C++堆和堆排序
配的上了吗 人气:0有关二叉树的性质:
1. 若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有 个结点.
2. 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是 .
3. 对任何一棵二叉树, 如果度为0其叶结点个数为 , 度为2的分支结点个数为 ,则有 = +1
4. 若规定根节点的层数为1,具有n个结点的满二叉树的深度,h= . (ps: 是log以2 为底,n+1为对数)
5. 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对 于序号为i的结点有:
1. 若i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点
2. 若2i+1<n,左孩子序号:2i+1 若2i+1>=n则无左孩子
3. 若2i+2<n,右孩子序号:2i+2 若2i+2>=n则无右孩子
有关堆
存储结构:
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结 构存储。现实中我们通常把堆(一种完全二叉树)使用顺序结构的数组来存储
堆的概念和结构:

堆的性质:
堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。
上面这些都是复制粘贴的, 想看了随便看看。下面给出自己的一些总结:
C++实现堆
Heap.h
#pragma once
#include<iostream>
#include<assert.h>
#include<algorithm>
#include<Windows.h>
using namespace std;
typedef int DataType;
class Heap
{
public:
Heap() :a(new DataType[1]), size(0), capacity(1) {}
~Heap()
{
delete[]a;
a = nullptr;
size = capacity = 0;
}
public:
void Push(const DataType& x);
void Pop(); // 删除堆顶的数据
DataType Top()const;
bool Empty()const;
int Size()const;
void Swap(DataType& a, DataType& b);
void print();
public:
void AdjustUp(int child);
void AdjustDown(int size, int parent);
private:
DataType* a;
int size;
int capacity;
};Heap.cpp
#include"Heap.h"
void Heap::Swap(DataType& a, DataType& b)
{
DataType tmp = a;
a = b;
b = tmp;
}
void Heap::Push(const DataType& x)
{
if (size == capacity)
{
int newcapacity = capacity == 0 ? 1 : capacity * 2;
DataType* tmp = new DataType[newcapacity];
assert(tmp);
std::copy(a, a + size, tmp);
delete a;
a = tmp;
capacity = newcapacity;
}
a[size] = x;
AdjustUp(size);
++size;
}
void Heap::Pop() // 删除堆顶的数据
{
assert(size > 0);
Swap(a[0], a[size - 1]);
size--;
AdjustDown(size, 0);
}
DataType Heap::Top()const
{
assert(size > 0);
return a[0];
}
bool Heap::Empty()const
{
return size == 0;
}
int Heap::Size()const
{
return size;
}
void Heap::AdjustUp(int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[parent] > a[child])
{
Swap(a[parent], a[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
//int parent = (child - 1) / 2;
//if(child > 0)
//{
// if (a[parent] > a[child])
// {
// Swap(a[parent], a[child]);
// child = parent;
// AdjustUp(child);
// }
// else
// {
// return;
// }
//}
}
void Heap::AdjustDown(int size,int parent) // size 是总大小,parent是从哪里开始向下调整
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] < a[child])
child++;
if (a[child] < a[parent])
{
Swap(a[child], a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void Heap::print()
{
for (int i = 0; i < size; ++i)
{
cout << a[i] << ' ';
}
cout << endl;
}其实Heap这个类 物理结构就是一个一维数组,只是逻辑结构是一个堆,我们将其想象成一个具有特定规律的完全二叉树:特定规律就是任意一个二叉树的根节点都>=或<=其子节点。
这个Heap类的关键是push和pop函数,与之相关的是向上调整和向下调整函数,这也是堆的精髓所在。
push是在数组尾部也就是堆的最下面插入一个元素,此时应该调用向上调整算法,因为此结点的插入可能破坏了原来的堆的结构,因此,向上调整即可,但是有个前提,即插入此结点之前这个完全二叉树本身符合堆的特性。并且调整只会影响此插入结点的祖宗,不会对其他节点产生影响。
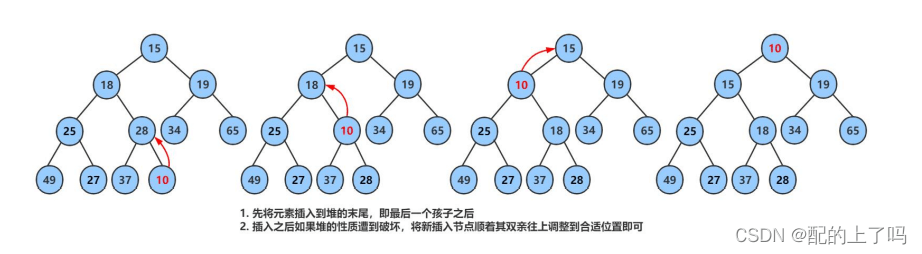
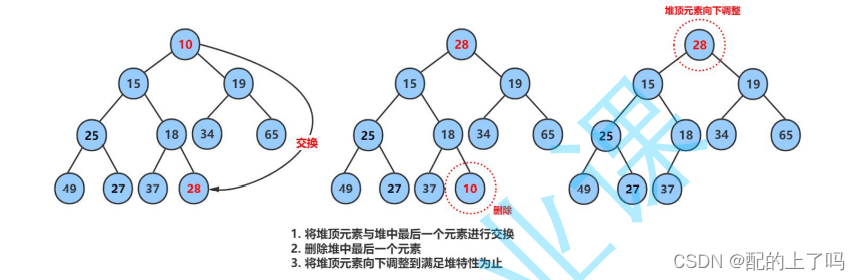
pop是删除堆顶的元素,且只能删除堆顶的元素,因为堆这个数据结构的一个主要功能就是选数:即选出当前堆中最大或者最小的数,并且选数的效率很高。pop删除堆顶元素之后,再进行一下调整即可选出次大或者次小的元素。
那么,怎么删除呢?即将堆顶和末尾的数字交换,然后删除交换后的末尾数字,此时堆顶元素很可能破坏了堆的结构,因此采用向下调整的算法。向下调整算法有一个前提:左右子树必须是一个堆,才能调整。
堆的应用
向上调整算法和向下调整算法不仅仅用于Heap的插入和删除操作,在堆排序等堆的应用中也要使用。
堆排序
传入一个数组,对数组进行排序,且是一个O(N*LogN)的算法,效率很高。
void AdjustUp(int* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[parent] > a[child])
{
swap(a[parent], a[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void AdjustDown(int* a,int size, int parent) // size 是总大小,parent是从哪里开始向下调整
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] < a[child])
child++;
if (a[child] < a[parent])
{
swap(a[child], a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}HeapSort
void HeapSort(int* a, int n)
{
// 将传入的数组看作一个完全二叉树,然后调整为堆。
// 升序调整为大根堆,降序小根堆。
// 建堆方式1: O(N*LogN)
// 利用向上调整算法,其实就是堆的插入函数
//for (int i = 1; i < n; ++i)
//{
// AdjustUp(a, i);
//}
// 建堆方式2: O(N)
// 利用向下调整算法
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
// 建好堆之后排序 目前是一个小堆,小堆用来排降序
// 5 13 17 19 22 27 32 35 38 42 45
// O(N * LogN);
int end = n - 1;
while (end > 0)
{
swap(a[0], a[end]);
AdjustDown(a, end, 0);
end--;
}
}前面说过,堆的一个主要或者说唯一作用就是选数,大根堆选出最大数,小根堆选出最小数,先将给定数组调整为堆,若排升序则调整为大根堆,此时a[0]即最大值,将其与数组末尾数组交换,然后进行向下调整即可选出次大值,再进行交换即可。整个逻辑十分像Heap类的删除操作,只是将删除了的堆顶元素放置在数组末尾而已,然后不断进行这个操作,直到整个数组有序。
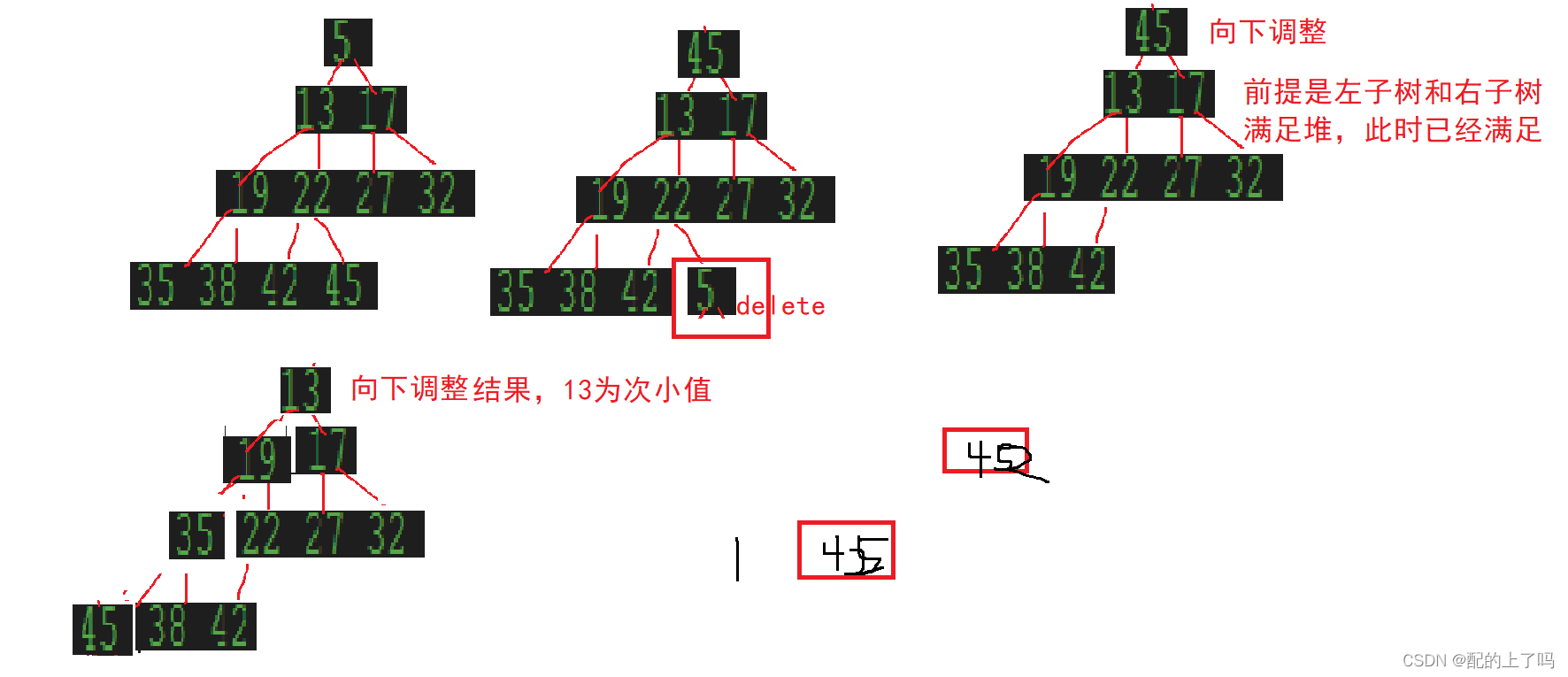
将数组调整为堆的思路有两个,一种是模拟插入的操作,从头遍历逐个将元素进行向上调整操作,主要是因为向上调整算法必须基于此完全二叉树本身就是一个堆,才可以进行向上调整操作。所以从尾开始向上调整肯定是不行的。
思路二与思路一有相同之处,即利用向下调整算法,向下调整基于此结点的左子树和右子树都是堆,所以直接从头开始向下调整不可以,所以从尾向前遍历进行向下调整,且末尾的叶子结点没有必要调整,所以从第一个结点数>=2的二叉树开始进行向下调整。
HeapSort的逻辑不会受升序和降序的影响,只需要将AdjustUp和AdjustDown的调整逻辑改变即可。
为什么排升序要建大根堆,不建小根堆呢?
首先,如果建小根堆,确实建好之后的数组比较像升序,且此时最小值也已经在数组的a[0]处,但是,选次大的元素时,对于后面a[1] 至 a[n-1]个元素,此时之前堆的兄弟父子关系全都乱了,向上调整和向下调整都不可以,只能重建堆,而重建堆的时间复杂度为O(N)。如此下去,每次挑出最大值都需要O(N),最终的就是O(N)+O(N-1)+...+O(2)... 总的就是O(N^2)了。
而如果建大根堆,a[0]就是最大值,将其与数组末尾进行交换,这个交换操作只是O(1)的操作,最重要的是交换之后,把末尾元素忽视之后的这个完全二叉树,只有堆顶元素不符合堆,只需向下调整一次即可,为O(logN),即可选出次大值,相比于前面的O(N)就快了很多。
加载全部内容