python程 高效并发
bastgia 人气:0前言:
如今,大多数计算机都带有多个内核,允许多个线程并行运行计算。即使处理器只有单核,也可以通过并发编程来提升程序的运行效率,比如在一个线程等待网络数据的同时,允许另一个线程占用CPU完成计算操作。并发编程对于程序运行加速是非常重要的。
不幸的是,由于所谓的全局解释器锁(“GIL”),在许多情况下,Python 一次只能运行一个线程。只有在一些特定的场景下,它才可以很好地运行多个线程。
但是哪些使用模式允许并行,哪些不允许?因此,本文将以实用性的角度解析 GIL 的工作原理,逐步深化对于GIL的认知:
- 本文将由浅入深的讲解GIL的工作原理,并把GIL的特性由浅入深的抽象成认知模型从而方便理解
- 本文将给出一些实用的设计方法,帮助读者预测并行瓶颈是否出现以及出现的位置
太长不看版:
线程必须持有 GIL 才能调用 CPython C API。**
在解释器中运行的 Python 代码,例如 x = f(1, 2),会使用这些 API。 每个 == 比较、每个整数加法、每个 list.append:都需要调用 CPython C API。 因此,线程运行 Python 代码时必须持有锁。
其他线程无法获取 GIL,因此无法运行,直到当前运行的线程释放它,这会自动每 5ms 发生一次。
长时间运行(“阻塞”)的扩展代码会阻止自动切换。
然而,用 C(或其他低级语言)编写的 Python 扩展可以显式释放 GIL,从而允许一个或多个线程与持有 GIL 的线程并行运行。
python线程何时需要拥有GIL?
GIL 是 CPython 解释器的实现的一部分,它是一个线程锁:在一个给定的时间只有一个线程可以获取锁。因此,要了解 GIL 如何影响 Python 的多线程并行能力,我们首先需要回答一个关键问题:Python 线程何时需要持有 GIL?
认知模型1:同一时刻只有一个线程运行python代码
考虑以下代码; 它在两个线程中运行函数 go():
import threading
import time
def go():
start = time.time()
while time.time() < start + 0.5:
sum(range(10000))
def main():
threading.Thread(target=go).start()
time.sleep(0.1)
go()
main()当我们使用 Sciagraph 性能分析器运行它时,执行时间线如下所示:

注意:线程是如何在 CPU 上等待和运行之间来回切换的:运行代码持有 GIL,等待线程正在等待 GIL。
如果 GIL 5 毫秒(或其他可配置的时间间隔)没有释放,Python 会告诉当前正在运行的线程释放 GIL。下一个线程拿到GIL后就可以运行。如上图所示,我们看到两个线程之间来回切换;实际显示的间隔长于 5 毫秒,因为采样分析器每 47 毫秒左右采样一次。
这就是我们最初的认知模型,或者说是对于GIL最浅层的认知:
- 线程必须持有 GIL 才能运行 Python 代码。
- 其他线程无法获取 GIL,因此无法运行,直到当前运行的线程释放它,GIL的切换每 5ms 进行一次。
模型2:不保证每 5 毫秒释放一次 GIL
GIL 在 Python 3.7 到 3.10 中默认每 5ms 释放一次,从而允许其他线程运行:
>>> import sys >>> sys.getswitchinterval() 0.005
但是,这些版本中的GIL是尽力而为的,也就是说,其不能保证每隔5ms一定使得线程释放。考虑一个简单的伪代码,解释器在运行python线程时的逻辑如这个伪代码中的死循环所示:只有运行完一个操作后解释器python才会去检查是否释放GIL锁。
当然,python内部的实现逻辑比这个伪代码复杂的多,但是遵循的原则是相同的:
while True:
if time_to_release_gil():
temporarily_release_gil()
run_next_python_instruction()只要 run_next_python_instruction() 没有完成,temporary_release_gil() 就不会被调用。 大多数情况下,这不会发生,因为单个操作(添加两个整数、追加到列表等)很快就可以完成。因此,解释器可以经常检查是否该释放GIL。
但是,长时间运行的操作会阻止 GIL 自动释放。 让我们编写一个小的Cython拓展,Cython是一种类似 Python的语言,其代码会转化成C/C++代码,并编译成可以被python调用的形式。下边的代码调用标准 C 库中的 sleep() 函数:
cdef extern from "unistd.h":
unsigned int sleep(unsigned int seconds)
def c_sleep(unsigned int seconds):
sleep(seconds)我们可以使用 Cython 附带的 cythonize 工具将其编译为可导入的 Python 扩展:
$ cythonize -i c_sleep.pyx ... $ ls c_sleep*.so c_sleep.cpython-39-x86_64-linux-gnu.so
接下来从一个 Python 程序中调用它,该程序会创建一个新线程,并调用c_sleep(),该新线程与主线程是并行的:
import threading
import time
from c_sleep import c_sleep
def thread():
c_sleep(2)
threading.Thread(target=thread).start()
start = time.time()
while time.time() < start + 2:
sum(range(10000))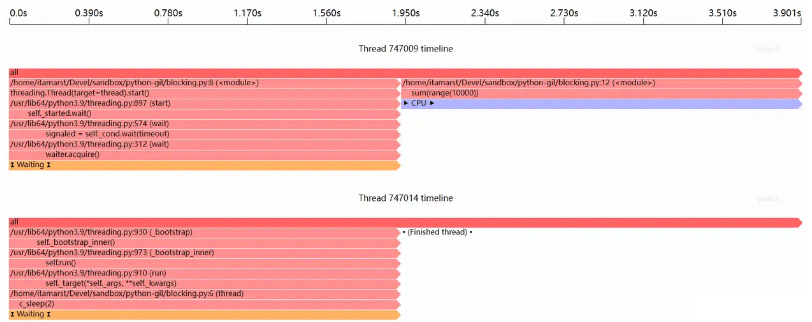
直到睡眠线程完成前,主线程无法运行;睡眠线程根本没有释放 GIL。这是因为python在调用底层语言(如C)所编写的模块时是阻塞性的调用,只有等到调用返回结果之后,本条语句才算执行结束。而对 c_sleep(2) 的调用在2秒内没有返回。在这2秒结束之前,Python 解释器循环不会运行,因此不会检查它是否应该自动释放 GIL。
这是我们深化后的对GIL的认知:
- Python 线程必须持有 GIL 才能运行代码。
- 其他 Python 线程无法获取 GIL,因此无法运行,直到当前运行的线程释放它,这会自动每 5 毫秒发生一次。
- 长时间运行(“阻塞”)的扩展代码会阻止自动切换。
模型3:非 Python 代码可以显式释放 GIL
time.sleep(3)使得线程3秒内什么都不做。如上所述,运行时间较长的拓展代码会阻止GIL在线程之间的自动切换。那么这是否意味当某一线程运行time.sleep()时,其他线程也不能运行?
让我们试试下面的代码,它尝试在主线程中并行运行 3 秒的睡眠和 5 秒的计算:
import threading
from time import time, sleep
program_start = time()
def thread():
sleep(3)
print("Sleep thread done, elapsed:", time() - program_start)
threading.Thread(target=thread).start()
# 在主线程中进行5秒的计算:
calc_start = time()
while time() < calc_start + 5:
sum(range(10000))
print("Main thread done, elapsed:", time() - program_start)运行后的结果为:
$ time python gil2.py Sleep thread done, elapsed: 3.0081260204315186 Main thread done, elapsed: 5.000330924987793 real 0m5.068s user 0m4.977s sys 0m0.011s
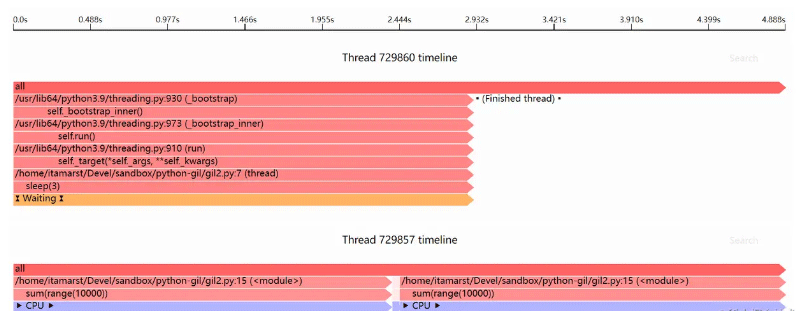
如果程序只能单线程的运行,那么程序运行时长需要8秒,3秒用于睡眠,5秒用于计算。从上边的结果可以看出,睡眠线程和主线程并行运行!
Sciagraph 性能分析器的输出如下图所示:
想要了解这个现象的原因,需要我们阅读time.sleep的实现代码:
int ret;
Py_BEGIN_ALLOW_THREADS
#ifdef HAVE_CLOCK_NANOSLEEP
ret = clock_nanosleep(CLOCK_MONOTONIC, TIMER_ABSTIME, &timeout_abs, NULL);
err = ret;
#elif defined(HAVE_NANOSLEEP)
ret = nanosleep(&timeout_ts, NULL);
err = errno;
#else
ret = select(0, (fd_set *)0, (fd_set *)0, (fd_set *)0, &timeout_tv);
err = errno;
#endif
Py_END_ALLOW_THREADS根据 PY_BEGIN/END_ALLOW_THREADS 的文档,Py_BEGIN_ALLOW_THREADS会使得程序自动的释放GIL锁,然后去执行阻塞操作,当程序运行到Py_END_ALLOW_THREADS时才会申请GIL锁。因此,上边的C实现在调用底层操作系统睡眠函数时会显式释放GIL。这是GIL释放的另一种方式,它与我们目前知道的每 5 毫秒自动切换一次是相互独立的。
任何已释放 GIL 并且不尝试申请它的代码(比如上文的sleep()期间)都不会阻塞其他申请GIL的线程。 因此,只要程序能够显式释放 GIL,我们可以并行运行任意数量的线程。
所以这是我们的第三层认知:
- 线程必须持有 GIL 才能运行 Python 代码。
- 其他线程无法获取 GIL,因此无法运行,直到当前运行的线程释放它,这会自动每 5ms 发生一次。
- 长时间运行(“阻塞”)的扩展代码会阻止自动切换。
- 然而,用 C(或其他低级语言)编写的 Python 扩展可以显式释放 GIL,从而允许一个或多个线程与持有 GIL 的线程并行运行。
模型4:调用 Python C API 需要 GIL
到目前为止,我们已经说过python调用的C代码能够在某些情况下主动释放GIL。但是,线程调用 CPython C API时都必须持有 GIL。
当线程调用CPython C API时必须持有GIL,只有很少的API不需要持有GIL
(CPython C API可以使得Python程序调用已编译的利用C/C++编写的代码片段,Python 语言和标准库的大部分核心功能都是用 C 编写的)
所以这是我们最终的认知模型:
- 线程必须持有 GIL 才能调用 CPython C API。
- 在解释器中运行的 Python 代码,例如 x = f(1, 2),会使用这些 API。 每个 == 比较、每个整数加法、每个 list.append:都需要调用 CPython C API。 因此,线程运行 Python 代码时必须持有锁。
- 其他线程无法获取 GIL,因此无法运行,直到当前运行的线程释放它,这会自动每 5ms 发生一次。
- 长时间运行(“阻塞”)的扩展代码会阻止自动切换。
- 然而,用 C(或其他低级语言)编写的 Python 扩展可以显式释放 GIL,从而允许一个或多个线程与持有 GIL 的线程并行运行。
什么场景适合利用python的并发?
当调用运行时间较长的,用C编写的API时应当主动释放GIL
python多线程最有用的情况是,线程调用长时间运行的C/C++/RUST代码,因此会长时间的不需要调用CPython C API,此时就可以让线程释放GIL从而允许其他线程运行。
不适合并发的场景:
所谓的纯python代码,指的是代码只与python内置的对象,如字典,整数,列表交互,并且代码也不会阻塞性的调用底层代码,这样的代码会频繁地使用Python C API:
l = []
for i in range(i):
l.append(i * i)此时搞线程并发并没有太大的意义
使用Python C API的低级代码
另一种不会获得太多并行性的情况是:在C/Rust扩展中需要使用大量的Python C API。例如,考虑一个读取以下字符串的 JSON 解析器:
[1, 2, 3]
解析器将:
- 读取几个字节,然后创建一个 Python 列表。
- 然后它将读取更多字节,然后创建一个 Python 整数并将其附加到列表中。
- 这种情况一直持续到数据处理完为止。
创建所有这些 Python 对象需要使用 CPython C API,因此需要持有 GIL。由于反复占有和释放 GIL 会降低程序的性能,而且大多数 JSON 文档都可以非常快速地解析。 因此,JSON解析器的开发者当然会选择在整个处理过程结束之前都不释放GIL,但这也导致json解析器解析期间,程序只能线性运行。
让我们通过观察当我们在两个线程中读取两个大文档时,Python的内置JSON解析器如何影响并行性来验证这个假设。代码如下所示:
import json
import threading
def load_json():
with open("large.json") as f:
return json.load(f)
threading.Thread(target=load_json).start()
load_json()性能分析器的结果如下所示:
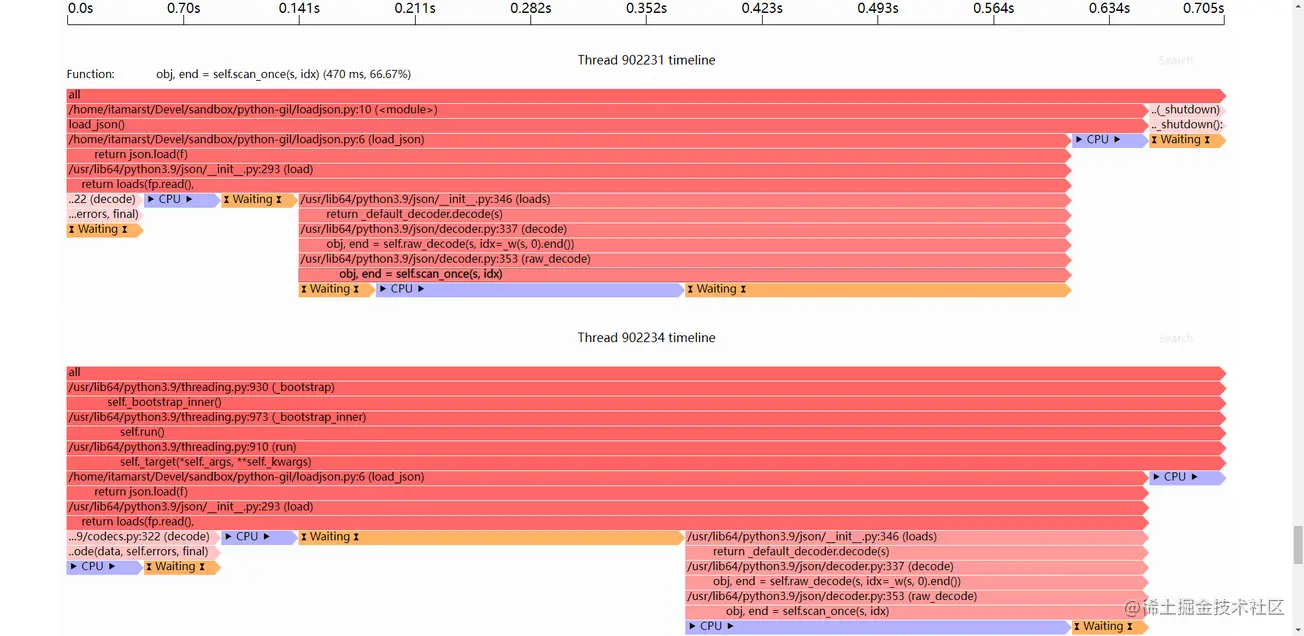
很明显,同时运行两个json解析器时,线程之间完全没有并行
加载全部内容