Python 字符串处理
黎曼假设 人气:01.如何统计序列中元素出现的频率并排序?
统计序列中元素出现的频率的结果肯定是一个字典,Key 为序列中的元素而 Value 为元素出现的次数,因此可以先创建一个字典,作为初始的统计结果,并假设初始出现的次数都为0。
对频率结果字典的 Value 进行排序
from random import randint
# 生成包含重复元素的随机序列
nums = [randint(0, 10) for num in range(20)]
# 元素出现次数的统计最终肯定是一个字典,因此可以以元素的Key,出现的次数为Value
count = dict.fromkeys(nums, 0)
# 统计频次
for num in nums:
count[num] += 1
# 排序方案一
# 根据Value进行排序
_count = sorted(count.values())
# 获取最大的次数
max = _count.pop()
keys = []
# 根据Value获取Key
for k, v in count.items():
if v == max:
keys.append(k)
if __name__ == '__main__':
print(nums)
print(count)
print(_count)
print(max)
print(keys)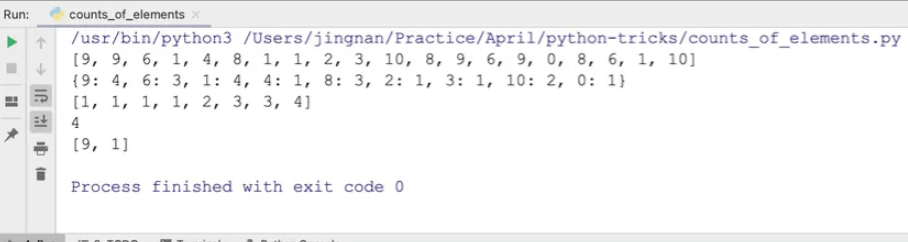
出现的最大频次为4,且频次为4的元素是9和1
使用 Counter 对象进行排序
# 排序方案二
from collections import Counter
_count = Counter(count)
# 中间代码不变
if __name__ == '__main__':
print(nums)
print(count)
print(_count)
print(_count.most_common())
# 获取出现频次最高的三个元素
print(_count.most_common(3))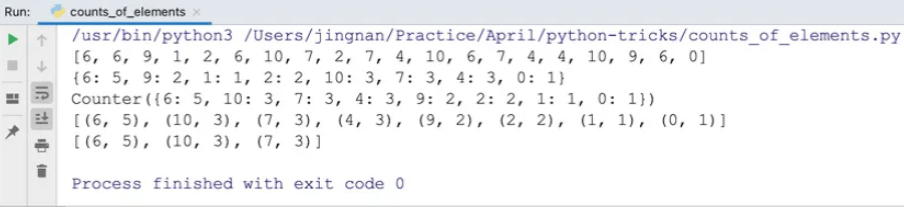
2.统计单词次数
import re
from collections import Counter
zen = open('zen.txt').read()
# 分割所有单词
zen = re.split('\W+', zen)
# print(zen)
_zen = Counter(zen)
print(_zen)
_zen_3 = _zen.most_common(3)
print('前三个出现频次最高的词:', _zen_3)
加载全部内容