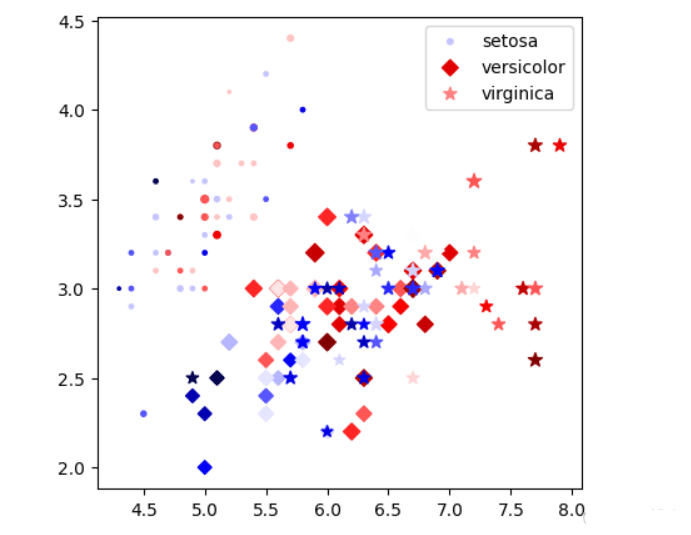
散点图万能模板
# 读取数据
df = pd.read_csv('iris.csv')
def get_xycs(df):
# 平面坐标系的位置只能表示2维数据
x = df['sepal_length'] # x 轴坐标
y = df['sepal_width'] # y 轴坐标
c = df['petal_length'] # 颜色color
s = df['petal_width'] # 大小size
return x,y,c,s
markers = {'setosa':'o', 'versicolor':'D', 'virginica':'*'}
# 根据X,Y值画散点图, 用颜色的深浅表示花萼的长度,用大小表示花萼的宽度, 每组数据只能是一种点样式
plt.figure(figsize=(5,5),dpi=100)
#plt.scatter(x,y, c=c, s=50) # 可以是标量,那么所有的点都一样
for sp in df['species'].unique():
x,y,c,s = get_xycs(df[df['species']==sp])
plt.scatter(x,y, s=s*30, cmap=plt.cm.seismic, marker=markers[sp],label=sp)
plt.legend()
其他模板
### 在二维坐标系上,位置表示(x,y)二维数据
x = df.sepal_length # x 表示花瓣长
y = df.sepal_width # y 表示花瓣宽
s = (df.petal_length * df.petal_width)*np.pi # s(size) 表示花萼面积
c = (df.petal_length * df.petal_width)*np.pi
plt.scatter(x,y,s=s*5, c=c,cmap=plt.cm.RdYlBu_r)
plt.xlabel('sepal_length')
plt.ylabel('sepal_width')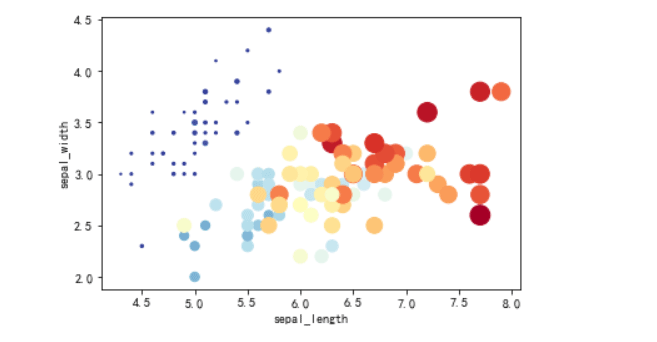
# 在二维坐标系上,位置表示(x,y)二维数据
x = df.sepal_length # x 表示花瓣长
y = df.sepal_width # y 表示花瓣宽
s = (df.petal_length * df.petal_width)*np.pi # s(size) 表示花萼面积
#print(df.species)
#colormap = {"setosa":"#FF0000", "versicolor":"green", "virginica":"b"} # 定义一个字典将species字符串映射到颜色字符串上
colormap = {"setosa":1, "versicolor":5, "virginica":6} # 定义一个字典将species字符串映射到颜色字符串上
c = df.species.map(colormap)
#print(c)
plt.scatter(x,y,s=s*5, c=c,cmap=plt.cm.coolwarm, alpha=0.7, edgecolors='face')
plt.xlabel('sepal_length')
plt.ylabel('sepal_width')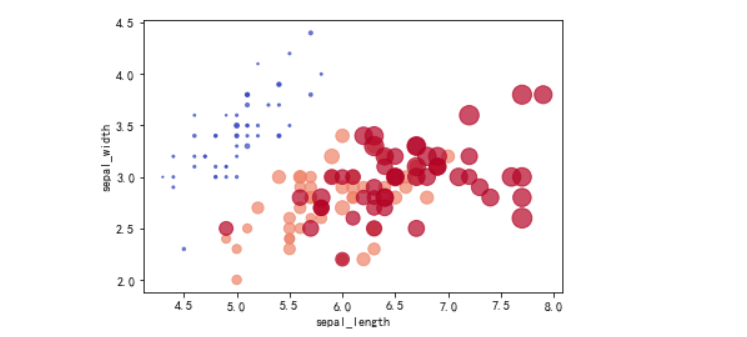
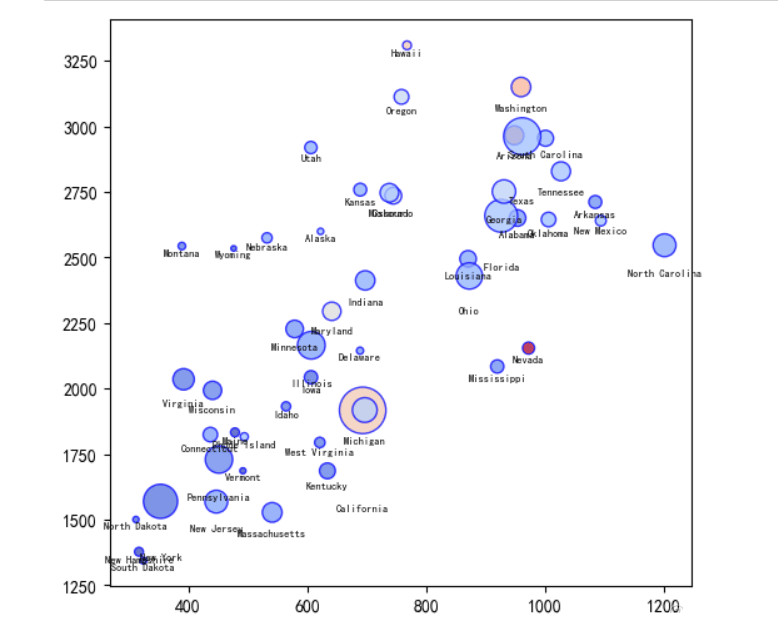
plt.scatter(df['burglary'], df['larceny_theft'], s=df['population']*2e-5, c=df['motor_vehicle_theft'], cmap=plt.cm.coolwarm, edgecolors='b', alpha=0.75) for idx,statename in df['state'].items(): plt.text(x=df['burglary'][idx],y=df['larceny_theft'][idx]-df['population'][idx]*2e-5*0.5,s=statename,fontsize=6,ha='center',va='top')
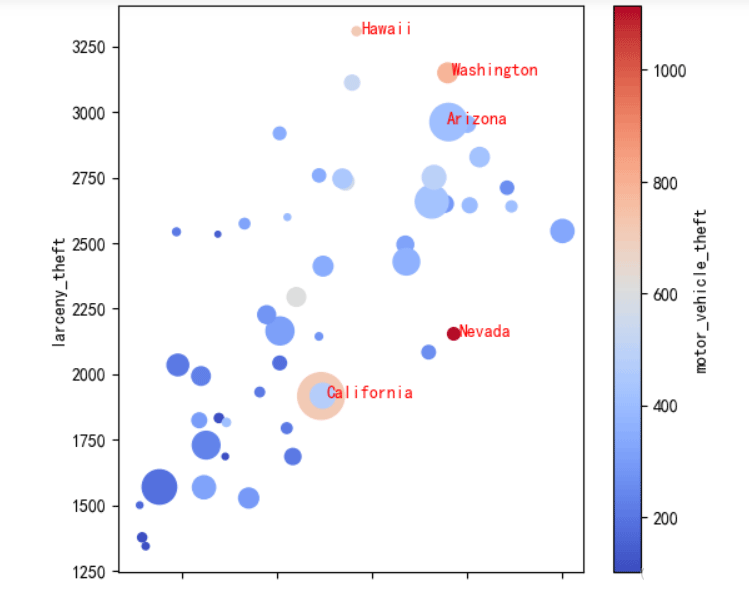
df.plot.scatter(x='burglary',y='larceny_theft',c='motor_vehicle_theft',cmap=plt.cm.coolwarm,s=df['population']*2e-5) for i in df.index: if i in top5_motor_theft_index: # 偷车贼最多的5个州 plt.text(df.loc[i,'burglary']+10, df.loc[i,'larceny_theft']-10, df.loc[i,'state'], color='red') # 一个文本框
加载全部内容