Go 分布式链路追踪
尔达 Erda 人气:0在分布式、微服务架构下,应用一个请求往往贯穿多个分布式服务,这给应用的故障排查、性能优化带来新的挑战。分布式链路追踪作为解决分布式应用可观测问题的重要技术,愈发成为分布式应用不可缺少的基础设施。本文将详细介绍分布式链路的核心概念、架构原理和相关开源标准协议,并分享我们在实现无侵入 Go 采集 Sdk 方面的一些实践。
为什么需要分布式链路追踪系统
微服务架构给运维、排障带来新挑战
在分布式架构下,当用户从浏览器客户端发起一个请求时,后端处理逻辑往往贯穿多个分布式服务,这时会浮现很多问题,比如:
- 请求整体耗时较长,具体慢在哪个服务?
- 请求过程中出错了,具体是哪个服务报错?
- 某个服务的请求量如何,接口成功率如何?
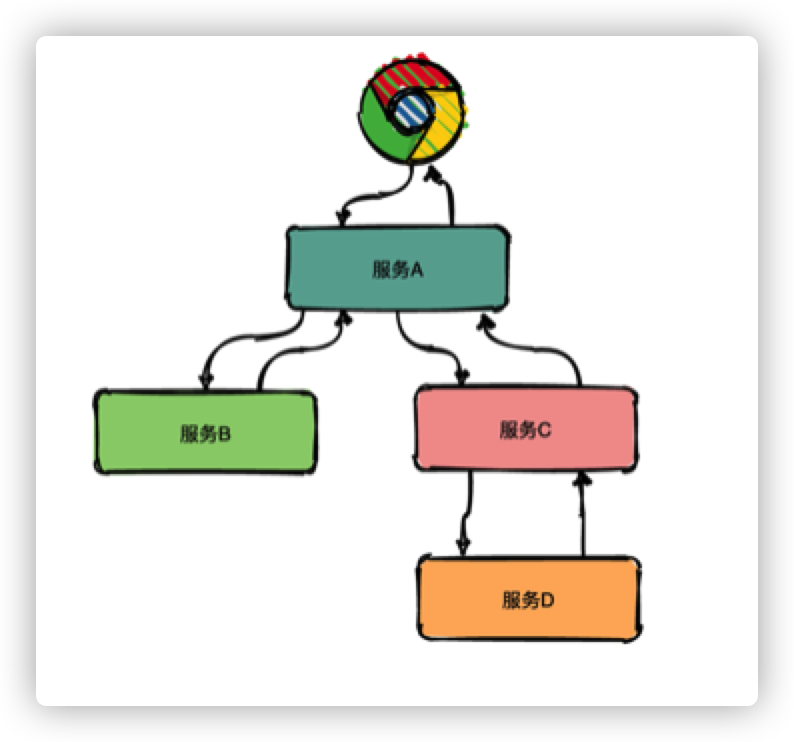
回答这些问题变得不是那么简单,我们不仅仅需要知道某一个服务的接口处理统计数据,还需要了解两个服务之间的接口调用依赖关系,只有建立起整个请求在多个服务间的时空顺序,才能更好的帮助我们理解和定位问题,而这,正是分布式链路追踪系统可以解决的。
分布式链路追踪系统如何帮助我们
分布式链路追踪技术的核心思想:在用户一次分布式请求服务的调⽤过程中,将请求在所有子系统间的调用过程和时空关系追踪记录下来,还原成调用链路集中展示,信息包括各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
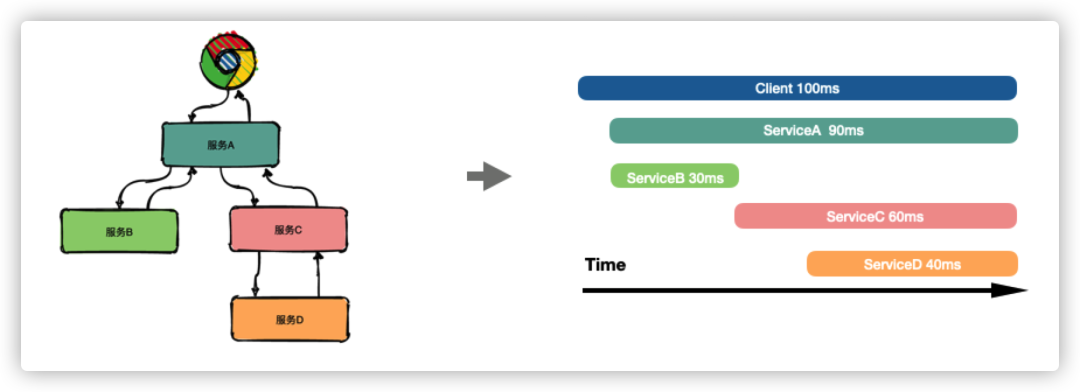
如上图所示,通过分布式链路追踪构建出完整的请求链路后,可以很直观地看到请求耗时主要耗费在哪个服务环节,帮助我们更快速聚焦问题。
同时,还可以对采集的链路数据做进一步的分析,从而可以建立整个系统各服务间的依赖关系、以及流量情况,帮助我们更好地排查系统的循环依赖、热点服务等问题。
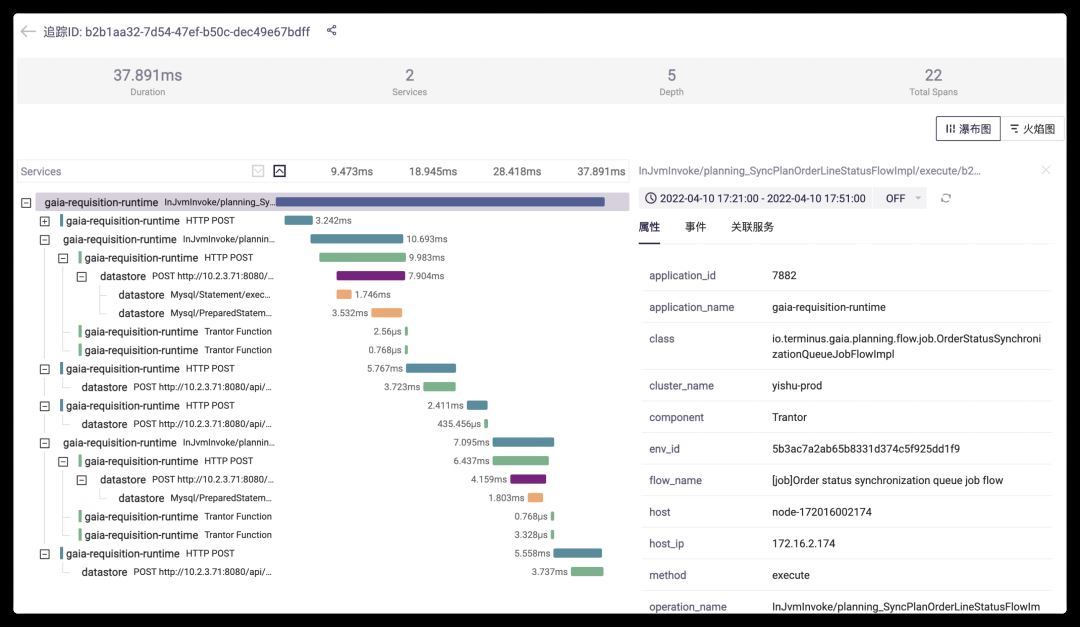
分布式链路追踪系统架构概览
核心概念
在分布式链路追踪系统中,最核心的概念,便是链路追踪的数据模型定义,主要包括 Trace 和 Span。
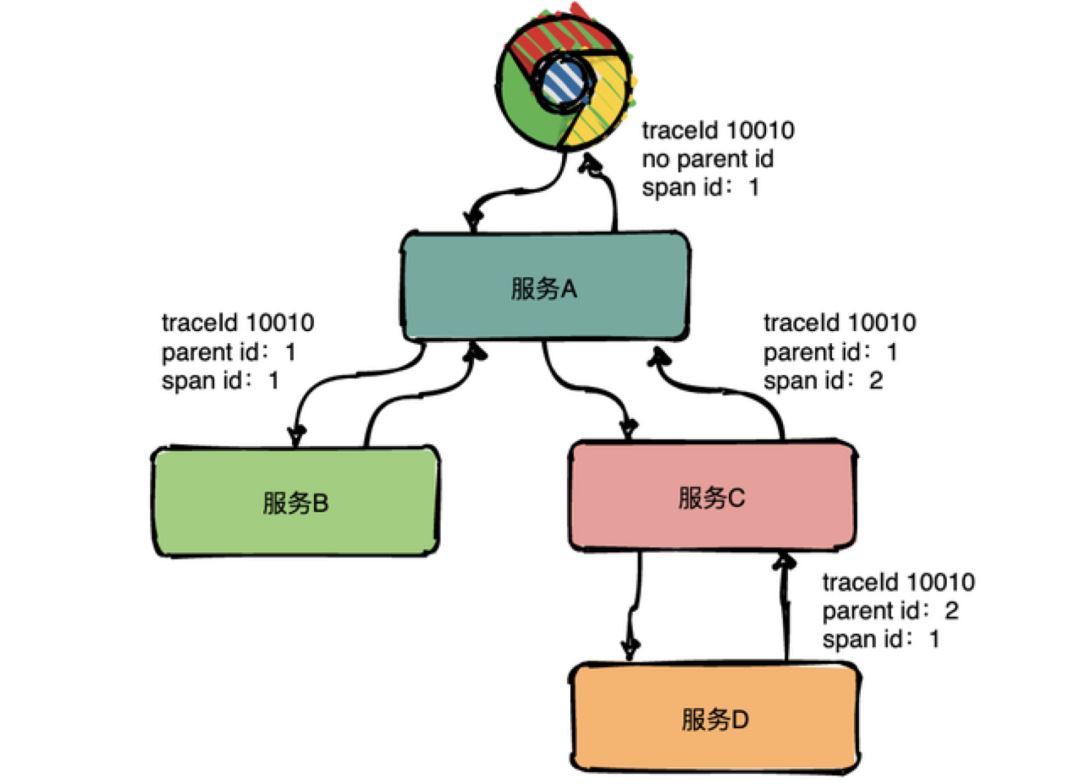
其中,Trace 是一个逻辑概念,表示一次(分布式)请求经过的所有局部操作(Span)构成的一条完整的有向无环图,其中所有的 Span 的 TraceId 相同。
Span 则是真实的数据实体模型,表示一次(分布式)请求过程的一个步骤或操作,代表系统中一个逻辑运行单元,Span 之间通过嵌套或者顺序排列建立因果关系。Span 数据在采集端生成,之后上报到服务端,做进一步的处理。其包含如下关键属性:
- Name:操作名称,如一个 RPC 方法的名称,一个函数名
- StartTime/EndTime:起始时间和结束时间,操作的生命周期
- ParentSpanId:父级 Span 的 ID
- Attributes:属性,一组 <K,V> 键值对构成的集合
- Event:操作期间发生的事件
- SpanContext:Span 上下文内容,通常用于在 Span 间传播,其核心字段包括 TraceId、SpanId
一般架构
分布式链路追踪系统的核心任务是:围绕 Span 的生成、传播、采集、处理、存储、可视化、分析,构建分布式链路追踪系统。其一般的架构如下如所示:
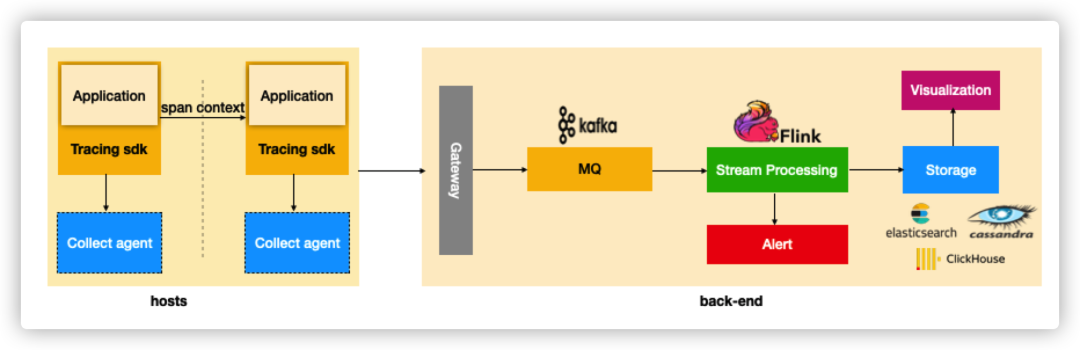
- 我们看到,在应用端需要通过侵入或者非侵入的方式,注入 Tracing Sdk,以跟踪、生成、传播和上报请求调用链路数据;
- Collect agent 一般是在靠近应用侧的一个边缘计算层,主要用于提高 Tracing Sdk 的写性能,和减少 back-end 的计算压力;
- 采集的链路跟踪数据上报到后端时,首先经过 Gateway 做一个鉴权,之后进入 kafka 这样的 MQ 进行消息的缓冲存储;
- 在数据写入存储层之前,我们可能需要对消息队列中的数据做一些清洗和分析的操作,清洗是为了规范和适配不同的数据源上报的数据,分析通常是为了支持更高级的业务功能,比如流量统计、错误分析等,这部分通常采用flink这类的流处理框架来完成;
- 存储层会是服务端设计选型的一个重点,要考虑数据量级和查询场景的特点来设计选型,通常的选择包括使用 Elasticsearch、Cassandra、或 Clickhouse 这类开源产品;
- 流处理分析后的结果,一方面作为存储持久化下来,另一方面也会进入告警系统,以主动发现问题来通知用户,如错误率超过指定阈值发出告警通知这样的需求等。
刚才讲的,是一个通用的架构,我们并没有涉及每个模块的细节,尤其是服务端,每个模块细讲起来都要很花些功夫,受篇幅所限,我们把注意力集中到靠近应用侧的 Tracing Sdk,重点看看在应用侧具体是如何实现链路数据的跟踪和采集的。
协议标准和开源实现
刚才我们提到 Tracing Sdk,其实这只是一个概念,具体到实现,选择可能会非常多,这其中的原因,主要是因为:
- 不同的编程语言的应用,可能采用不同技术原理来实现对调用链的跟踪
- 不同的链路追踪后端,可能采用不同的数据传输协议
当前,流行的链路追踪后端,比如 Zipin、Jaeger、PinPoint、Skywalking、Erda,都有供应用集成的 sdk,导致我们在切换后端时应用侧可能也需要做较大的调整。
社区也出现过不同的协议,试图解决采集侧的这种乱象,比如 OpenTracing、OpenCensus 协议,这两个协议也分别有一些大厂跟进支持,但最近几年,这两者已经走向了融合统一,产生了一个新的标准 OpenTelemetry,这两年发展迅猛,已经逐渐成为行业标准。
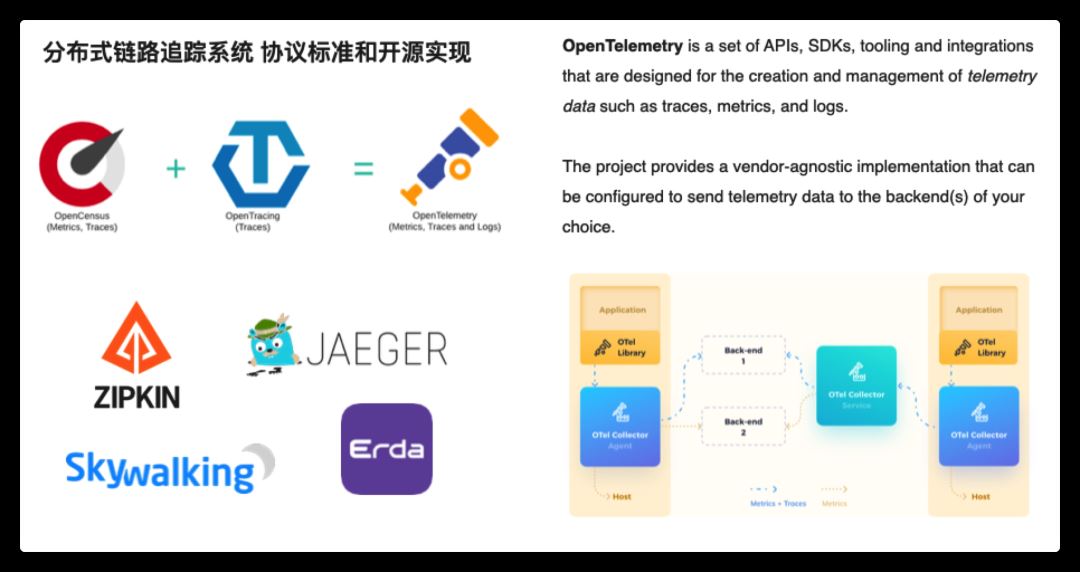
OpenTelemetry 定义了数据采集的标准 api,并提供了一组针对多语言的开箱即用的 sdk 实现工具,这样,应用只需要与 OpenTelemetry 核心 api 包强耦合,不需要与特定的实现强耦合。
应用侧调用链跟踪实现方案概览
应用侧核心任务
应用侧围绕 Span,有三个核心任务要完成:
- 生成 Span:操作开始构建 Span 并填充 StartTime,操作完成时填充 EndTime 信息,期间可追加 Attributes、Event 等
- 传播 Span:进程内通过 context.Context、进程间通过请求的 header 作为 SpanContext 的载体,传播的核心信息是 TraceId 和 ParentSpanId
- 上报 Span:生成的 Span 通过 tracing exporter 发送给 collect agent / back-end server
要实现 Span 的生成和传播,要求我们能够拦截应用的关键操作(函数)过程,并添加 Span 相关的逻辑。实现这个目的会有很多方法,不过,在罗列这些方法之前,我们先看看在 OpenTelemetry 提供的 go sdk 中是如何做的。
基于 OTEL 库实现调用拦截
OpenTelemetry 的 go sdk 实现调用链拦截的基本思路是:基于 AOP 的思想,采用装饰器模式,通过包装替换目标包(如 net/http)的核心接口或组件,实现在核心调用过程前后添加 Span 相关逻辑。当然,这样的做法是有一定的侵入性的,需要手动替换使用原接口实现的代码调用改为包装接口实现。
我们以一个 http server 的例子来说明,在 go 语言中,具体是如何做的:
假设有两个服务 serverA 和 serverB,其中 serverA 的接口收到请求后,内部会通过 httpclient 进一步发起到 serverB 的请求,那么 serverA 的核心代码可能如下图所示:
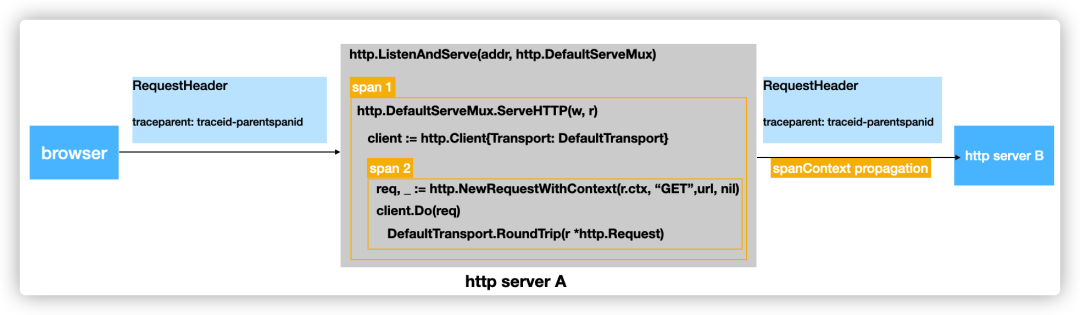
以 serverA 节点为例,在 serverA 节点应该产生至少两个 Span:
- Span1,记录 httpServer 收到一个请求后内部整体处理过程的一个耗时情况
- Span2,记录 httpServer 处理请求过程中,发起的另一个到 serverB 的 http 请求的耗时情况
- 并且 Span1 应该是 Span2 的 ParentSpan
我们可以借助 OpenTelemetry 提供的 sdk 来实现 Span 的生成、传播和上报,上报的逻辑受篇幅所限我们不再详述,重点来看看如何生成这两个 Span,并使这两个 Span 之间建立关联,即 Span 的生成和传播 。
HttpServer Handler 生成 Span 过程
对于 httpserver 来讲,我们知道其核心就是 http.Handler 这个接口。因此,可以通过实现一个针对 http.Handler 接口的拦截器,来负责 Span 的生成和传播。
package http
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
http.ListenAndServe(":8090", http.DefaultServeMux)要使用 OpenTelemetry Sdk 提供的 http.Handler 装饰器,需要如下调整 http.ListenAndServe 方法:
import (
"net/http"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/sdk/trace"
"go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp"
)
wrappedHttpHandler := otelhttp.NewHandler(http.DefaultServeMux, ...)
http.ListenAndServe(":8090", wrappedHttpHandler)

如图所示,wrppedHttpHandler 中将主要实现如下逻辑(精简考虑,此处部分为伪代码):
① ctx := tracer.Extract(r.ctx, r.Header):从请求的 header 中提取 traceparent header 并解析,提取 TraceId和 SpanId,进而构建 SpanContext 对象,并最终存储在 ctx 中;
② ctx, span := tracer.Start(ctx, genOperation(r)):生成跟踪当前请求处理过程的 Span(即前文所述的Span1),并记录开始时间,这时会从 ctx 中读取 SpanContext,将 SpanContext.TraceId 作为当前 Span 的TraceId,将 SpanContext.SpanId 作为当前 Span的ParentSpanId,然后将自己作为新的 SpanContext 写入返回的 ctx 中;
③ r.WithContext(ctx):将新生成的 SpanContext 添加到请求 r 的 context 中,以便被拦截的 handler 内部在处理过程中,可以从 r.ctx 中拿到 Span1 的 SpanId 作为其 ParentSpanId 属性,从而建立 Span 之间的父子关系;
④ span.End():当 innerHttpHandler.ServeHTTP(w,r) 执行完成后,就需要对 Span1 记录一下处理完成的时间,然后将它发送给 exporter 上报到服务端。
HttpClient 请求生成 Span 过程
我们再接着看 serverA 内部去请求 serverB 时的 httpclient 请求是如何生成 Span 的(即前文说的 Span2)。我们知道,httpclient 发送请求的关键操作是 http.RoundTriper 接口:
package http
type RoundTripper interface {
RoundTrip(*Request) (*Response, error)
}OpenTelemetry 提供了基于这个接口的一个拦截器实现,我们需要使用这个实现包装一下 httpclient 原来使用的 RoundTripper 实现,代码调整如下:
import (
"net/http"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/sdk/trace"
"go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp"
)
wrappedTransport := otelhttp.NewTransport(http.DefaultTransport)
client := http.Client{Transport: wrappedTransport}
如图所示,wrappedTransport 将主要完成以下任务(精简考虑,此处部分为伪代码):
① req, _ := http.NewRequestWithContext(r.ctx, “GET”,url, nil) :这里我们将上一步 http.Handler 的请求的 ctx,传递到 httpclient 要发出的 request 中,这样在之后我们就可以从 request.Context() 中提取出 Span1 的信息,来建立 Span 之间的关联;
② ctx, span := tracer.Start(r.Context(), url):执行 client.Do() 之后,将首先进入 WrappedTransport.RoundTrip() 方法,这里生成新的 Span(Span2),开始记录 httpclient 请求的耗时情况,与前文一样,Start 方法内部会从 r.Context() 中提取出 Span1 的 SpanContext,并将其 SpanId 作为当前 Span(Span2)的 ParentSpanId,从而建立了 Span 之间的嵌套关系,同时返回的 ctx 中保存的 SpanContext 将是新生成的 Span(Span2)的信息;
③ tracer.Inject(ctx, r.Header):这一步的目的是将当前 SpanContext 中的 TraceId 和 SpanId 等信息写入到 r.Header 中,以便能够随着 http 请求发送到 serverB,之后在 serverB 中与当前 Span 建立关联;
④ span.End():等待 httpclient 请求发送到 serverB 并收到响应以后,标记当前 Span 跟踪结束,设置 EndTime 并提交给 exporter 以上报到服务端。
基于 OTEL 库实现调用链跟踪总结
我们比较详细的介绍了使用 OpenTelemetry 库,是如何实现链路的关键信息(TraceId、SpanId)是如何在进程间和进程内传播的,我们对这种跟踪实现方式做个小的总结:
如上分析所展示的,使用这种方式的话,对代码还是有一定的侵入性,并且对代码有另一个要求,就是保持 context.Context 对象在各操作间的传递,比如,刚才我们在 serverA 中创建 httpclient 请求时,使用的是http.NewRequestWithContext(r.ctx, ...) 而非http.NewRequest(...)方法,另外开启 goroutine 的异步场景也需要注意 ctx 的传递。

非侵入调用链跟踪实现思路
我们刚才详细展示了基于常规的一种具有一定侵入性的实现,其侵入性主要表现在:我们需要显式的手动添加代码使用具有跟踪功能的组件包装原代码,这进一步会导致应用代码需要显式的引用具体版本的 OpenTelemetry instrumentation 包,这不利于可观测代码的独立维护和升级。
那我们有没有可以实现非侵入跟踪调用链的方案可选?
所谓无侵入,其实也只是集成的方式不同,集成的目标其实是差不多的,最终都是要通过某种方式,实现对关键调用函数的拦截,并加入特殊逻辑,无侵入重点在于代码无需修改或极少修改。

上图列出了现在可能的一些无侵入集成的实现思路,与 .net、java 这类有 IL 语言的编程语言不同,go 直接编译为机器码,导致无侵入的方案实现起来相对比较麻烦,具体有如下几种思路:
编译阶段注入:可以扩展编译器,修改编译过程中的ast,插入跟踪代码,需要适配不同编译器版本。启动阶段注入:修改编译后的机器码,插入跟踪代码,需要适配不同 CPU 架构。如 monkey, gohook。运行阶段注入:通过内核提供的 eBPF 能力,监听程序关键函数执行,插入跟踪代码,前景光明!如,tcpdump,bpftrace。
Go 非侵入链路追踪实现原理
Erda 项目的核心代码主要是基于 golang 编写的,我们基于前文所述的 OpenTelemetry sdk,采用基于修改机器码的的方式,实现了一种无侵入的链路追踪方式。
前文提到,使用 OpenTelemetry sdk 需要代码做一些调整,我们看看这些调整如何以非侵入的方式自动的完成:

我们以 httpclient 为例,做简要的解释。
gohook 框架提供的 hook 接口的签名如下:
// target 要hook的目标函数
// replacement 要替换为的函数
// trampoline 将源函数入口拷贝到的位置,可用于从replcement跳转回原target
func Hook(target, replacement, trampoline interface{}) error
对于 http.Client,我们可以选择 hook DefaultTransport.RoundTrip() 方法,当该方法执行时,我们通过 otelhttp.NewTransport() 包装起原 DefaultTransport 对象,但需要注意的是,我们不能将 DefaultTransport 直接作为 otelhttp.NewTransport() 的参数,因为其 RoundTrip() 方法已经被我们替换了,而其原来真正的方法被写到了 trampoline 中,所以这里我们需要一个中间层,来连接 DefaultTransport 与其原来的 RoundTrip 方法。具体代码如下:
//go:linkname RoundTrip net/http.(*Transport).RoundTrip
//go:noinline
// RoundTrip .
func RoundTrip(t *http.Transport, req *http.Request) (*http.Response, error)
//go:noinline
func originalRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) {
return RoundTrip(t, req)
}
type wrappedTransport struct {
t *http.Transport
}
//go:noinline
func (t *wrappedTransport) RoundTrip(req *http.Request) (*http.Response, error) {
return originalRoundTrip(t.t, req)
}
//go:noinline
func tracedRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) {
req = contextWithSpan(req)
return otelhttp.NewTransport(&wrappedTransport{t: t}).RoundTrip(req)
}
//go:noinline
func contextWithSpan(req *http.Request) *http.Request {
ctx := req.Context()
if span := trace.SpanFromContext(ctx); !span.SpanContext().IsValid() {
pctx := injectcontext.GetContext()
if pctx != nil {
if span := trace.SpanFromContext(pctx); span.SpanContext().IsValid() {
ctx = trace.ContextWithSpan(ctx, span)
req = req.WithContext(ctx)
}
}
}
return req
}
func init() {
gohook.Hook(RoundTrip, tracedRoundTrip, originalRoundTrip)
}
我们使用 init() 函数实现了自动添加 hook,因此用户程序里只需要在 main 文件中 import 该包,即可实现无侵入的集成。
值得一提的是 req = contextWithSpan(req) 函数,内部会依次尝试从 req.Context() 和 我们保存的 goroutineContext map 中检查是否包含 SpanContext,并将其赋值给 req,这样便可以解除了必须使用 http.NewRequestWithContext(...) 写法的要求。
详细的代码可以查看 Erda 仓库:https://github.com/erda-project/erda-infra/tree/master/pkg/trace
参考链接
https://opentelemetry.io/registry/
https://opentelemetry.io/docs/instrumentation/go/getting-started/
https://www.ipeapea.cn/post/go-asm/
https://github.com/brahma-adshonor/gohook
加载全部内容