Python 正则 re.compile
笑笑布丁 人气:0背景:我在爬虫处理某个文本时,用到了re.findall(),而不是re.compile。远在新加坡的同事提出了质疑,认为以我的水平,不应该写出这样影响性能的代码,让我优化一下。我提出了反驳:既然使用了Python,就不应该太过考虑性能的问题,如果要考虑性能就使用C语言,而不是Python.他接着说:正是因为python性能不够,所以更应该考虑代码的优化,能做好就应该做到最好.最后,我没有回话,当然我也没有进行所谓的优化,以下我会给出我自己的观点.
re.compile()、re.findall()、re.search() 的作用与区别
1、re.compile()
Python里的re是支持正则表达式的模块,所谓的正则表达式就是匹配文本里符合条件的语句. re.compile()是根据包含正则表达式的字符串创建模式对象,以提高匹配效率.例如:
def test():
regex = r'(\d+) years old'
content = 'Alex is a 7 years old boy.'
reg = re.compile(regex)
result = re.search(reg, content).group()
print(result)
result = 7
2、re.search()
re.search()是在字符串开启查找模式,如其名:search.例如:
def test():
content = 'Alex is a 7 years old boy.'
result = re.search(r'(\d+) years old', content).group()
print(result)
result = 7
3、re.findall()
re.findall()是返回一个列表,列表里包含了所有符合条件的结果,例如:
def test():
content = 'Alex is a 7 years old boy.Bob is a 12 years old boy...'
result = re.findall(r'(\d+) years old', content)
print(result)
result = ['7', '12']
我们分歧在他认为我应该先用 re.complile 编译好正则之后,再匹配,正如我在re.compile举得例子. 你会说他说的没错啊,作者不应该顺从同事这个合理的要求,不改就算了还要在这里发文BB.我想说的是 抛开剂量谈毒性,都是耍流氓。对于数据来说抛开量级谈性能差异,都是耍流氓. 如果要处理的 文本是百万、千万、亿这个级别,我会做优化,但是对于个别刚上万的数据来说,我觉得没必要,业务流程真的不缺那0.0X秒,多写一行re.compile的时间远大于提示的时间了. 做好代码的优化很重要,特别是面对大量数据的时候,但是我们要想清楚,有时候并不是靠那几行re.compile就能提高多大的性能,精简流程,合理的设计模式才是重点. 工作中还是要做好和同事的沟通,不要和我一样,不然迟早会被别人唾弃.
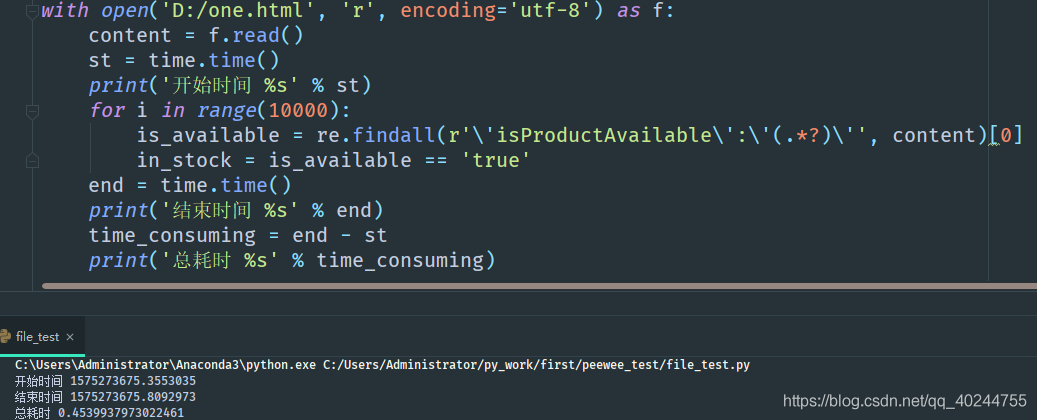
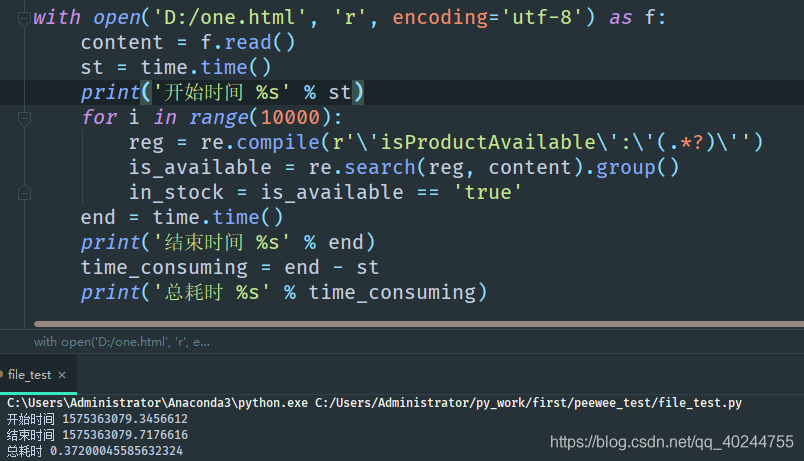
根据下面评论的提示re.compile()那一行应该放在迭代外面的代码块里,相比图中的时间速度会有所提升.
加载全部内容