Java连接Hadoop
wr456wr 人气:0实验环境
- hadoop版本:3.3.2
- jdk版本:1.8
- hadoop安装系统:ubuntu18.04
- 编程环境:IDEA
- 编程主机:windows
实验内容
测试Java远程连接hadoop
创建maven工程,引入以下依赖:
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>虚拟机的/etc/hosts配置

hdfs-site.xml配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/rDesk/hadoop-3.3.2/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>VM-12-11-ubuntu:50010</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/rDesk/hadoop-3.3.2/tmp/dfs/data</value>
</property>
</configuration>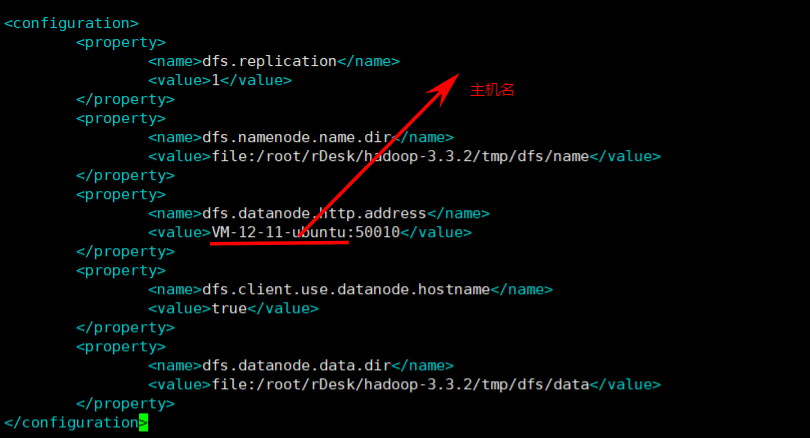
core-site.xml配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/rDesk/hadoop-3.3.2/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://VM-12-11-ubuntu:9000</value>
</property>
</configuration>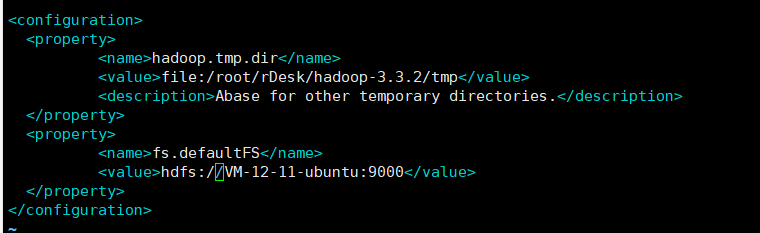
启动hadoop
sbin/start-dfs.sh
主机的hosts(C:\Windows\System32\drivers\etc)文件配置

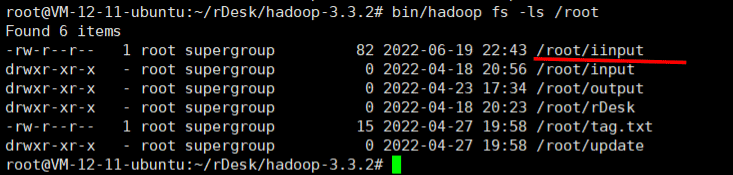
尝试连接到虚拟机的hadoop并读取文件内容,这里我读取hdfs下的/root/iinput文件内容
Java代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.DistributedFileSystem;
public class TestConnectHadoop {
public static void main(String[] args) throws Exception {
String hostname = "VM-12-11-ubuntu";
String HDFS_PATH = "hdfs://" + hostname + ":9000";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", HDFS_PATH);
conf.set("fs.hdfs.impl", DistributedFileSystem.class.getName());
conf.set("dfs.client.use.datanode.hostname", "true");
FileSystem fs = FileSystem.get(conf);
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.toString());
}
FileStatus fileStatus = fs.getFileStatus(new Path("/root/iinput"));
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getPath());
FSDataInputStream open = fs.open(fileStatus.getPath());
byte[] buf = new byte[1024];
int n = -1;
StringBuilder sb = new StringBuilder();
while ((n = open.read(buf)) > 0) {
sb.append(new String(buf, 0, n));
}
System.out.println(sb);
}
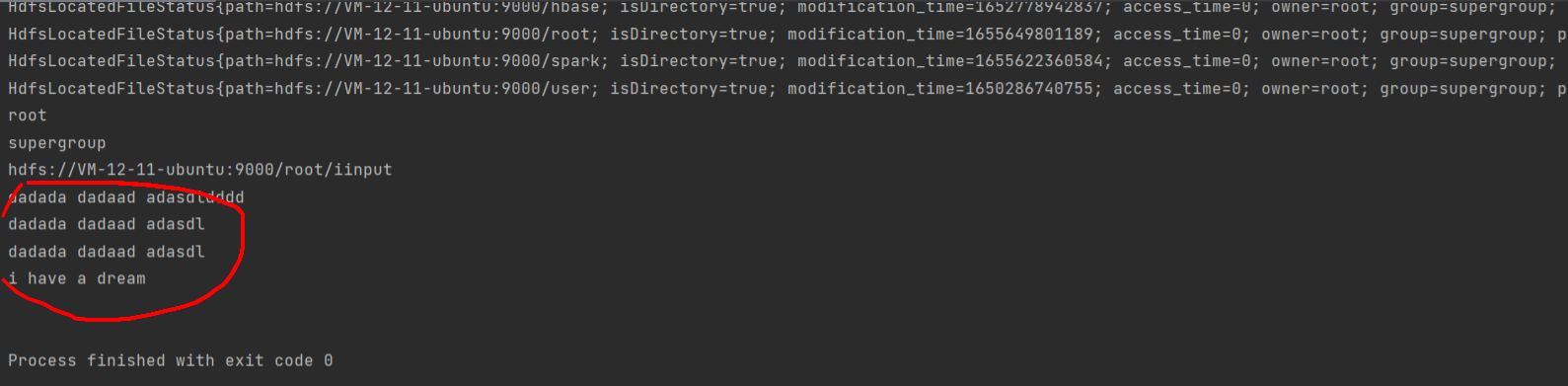
}运行结果:
编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream",要求如下: ①实现按行读取HDFS中指定文件的方法”readLine()“,如果读到文件末尾,则返回为空,否则返回文件一行的文本
思路:emmm我的思路比较简单,只适用于该要求,仅作参考。
将所有的数据读取出来存储起来,然后根据换行符进行拆分,将拆分的字符串数组存储起来,用于readline返回
Java代码
import org.apache.hadoop.fs.FSDataInputStream;
import java.io.IOException;
import java.io.InputStream;
public class MyFSDataInputStream extends FSDataInputStream {
private String data = null;
private String[] lines = null;
private int count = 0;
private FSDataInputStream in;
public MyFSDataInputStream(InputStream in) throws IOException {
super(in);
this.in = (FSDataInputStream) in;
init();
}
private void init() throws IOException {
byte[] buf = new byte[1024];
int n = -1;
StringBuilder sb = new StringBuilder();
while ((n = this.in.read(buf)) > 0) {
sb.append(new String(buf, 0, n));
}
data = sb.toString();
lines = data.split("\n");
}
/**
* 实现按行读取HDFS中指定文件的方法”readLine()“,如果读到文件末尾,则返回为空,否则返回文件一行的文本
*/
public String read_line() {
return count < lines.length ? lines[count++] : null;
}
}测试类:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.DistributedFileSystem;
public class TestConnectHadoop {
public static void main(String[] args) throws Exception {
String hostname = "VM-12-11-ubuntu";
String HDFS_PATH = "hdfs://" + hostname + ":9000";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", HDFS_PATH);
conf.set("fs.hdfs.impl", DistributedFileSystem.class.getName());
conf.set("dfs.client.use.datanode.hostname", "true");
FileSystem fs = FileSystem.get(conf);
FileStatus fileStatus = fs.getFileStatus(new Path("/root/iinput"));
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getPath());
FSDataInputStream open = fs.open(fileStatus.getPath());
MyFSDataInputStream myFSDataInputStream = new MyFSDataInputStream(open);
String line = null;
int count = 0;
while ((line = myFSDataInputStream.read_line()) != null ) {
System.out.printf("line %d is: %s\n", count++, line);
}
System.out.println("end");
}
}运行结果:

②实现缓存功能,即利用”MyFSDataInputStream“读取若干字节数据时,首先查找缓存,如果缓存中有所需要数据,则直接由缓存提供,否则从HDFS中读取数据
import org.apache.hadoop.fs.FSDataInputStream;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
public class MyFSDataInputStream extends FSDataInputStream {
private BufferedInputStream buffer;
private String[] lines = null;
private int count = 0;
private FSDataInputStream in;
public MyFSDataInputStream(InputStream in) throws IOException {
super(in);
this.in = (FSDataInputStream) in;
init();
}
private void init() throws IOException {
byte[] buf = new byte[1024];
int n = -1;
StringBuilder sb = new StringBuilder();
while ((n = this.in.read(buf)) > 0) {
sb.append(new String(buf, 0, n));
}
//缓存数据读取
buffer = new BufferedInputStream(this.in);
lines = sb.toString().split("\n");
}
/**
* 实现按行读取HDFS中指定文件的方法”readLine()“,如果读到文件末尾,则返回为空,否则返回文件一行的文本
*/
public String read_line() {
return count < lines.length ? lines[count++] : null;
}
@Override
public int read() throws IOException {
return this.buffer.read();
}
public int readWithBuf(byte[] buf, int offset, int len) throws IOException {
return this.buffer.read(buf, offset, len);
}
public int readWithBuf(byte[] buf) throws IOException {
return this.buffer.read(buf);
}
}加载全部内容