Python处理缺失值
Python学习与数据挖掘 人气:0前言
缺失值可能是数据科学中最不受欢迎的值,然而,它们总是在身边。忽略缺失值也是不合理的,因此我们需要找到有效且适当地处理它们的方法。
在本文中,我们将介绍 8 种不同的方法来解决缺失值问题,哪种方法最适合特定情况取决于数据和任务。
让我们首先创建一个示例数据框并向其中添加一些缺失值。

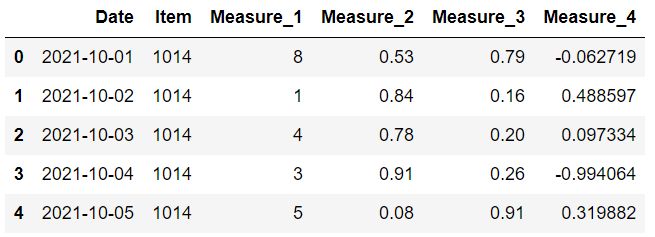
我们有一个 10 行 6 列的数据框。
下一步是添加缺失值。 我们将使用 loc 方法选择行和列组合,并使它们等于“np.nan”,这是标准缺失值表示之一。

这是数据框现在的样子:

item 和 measure 1 列具有整数值,但由于缺少值,它们已被向上转换为浮点数。
在 Pandas 1.0 中,引入了整数类型缺失值表示 (),因此我们也可以在整数列中包含缺失值。 但是,我们需要显式声明数据类型。

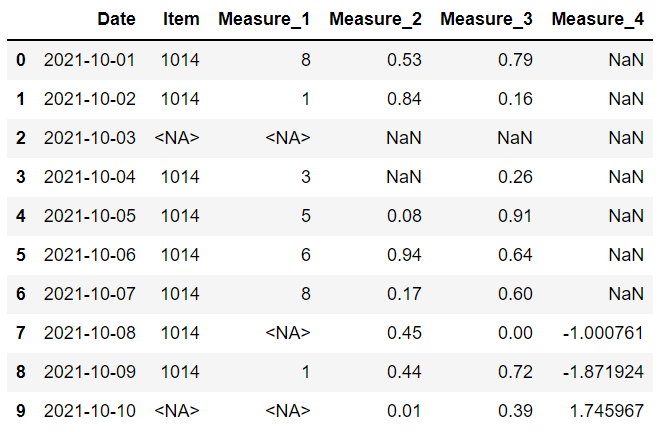
尽管有缺失值,我们现在可以保留整数列。
现在我们有一个包含一些缺失值的数据框。 是时候看看处理它们的不同方法了。
1. 删除有缺失值的行或列
一种选择是删除包含缺失值的行或列。


使用默认参数值,dropna 函数会删除包含任何缺失值的行。数据框中只有一行没有任何缺失值。同时我们还可以选择使用轴参数删除至少有一个缺失值的列。

2. 删除只有缺失值的行或列
另一种情况是有一列或一行充满缺失值。 这样的列或行是无用的,所以我们可以删除它们。
dropna 函数也可以用于此目的。 我们只需要改变 how 参数的值。

3. 根据阈值删除行或列
基于“any”或“all”的删除并不总是最好的选择。 我们有时需要删除具有“大量”或“一些”缺失值的行或列。
我们不能将这样的表达式分配给 how 参数,但 Pandas 为我们提供了一种更准确的方法,即 thresh 参数。
例如,“thresh=4”意味着至少有 4 个非缺失值的行将被保留。 其他的将被丢弃。
我们的数据框有 6 列,因此将删除具有 3 个或更多缺失值的行。

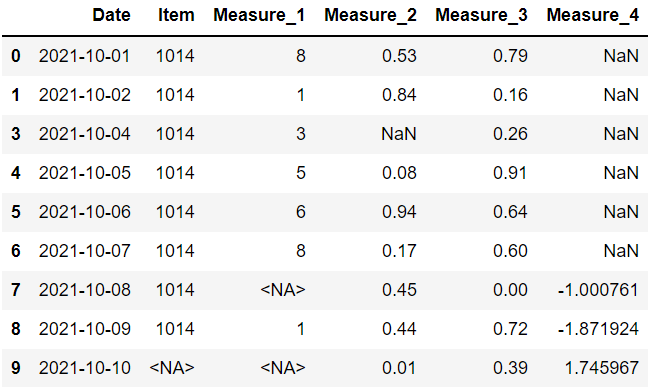
只有第三行有 2 个以上的缺失值,所以它是唯一一个被丢弃的。
4. 基于特定的列子集删除
在删除列时,我们可以只考虑部分列。
dropna 函数的子集参数用于此任务。 例如,我们可以删除在度量 1 或度量 2 列中有缺失值的行,如下所示:

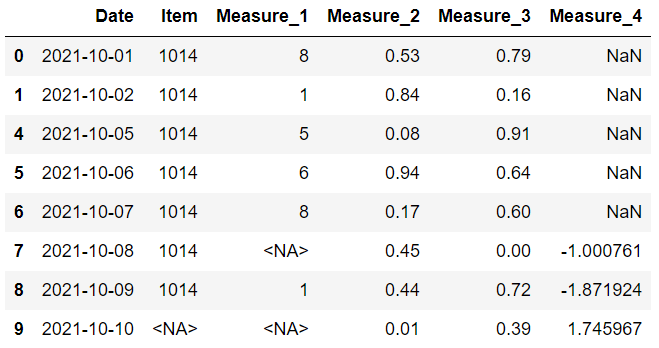
到目前为止,我们已经看到了根据缺失值删除行或列的不同方法。放弃并不是唯一的选择。 在某些情况下,我们可能会选择填充缺失值而不是删除它们。
事实上,填充可能是更好的选择,因为数据意味着价值。 如何填补缺失值,当然取决于数据的结构和任务。
fillna 函数用于填充缺失值。
5. 填充一个常数值
我们可以选择一个常量值来替代缺失值。如果我们只给 fillna 函数一个常量值,它将用该值替换数据框中的所有缺失值。
更合理的方法是为不同的列确定单独的常量值。 我们可以将它们写入字典并将其传递给 values 参数。

item 列中的缺失值替换为 1014,而 measure 1 列中的缺失值替换为 0。
6. 填充聚合值
另一种选择是使用聚合值,例如平均值、中位数或众数。
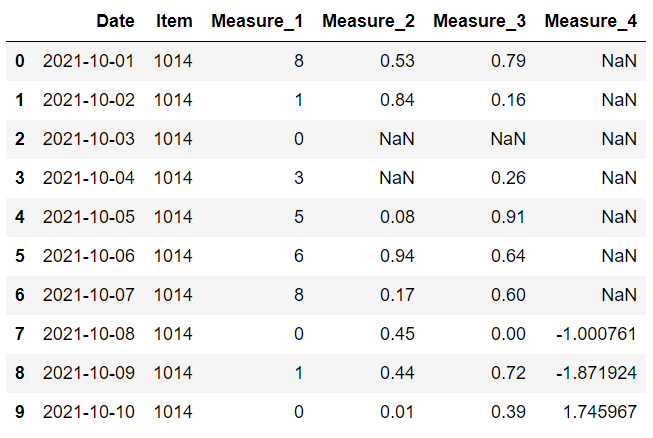
下面这行代码用该列的平均值替换了第 2 列中的缺失值。
7. 替换为上一个或下一个值
可以用该列中的前一个或下一个值替换该列中的缺失值。在处理时间序列数据时,此方法可能会派上用场。 假设您有一个包含每日温度测量值的数据框,但缺少一天的温带。 最佳解决方案是使用第二天或前一天的温度。
fillna 函数的方法参数用于执行此任务。

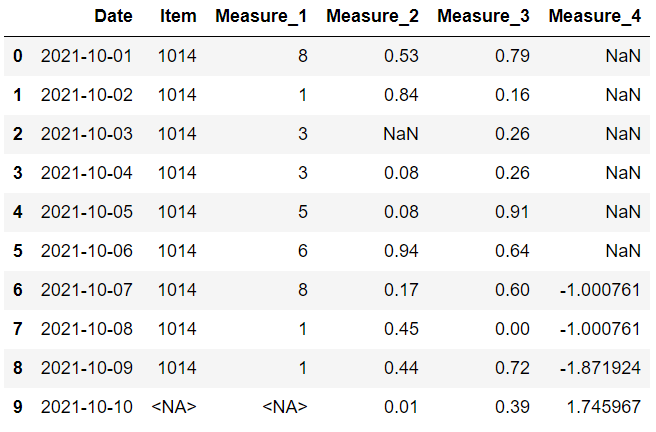
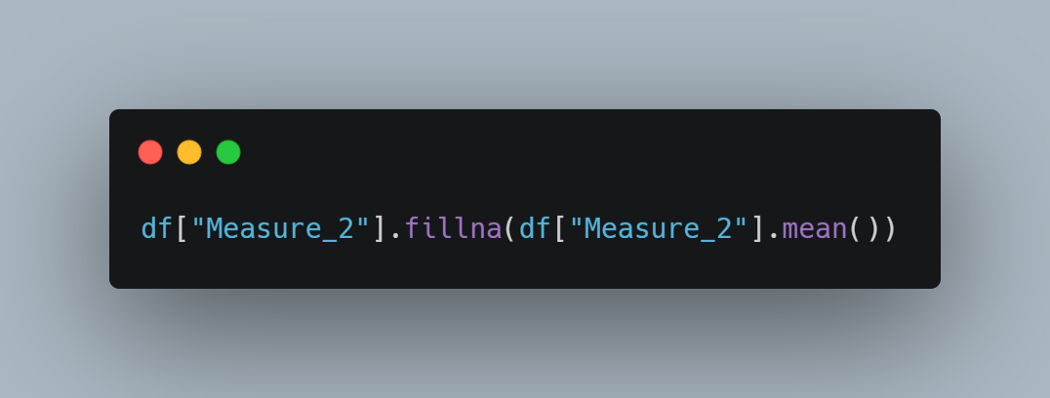
“bfill”向后填充缺失值,以便将它们替换为下一个值。看看最后一栏。 缺失值被替换到第一行。 这可能不适合某些情况。
值得庆幸的是,我们可以限制用这种方法替换的缺失值的数量。 如果我们将 limit 参数设置为 1,那么一个缺失值只能用它的下一个值替换。 后面的第二个或第三个值将不会用于替换。
8. 使用另一个数据框填充
我们还可以将另一个数据帧传递给 fillna 函数。 新数据框中的值将用于替换当前数据框中的缺失值。
将根据行索引和列名称选择值。 例如,如果 item 列的第二行中存在缺失值,则将使用新数据框中相同位置的值。

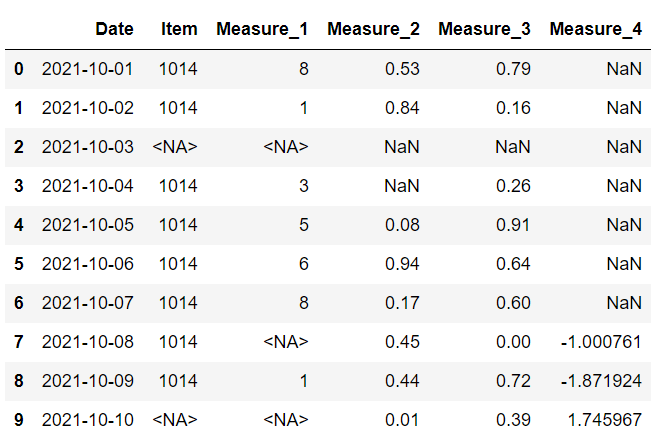
以上是具有相同列的两个数据框。 第一个 没有任何缺失值。
我们可以使用 fillna 函数如下:
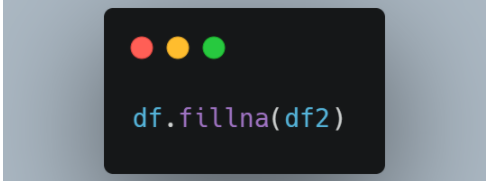
df 中的值将替换为 df2 中关于列名和行索引的值。
总结
缺失将永远存在于我们的生活中。 没有最好的方法来处理它们,但我们可以通过应用准确合理的方法来降低它们的影响。我们已经介绍了 8 种不同的处理缺失值的方法,使用哪一个取决于数据和任务。
加载全部内容