Matlab操作HDF5文件
学而时习之_不亦说乎 人气:5HDF5文件
在使用Matlab对数据进行预处理时,遇到了内存不足的问题,因为数据量太大,在处理完成以前内存已经爆满。如果使用Matlab的.m文件对文件进行存储的话,则需要将数据分割成多个文件,对后续的处理造成了不便。HDF5文件则是一种灵活的文件存储格式,有一个最大的好处就是在Matlab的处理过程中可以对它进行扩展写入,也就是说不是所有数据处理完以后一次写入,而是边处理边写入,极大的降低了对系统内存的要求。
HDF5文件类似与一个文件系统,使用这个文件本身就可以对数据集(dataset)进行管理。例如下图所示,HDF5文件中的数据集皆存储根目录/,在根目录下存在多个group,这样一些group类似与文件系统的文件夹,在它们可以存储别的group,也可以存储数据集。
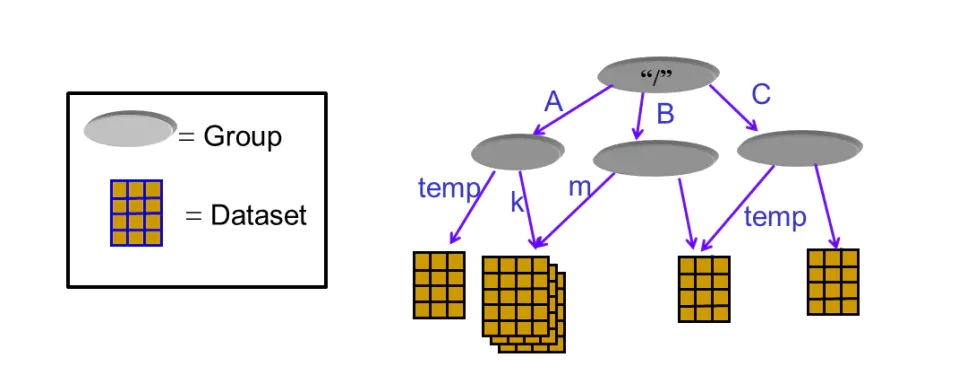
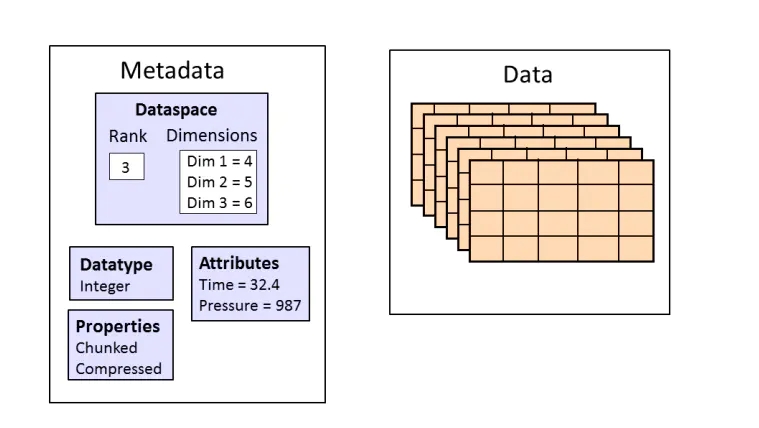
对于每一个dataset 而言,除了数据本身之外,这个数据集还会有很多的属性 attribute,。在hdf5中,还同时支持存储数据集对应的属性信息,所有的属性信息的集合就叫做metadata;
使用Matlab操作HDF5文件
使用Matlab创建HDF5文件
使用Matlab创建HDF5文件的函数是h5create,使用如下:
h5create(filename,datasetname,[30, 30 , 3, inf],'Datatype','single','ChunkSize',[30,30,3,1000])
filename为h5文件的文件名(不知道什么问题,在我的电脑上使用时,这个函数无法指定路径)。
datasetname则为数据集的名字,数据集名称必须以/开头,比如/G。
[30,30,3,inf]位数据集的大小,比如我的数据集为30x30大小的彩色图像,并且我希望数量能够扩展,那么就可以指定最后以为度为inf,以表示数量不限。
Datatype为数据类型
ChunkSize为数据存储的最小分块,为了让数据能够具有扩展性,所以为新来的数据分配一定的空间大小,对于一个非常大的数据,这个值设置大一点比较好,这样分块就会少一点。比如我的数据集中,30x30大小的彩色图像大概有10万个左右,那么1000个存储在一起较为合适,则chunksize设置为:[30,30,3,1000]。
使用Matlab写入HDF5
在创建了hdf5文件和数据集以后,则可以对数据集进行写操作以扩展里面的数据。使用Matlab写入HDF5文件的函数是h5write,使用如下:
h5write(fileName,datasetName,data,start,count);
fileName: hdf5文件名
datasetName:数据集名称,比如/Gdata:需要写入的数据,数据的维度应该与创建时一致,比如,设置的数据集大小为[30,30,3,inf],那么这里的data的前三个维度就应该是[30, 30, 3],而最后一个维度则是自由的
start:数据存储的起点,如果是第一次存,则应该为[1, 1, 1, 1](注意数据维度的一致性),如果这次存了10000个样本,也就是[30,30,3,10000],那么第二次存储的时候起点就应该为[1,1,1,10001]
count存储数据的个数,同样要根据维度来(其实就是数据的维度),这里为[30,30,3,10000]
使用Matlab查看HDF5文件信息
Matlab中可以使用h5info函数来读取HDF5文件的信息:
fileInfo = h5info(fileName);
然后通过解析fileInfo结构,则可以得到HDF5文件中的数据集名称、数据集大小等等必要信息。
使用Matlab读取HDF5中的数据集
Matlab中可以使用h5read函数来读取HDF5文件:
data = h5read(filename,datasetname,start,count)
filename:HDF5文件文件名
datasetname:数据集名称
start:从数据集中取数据的其实位置
count:取的数据数量
还是以上面的30x30的彩色图像为例,如果每次需要取1000个,那么第一次取时,start应该设置为[1, 1, 1, 1] ,count设置为:[30, 30 ,3 1000]。第二次取值时,start则应该设置为[1, 1, 1, 1001],count则设置为:[30, 30, 3, 1000]。
加载全部内容