Pandas数据读取
尤而小屋 人气:0前言
大家好,我是Peter~
本文记录的是Pandas两种少用的读取文件方式:
- 读取在线文件的数据
- 读取剪贴板的数据
声明:本文案例和在线数据仅用于学术分享
read_html
该函数表示的是直接读取在线的html文件,一般是表格的形式;将HTML的表格转换为DataFrame的一种快速方便的方法。
这个方法对于快速合并来自不同网页上的表格非常有用,就省去了爬取数据再来读取的时间。
具体函数的参数为:
pandas.read_html(io, # 文件 io 对象;路径或者io.Strings对象 match='.+', # str 或编译的正则表达式,可选 flavor=None, # 要使用的解析引擎, None是默认值 header=None, # 文件表头 index_col=None, # 索引 skiprows=None, # 跳过行 attrs=None, # 属性 parse_dates=False, # 日期解析 thousands=',', # 千分位 encoding=None, # 编码 decimal='.', # 识别为小数点的字符 converters=None, # 属性转换 na_values=None, # 空值信息 keep_default_na=True, # 是否保持空值 displayed_only=True # 是否应该解析带有“display:none” 的元素 )
在线文件1
读取维基百科上一份历届奥运会乒乓球冠军的相关数据。该地址下的部分表格形式的数据:


In [3]:
url = "https://zh.m.wikipedia.org/zh/%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B9%92%E4%B9%93%E7%90%83%E5%A5%96%E7%89%8C%E5%BE%97%E4%B8%BB%E5%88%97%E8%A1%A8" df = pd.read_html(url) df
Out[3]:
我们观察到此时读取到的df是一个列表,总长度是15
list
In [4]:
len(df)
Out[4]:
9
查看列表中的部分元素:此时就是一个个的DataFrame形式的数据

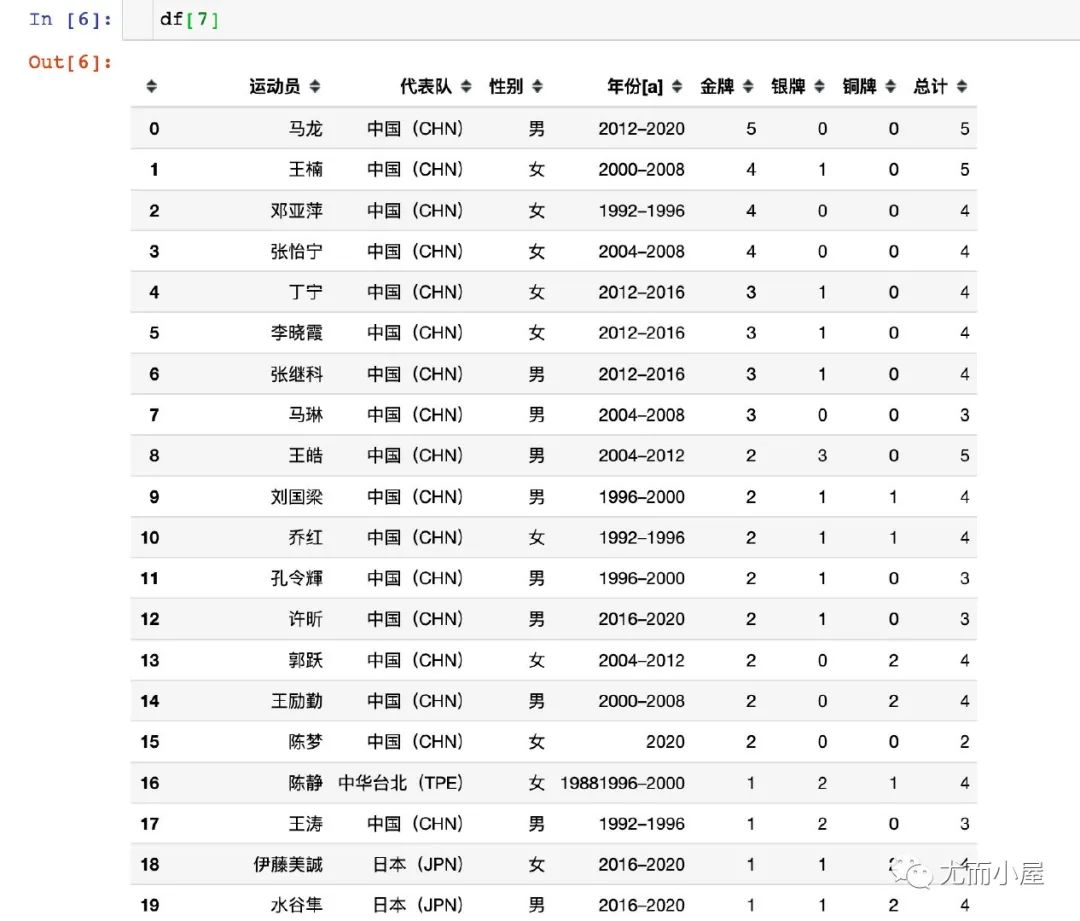
在线文件2
一个国外网站下的数据
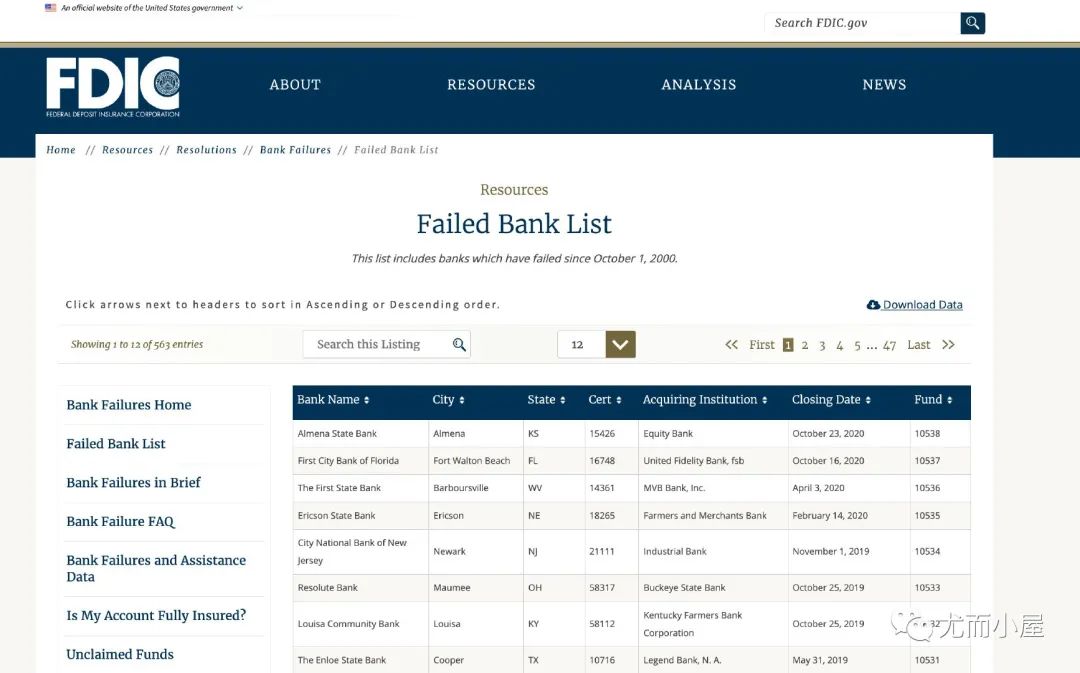
In [7]:
df1 = pd.read_html("https://www.fdic.gov/resources/resolutions/bank-failures/failed-bank-list")
type(df1)
Out[7]:
list
In [8]:
len(df1)
Out[8]:
1
In [9]:
df1[0]
Out[9]:

读取在线CSV文件
以读取GitHub上一个CSV文件为例:
方式1:直接读取
url="https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv" pd.read_csv(url)

方式2:通过io.Strings对象
url="https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv"
response=requests.get(url).content # 先发请求
df2 = pd.read_csv(io.StringIO(response.decode('utf-8')))
df2 # 效果同上
Pandas读取剪贴板
pandas.read_clipboard(sep='\\s+', **kwargs)

一个简单的例子说明函数使用:假设本地目录下有这样Excel表格的数据
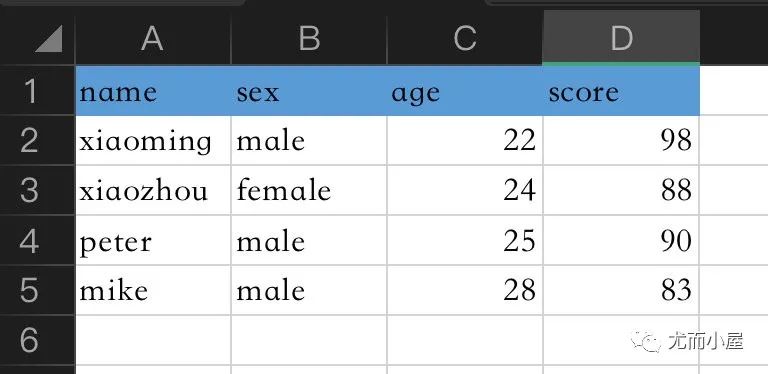
1、先剪贴数据:【Ctrl + C】

2、运行代码下面的代码,按下MacOS中的【向上的箭头】 + 【回车键】,完成读取
Windows下面应该是【Shift + Enter】
如果数据比较少,省去了通过Excel或者CSV文件的读取方式的时间:
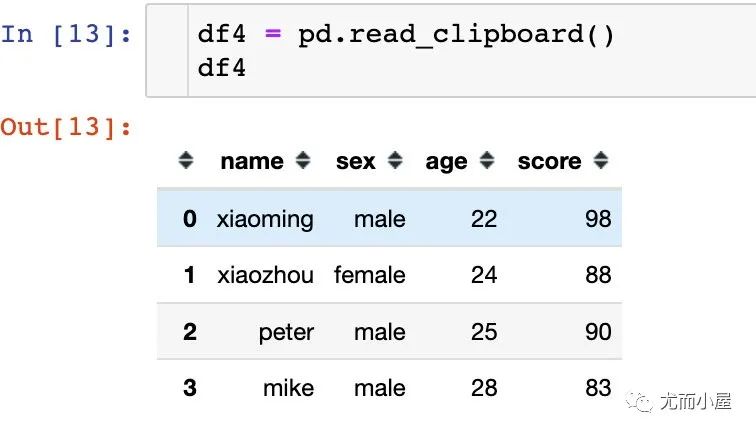
加载全部内容