Python Fasttext商品评论
Together_CZ 人气:0在以往的文本分类型的任务中,基本的流程主要是就是:
- 文本数据加载
- 数据清洗
- 分词
- 向量化
- 分类模型训练
- 性能评估
这里面比如向量化和模型搭建是独立的两个节点,可以自由地进行设计,当然了也是一份工作量,今天使用的fasttext更像是一个集成的库,把向量化和分类一起做掉了,这个对于使用层面来讲就更方便了一些,不过也并不是绝对的,一般经验来说,封装程度越高的库对于个性化的开发越不友好,但是如果仅仅只是使用一下就行,能够实现自己的功能这样的想法的话倒是可以使用这种类型的库的,总之,没有绝对的最优,只有适合自己的模型。
本文主要也是基于具体的应用来体验fasttext,整体流程如下:

为了清晰展示流程,这里我用不同的颜色来标识不同的功能部分:
绿色部分为数据采集部分,这部分由于部分原因无法开放到这里
蓝色部分为数据处理部分,这部分主要完成原始数据的清洗分词等工作
黄色部分主要是实例化调用fasttext提供的模型来完成分类评估等工作
首先看下原始数据样例如下:
{
'_id': '4c671f75cc20b28264c30c2ef158f32b',
'guid': 'b2422b96a015b85d9a47c83e65f01987',
'content': 'iPhone13收到了,很喜欢的苹果手机,一直都是苹果的忠实粉丝。13手机外观真的太惊艳了,最新款的手机就是不一样,非常的好看!午夜色也是很惊艳的,是我很喜欢的颜色。外观设计非常的好看,小巧精致,很喜欢iPhone的产品。新款的相机非常好,拍摄效果强大,很适合爱美的女生拍照。拍视频的电影模式也是非常惊艳,真的太棒了,滤镜自带美颜效果,非常特别!前置摄像头也有亮点,优化升级,升级后的像素真的超棒!萌萌的摄像头,手机大小合适,握着手感很舒服。屏幕非常细腻,通透,屏幕很喜欢!新一代运行速度快了很多,系统非常流畅,屏幕120hz刷新率。电池也还不错,正常使用,续航能力还是挺久的,玩游戏也不会发烫。买了套装一年延保的,感觉还是很不错的!A15速度还是很快的,加上iOS15的加持,手机很流畅,使用了一周了,手机各方面都很不错!',
'creationTime': '2021-11-2907: 13: 51',
'isDelete': False,
'isTop': False,
'userImageUrl': 'misc.360buyimg.com/user/myjd-2015/css/i/peisong.jpg',
'topped': 0,
'replies': [
{
'id': 946189091,
'commentId': 16739194625,
'content': '谢谢您对本店的支持,我们会不断的努力,争取做的更好,我们成长的路上有您的支持,我们表示感谢,欢迎再次光临。祝您生活愉快,合家安康!',
'pin': 'jd_oMFlwVDJJjkA',
'userClient': 98,
'userImage': 'misc.360buyimg.com/user/myjd-2015/css/i/peisong.jpg',
'ip': '115.207.85.31',
'productId': 10039695828478,
'replyList': [
],
'nickname': 'jd_oMFlwVDJJjkA',
'creationTime': '2021-11-2910: 10: 54',
'parentId': 0,
'targetId': 0,
'venderShopInfo': {
'id': 10706414,
'appName': '//mall.jd.com/index-10706414.html',
'title': '京东之家官方旗舰店',
'venderId': 10955089
}
}
],
'replyCount': 28,
'score': 5,
'imageStatus': 1,
'usefulVoteCount': 28,
'userClient': 4,
'discussionId': 1006752884,
'imageCount': 8,
'anonymousFlag': 1,
'plusAvailable': 201,
'mobileVersion': '10.2.4',
'mergeOrderStatus': 2,
'productColor': '128G午夜色',
'productSize': '套装五:搭配店铺延保一年',
'textIntegral': 40,
'imageIntegral': 40,
'status': 1,
'referenceId': '10039695828478',
'referenceTime': '2021-11-0802: 31: 34',
'nickname': 'z***a',
'replyCount2': 39,
'userImage': 'misc.360buyimg.com/user/myjd-2015/css/i/peisong.jpg',
'orderId': 0,
'integral': 80,
'productSales': '[
]',
'referenceImage': 'jfs/t1/124476/38/25971/146827/622b14cfEec332c92/75f5bf4417c1fd1d.jpg',
'referenceName': '【12期免息可选】Apple苹果iPhone13(A2634)全网通5G手机128G绿色套装一:搭配90天品胜碎屏保障',
'firstCategory': 9987,
'secondCategory': 653,
'thirdCategory': 655,
'aesPin': None,
'days': 21,
'afterDays': 0,
'comp_con': 'iPhone13收到了很喜欢的苹果手机一直都是苹果的忠实粉丝13手机外观真的太惊艳了最新款的手机就是不一样非常的好看午夜色也是很惊艳的是我很喜欢的颜色外观设计非常的好看小巧精致很喜欢iPhone的产品新款的相机非常好拍摄效果强大很适合爱美的女生拍照拍视频的电影模式也是非常惊艳真的太棒了滤镜自带美颜效果非常特别前置摄像头也有亮点优化升级升级后的像素真的超棒萌的摄像头手机大小合适握着手感很舒服屏幕非常细腻通透屏幕很喜欢新一代运行速度快了很多系统非常流畅屏幕120hz刷新率电池也还不错正常使用续航能力还是挺久的玩游戏也不会发烫买了套装一年延保的感觉还是很不错的A15速度还是很快的加上iOS15的加持手机很流畅使用了一周了手机各方面都很不错',
'label': 1,
'cut_li': [
'iPhone',
'13',
'收到',
'喜欢',
'苹果',
'手机',
'一直',
'苹果',
'忠实',
'粉丝',
'13',
'手机',
'外观',
'真的',
'太',
'惊艳',
'最新款',
'手机',
'非常',
'好看',
'午夜',
'色',
'惊艳',
'喜欢',
'颜色',
'外观设计',
'非常',
'好看',
'小巧',
'精致',
'喜欢',
'iPhone',
'产品',
'新款',
'相机',
'非常',
'拍摄',
'效果',
'强大',
'适合',
'爱美',
'女生',
'拍照',
'拍',
'视频',
'电影',
'模式',
'非常',
'惊艳',
'真的',
'太棒了',
'滤镜',
'自带',
'美颜',
'效果',
'非常',
'特别',
'前置',
'摄像头',
'亮点',
'优化',
'升级',
'升级',
'像素',
'真的',
'超棒',
'萌',
'摄像头',
'手机',
'大小',
'合适',
'握',
'手感',
'舒服',
'屏幕',
'非常',
'细腻',
'通透',
'屏幕',
'喜欢',
'新一代',
'运行',
'速度',
'快',
'很多',
'系统',
'非常',
'流畅',
'屏幕',
'120hz',
'刷新率',
'电池',
'不错',
'正常',
'使用',
'续航',
'能力',
'挺久',
'玩游戏',
'不会',
'发烫',
'买',
'套装',
'一年',
'延保',
'感觉',
'不错',
'A15',
'速度',
'很快',
'加上',
'iOS15',
'加持',
'手机',
'流畅',
'使用',
'一周',
'手机',
'方面',
'不错'
],
'cut_con': 'iPhone13收到喜欢苹果手机一直苹果忠实粉丝13手机外观真的太惊艳最新款手机非常好看午夜色惊艳喜欢颜色外观设计非常好看小巧精致喜欢iPhone产品新款相机非常拍摄效果强大适合爱美女生拍照拍视频电影模式非常惊艳真的太棒了滤镜自带美颜效果非常特别前置摄像头亮点优化升级升级像素真的超棒萌摄像头手机大小合适握手感舒服屏幕非常细腻通透屏幕喜欢新一代运行速度快很多系统非常流畅屏幕120hz刷新率电池不错正常使用续航能力挺久玩游戏不会发烫买套装一年延保感觉不错A15速度很快加上iOS15加持手机流畅使用一周手机方面不错',
'label_con': '__label__1,
iPhone13收到喜欢苹果手机一直苹果忠实粉丝13手机外观真的太惊艳最新款手机非常好看午夜色惊艳喜欢颜色外观设计非常好看小巧精致喜欢iPhone产品新款相机非常拍摄效果强大适合爱美女生拍照拍视频电影模式非常惊艳真的太棒了滤镜自带美颜效果非常特别前置摄像头亮点优化升级升级像素真的超棒萌摄像头手机大小合适握手感舒服屏幕非常细腻通透屏幕喜欢新一代运行速度快很多系统非常流畅屏幕120hz刷新率电池不错正常使用续航能力挺久玩游戏不会发烫买套装一年延保感觉不错A15速度很快加上iOS15加持手机流畅使用一周手机方面不错'
}之后对原始数据进行解析处理:
# 文本去重
con_li = []
data_clear = []
for item in data:
if item["content"] not in con_li:
con_li.append(item["content"])
data_clear.append(item)
print("文本去重过滤条数:%s" % (len(data) - len(data_clear)))
print("剩余评论个数:", len(con_li)) # 剩余评论个数
def clean_txt(raw):
"""
提取清洗
"""
fil = re.compile(r"[^0-9a-zA-Z\u4e00-\u9fa5]+")
return fil.sub(" ", raw)
compress_num = 0
for i, item in enumerate(data_clear):
temp_com = item["content"]
compress_com = clean_txt(temp_com)
if compress_com != temp_com:
compress_num += 1
item["comp_con"] = compress_com
data_clear[i] = item
print("data_clear_legnth: ", len(data_clear))
for one in data_clear[:3]:
print("one: ", one)接着对清洗处理好的数据记性分词和数据组装:
# 进行结巴分词
stop_words = []
with open("cn_stopwords.txt", "r", encoding="utf-8") as f:
stop_words = f.readlines()
stop_words = [sw.strip() for sw in stop_words]
stop_words.append("\n")
data_li = []
for i, item in enumerate(data_final):
cut_li = list(jieba_fast.cut(item["comp_con"]))
cut_clear_li = [c.strip() for c in cut_li if c.strip() and c not in stop_words]
item["cut_li"] = cut_clear_li
cut_con = " ".join(cut_clear_li)
item["cut_con"] = cut_con
label_con = "__label__%s , %s" % (item["label"], item["cut_con"])
item["label_con"] = label_con
data_li.append(label_con)
data_final[i] = item
print("data_final_legnth: ", len(data_final))
for one in data_final[:3]:
print("one: ", one)处理后的数据如下:

虽然说看着有些奇怪,尤其是: __label__,但是这个没办法,fasttext需要的标准数据格式就是这个样子的。
之后就可以进行模型训练了,核心实现如下:
def train_model(ipt=None, opt=None, model="", dim=100, epoch=5, lr=0.5, loss="softmax"):
np.set_printoptions(suppress=True)
classifier = fasttext.train_supervised(
ipt, label="__label__", dim=dim, epoch=epoch, lr=lr, wordNgrams=4, loss=loss
)
"""
训练一个监督模型, 返回一个模型对象
@param input: 训练数据文件路径
@param lr: 学习率
@param dim: 向量维度
@param ws: cbow模型时使用
@param epoch: 次数
@param minCount: 词频阈值, 小于该值在初始化时会过滤掉
@param minCountLabel: 类别阈值,类别小于该值初始化时会过滤掉
@param minn: 构造subword时最小char个数
@param maxn: 构造subword时最大char个数
@param neg: 负采样
@param wordNgrams: n-gram个数
@param loss: 损失函数类型, softmax, ns: 负采样, hs: 分层softmax
@param bucket: 词扩充大小, [A, B]: A语料中包含的词向量, B不在语料中的词向量
@param thread: 线程个数, 每个线程处理输入数据的一段, 0号线程负责loss输出
@param lrUpdateRate: 学习率更新
@param t: 负采样阈值
@param label: 类别前缀
@param verbose: ??
@param pretrainedVectors: 预训练的词向量文件路径, 如果word出现在文件夹中初始化不再随机
@return model object
"""
classifier.save_model(opt)
return classifier这里同样实现了对于模型结果的评估方法:
def cal_precision_and_recall(file="test.txt"):
"""
计算每个标签 的precision和recall
"""
precision = defaultdict(int, 1)
recall = defaultdict(int, 1)
total = defaultdict(int, 1)
with open(file, encoding="utf-8") as f:
for line in f:
label, content = line.split(",", 1)
total[label.strip().strip("__label__")] += 1
labels2 = classifier.predict([content.strip()])
pre_label, sim = labels2[0][0][0], labels2[1][0][0]
recall[pre_label.strip().strip("__label__")] += 1
if label.strip() == pre_label.strip():
precision[label.strip().strip("__label__")] += 1
print("{:<10} {:<30}".format("precision", str(precision.dict)))
print("{:<10} {:<30}".format("recall", str(recall.dict)))
print("{:<10} {:<30}".format("total", str(total.dict)))
for sub in precision.dict:
pre = precision[sub] / total[sub]
rec = precision[sub] / recall[sub]
F1 = (2 * pre * rec) / (pre + rec)
print(
f"{sub.strip('__label__')} \t precision: {str(pre)} \t recall: {str(rec)} \t F1: {str(F1)}"
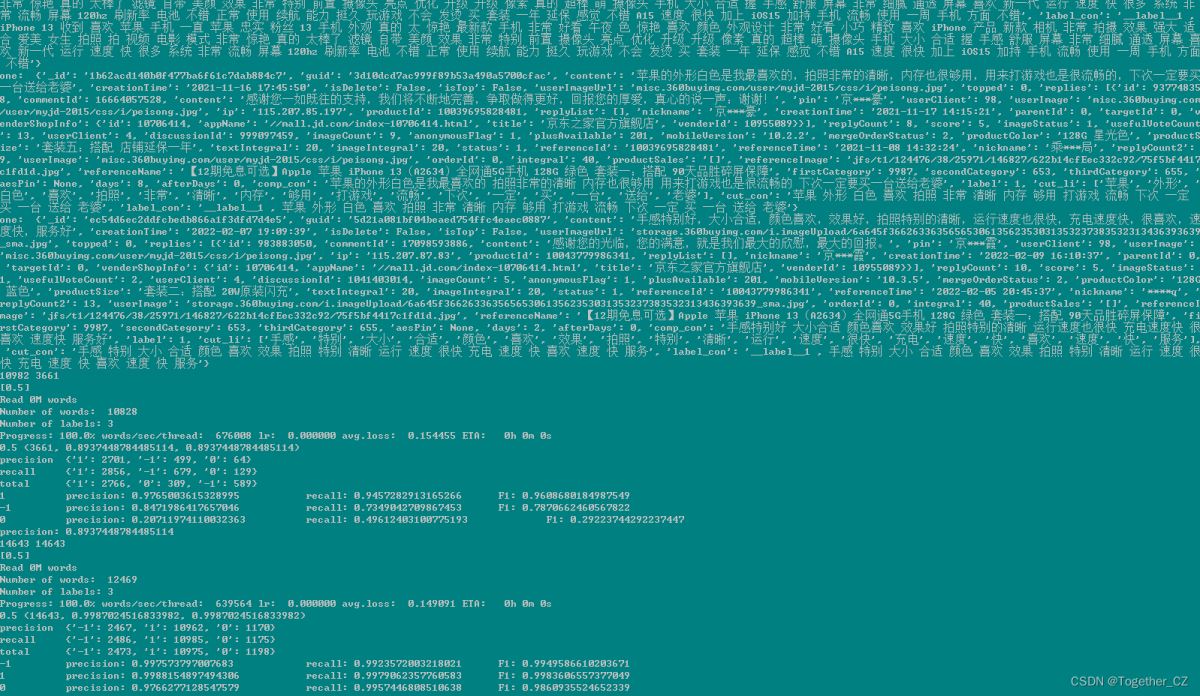
)运行结果如下所示:
加载全部内容