python自变量选择
嘟嘟肚腩仔 人气:01、为什么需要自变量选择?
一个好的回归模型,不是自变量个数越多越好。在建立回归模型的时候,选择自变量的基本指导思想是少而精。丢弃了一些对因变量y有影响的自变量后,所付出的代价就是估计量产生了有偏性,但是预测偏差的方差会下降。因此,自变量的选择有重要的实际意义。
2、自变量选择的几个准则
(1)自由度调整复决定系数达到最大
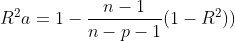

(2)赤池信息量AIC达到最小
3、所有子集回归
(1)算法思想
所谓所有子集回归,就是将总的自变量的所有子集进行考虑,查看哪一个子集是最优解。
(2)数据集情况
(3)代码部分
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
from itertools import combinations
def allziji(df):
list1 = [1,2,3]
n = 18
R2 = []
names = []
#找到所有子集,并依次循环
for a in range(len(list1)+1):
for b in combinations(list1,a+1):
p = len(list(b))
data1 = pd.concat([df.iloc[:,i-1] for i in list(b) ],axis = 1)#结合所需因子
name = "y~"+("+".join(data1.columns))#组成公式
data = pd.concat([df['y'],data1],axis=1)#结合自变量和因变量
result = smf.ols(name,data=data).fit()#建模
#计算R2a
r2 = (n-1)/(n-p-1)
r2 = r2 * (1-result.rsquared**2)
r2 = 1 - r2
R2.append(r2)
names.append(name)
finall = {"公式":names, "R2a":R2}
data = pd.DataFrame(finall)
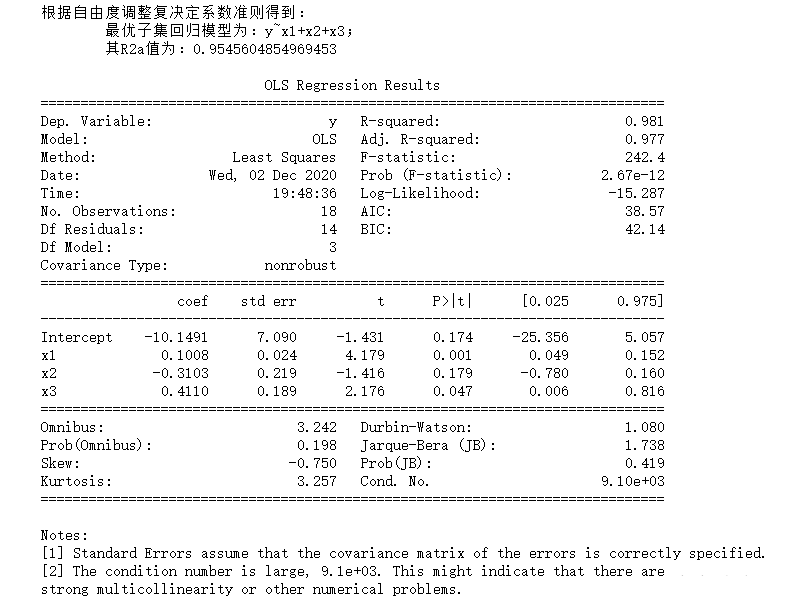
print("""根据自由度调整复决定系数准则得到:
最优子集回归模型为:{};
其R2a值为:{}""".format(data.iloc[data['R2a'].argmax(),0],data.iloc[data['R2a'].argmax(),1]))
result = smf.ols(name,data=df).fit()#建模
print()
print(result.summary())df = pd.read_csv("data5.csv")
allziji(df)(4)输出结果
4、后退法
(1)算法思想
后退法与前进法相反,通常先用全部m个变量建立一个回归方程,然后计算在剔除任意一个变量后回归方程所对应的AIC统计量的值,选出最小的AIC值所对应的需要剔除的变量,不妨记作x1;然后,建立剔除变量x1后因变量y对剩余m-1个变量的回归方程,计算在该回归方程中再任意剔除一个变量后所得回归方程的AIC值,选出最小的AIC值并确定应该剔除的变量;依此类推,直至回归方程中剩余的p个变量中再任意剔除一个 AIC值都会增加,此时已经没有可以继续剔除的自变量,因此包含这p个变量的回归方程就是最终确定的方程。
(2)数据集情况
(3)代码部分
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
def backward(df):
all_bianliang = [i for i in range(0,9)]#备退因子
ceshi = [i for i in range(0,9)]#存放加入单个因子后的模型
zhengshi = [i for i in range(0,9)]#收集确定因子
data1 = pd.concat([df.iloc[:,i+1] for i in ceshi ],axis = 1)#结合所需因子
name = 'y~'+'+'.join(data1.columns)
result = smf.ols(name,data=df).fit()#建模
c0 = result.aic #最小aic
delete = []#已删元素
while(all_bianliang):
aic = []#存放aic
for i in all_bianliang:
ceshi = [i for i in zhengshi]
ceshi.remove(i)
data1 = pd.concat([df.iloc[:,i+1] for i in ceshi ],axis = 1)#结合所需因子
name = "y~"+("+".join(data1.columns))#组成公式
data = pd.concat([df['y'],data1],axis=1)#结合自变量和因变量
result = smf.ols(name,data=data).fit()#建模
aic.append(result.aic)#将所有aic存入
if min(aic)>c0:#aic已经达到最小
data1 = pd.concat([df.iloc[:,i+1] for i in zhengshi ],axis = 1)#结合所需因子
name = "y~"+("+".join(data1.columns))#组成公式
break
else:
zhengshi.remove(all_bianliang[aic.index(min(aic))])#查找最小的aic并将最小的因子存入正式的模型列表当中
c0 = min(aic)
delete.append(aic.index(min(aic)))
all_bianliang.remove(all_bianliang[delete[-1]])#删除已删因子
name = "y~"+("+".join(data1.columns))#组成公式
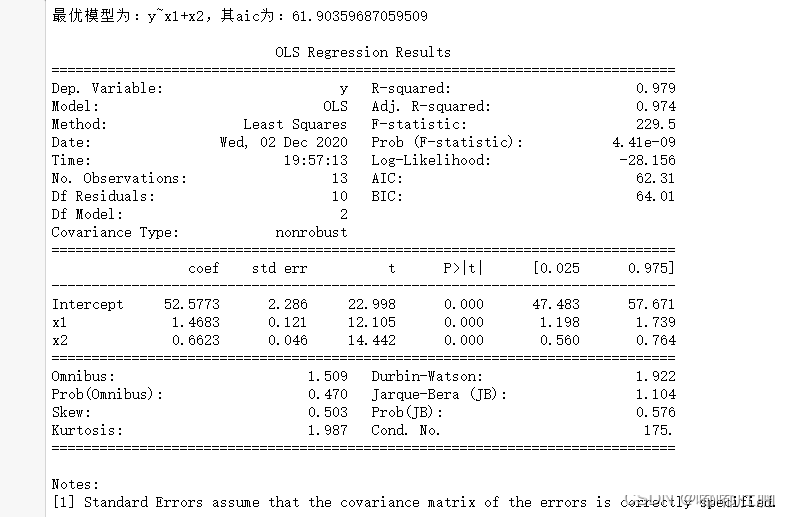
print("最优模型为:{},其aic为:{}".format(name,c0))
result = smf.ols(name,data=df).fit()#建模
print()
print(result.summary())df = pd.read_csv("data3.1.csv",encoding='gbk')
backward(df)(4)结果展示

5、逐步回归
(1)算法思想
逐步回归的基本思想是有进有出。R语言中step()函数的具体做法是在给定了包含p个变量的初始模型后,计算初始模型的AIC值,并在此模型基础上分别剔除p个变量和添加剩余m-p个变量中的任一变量后的AIC值,然后选择最小的AIC值决定是否添加新变量或剔除已存在初始模型中的变量。如此反复进行,直至既不添加新变量也不剔除模型中已有的变量时所对应的AIC值最小,即可停止计算,并返回最终结果。
(2)数据集情况

(3)代码部分
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
def zhubuhuigui(df):
forward = [i for i in range(0,4)]#备选因子
backward = []#备退因子
ceshi = []#存放加入单个因子后的模型
zhengshi = []#收集确定因子
delete = []#被删因子
while forward:
forward_aic = []#前进aic
backward_aic = []#后退aic
for i in forward:
ceshi = [j for j in zhengshi]
ceshi.append(i)
data1 = pd.concat([df.iloc[:,i] for i in ceshi ],axis = 1)#结合所需因子
name = "y~"+("+".join(data1.columns))#组成公式
data = pd.concat([df['y'],data1],axis=1)#结合自变量和因变量
result = smf.ols(name,data=data).fit()#建模
forward_aic.append(result.aic)#将所有aic存入
for i in backward:
if (len(backward)==1):
pass
else:
ceshi = [j for j in zhengshi]
ceshi.remove(i)
data1 = pd.concat([df.iloc[:,i] for i in ceshi ],axis = 1)#结合所需因子
name = "y~"+("+".join(data1.columns))#组成公式
data = pd.concat([df['y'],data1],axis=1)#结合自变量和因变量
result = smf.ols(name,data=data).fit()#建模
backward_aic.append(result.aic)#将所有aic存入
if backward_aic:
if forward_aic:
c0 = min(min(backward_aic),min(forward_aic))
else:
c0 = min(backward_aic)
else:
c0 = min(forward_aic)
if c0 in backward_aic:
zhengshi.remove(backward[backward_aic.index(c0)])
delete.append(backward_aic.index(c0))
backward.remove(backward[delete[-1]])#删除已删因子
forward.append(backward[delete[-1]])
else:
zhengshi.append(forward[forward_aic.index(c0)])#查找最小的aic并将最小的因子存入正式的模型列表当中
forward.remove(zhengshi[-1])#删除已有因子
backward.append(zhengshi[-1])
name = "y~"+("+".join(data1.columns))#组成公式
print("最优模型为:{},其aic为:{}".format(name,c0))
result = smf.ols(name,data=data).fit()#建模
print()
print(result.summary())df = pd.read_csv("data5.5.csv",encoding='gbk')
zhubuhuigui(df)(4)结果展示
加载全部内容