Python 可视化
Python编程学习圈 人气:0前言:
我们平常会使用很多社交媒体,如微信、微博、抖音等等,在这些平台上面,我们会关注某些KOL,同时自己身边的亲朋好友也会来关注我们,成为我们自己的粉丝。慢慢地,关注和粉丝随着时间不断累积,这层关系网络也会不断地壮大,很多信息也是通过这样的关系网络不断向外传播。因此,分析这些社交网络对于我们做出各项决策来说也是至关重要的。
今天我们就用一些Python的第三方库来进行社交网络的可视化

数据来源
本案例用的数据是来自领英(Linkedin)的社交关系数据。由于作者之前在美国读书,并且在国外找实习、找工作,都是通过领英投递简历、联系同事等,久而久之也逐渐地形成了自己的社交网络,将这部分的社交数据下载下来,然后用pandas模块读取

由于涉及隐私信息,数据就不便提供了。如果你有领英账号,可以通过设置里的“获取资料副本”导出这样一份CSV关系数据。或者也可以按照这个表头自己生成一份假数据:

数据的读取和清洗
首先导入需要用到的模块:
import pandas as pd import janitor import datetime from IPython.core.display import display, HTML from pyvis import network as net import networkx as nx
读取所需要用到的数据集:
df_ori = pd.read_csv("Connections.csv", skiprows=3)
df_ori.head()接下来我们进行数据的清洗,具体的思路就是将空值去除掉,并且数据集当中的“Connected on”这一列,内容是日期,但是数据类型却是字符串,因此我们也需要将其变成日期格式。
df = (
df_ori
.clean_names() # 去除掉字符串中的空格以及大写变成小写
.drop(columns=['first_name', 'last_name', 'email_address']) # 去除掉这三列
.dropna(subset=['company', 'position']) # 去除掉company和position这两列当中的空值
.to_datetime('connected_on', format='%d %b %Y')
)输出:
company position connected_on
0 xxxxxxxxxx Talent Acquisition 2021-08-15
1 xxxxxxxxxxxx Associate Partner 2021-08-14
2 xxxxx 猎头顾问 2021-08-14
3 xxxxxxxxxxxxxxxxxxxxxxxxx Consultant 2021-07-26
4 xxxxxxxxxxxxxxxxxxxxxx Account Manager 2021-07-19
数据的分析与可视化
来看一下这些人脉中,分别都是在哪些公司工作的
df['company'].value_counts().head(10).plot(kind="barh").invert_yaxis()
输出:
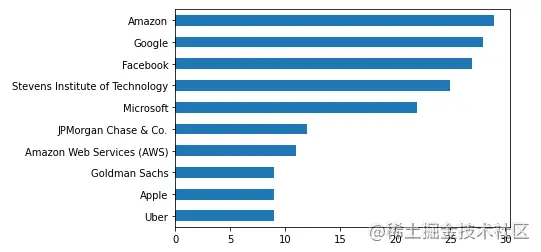
再来看一下我的人脉网络中,大多都是什么职业的
df['position'].value_counts().head(10).plot(kind="barh").invert_yaxis()
输出:

接下来我们绘制社交网络的可视化图表。但是在这之前呢,需要先说明几个术语,每一个社交网络都包含:
- 节点:社交网络当中的每个参与者
- 边:代表着每一个参与者的关系以及关系的紧密程度
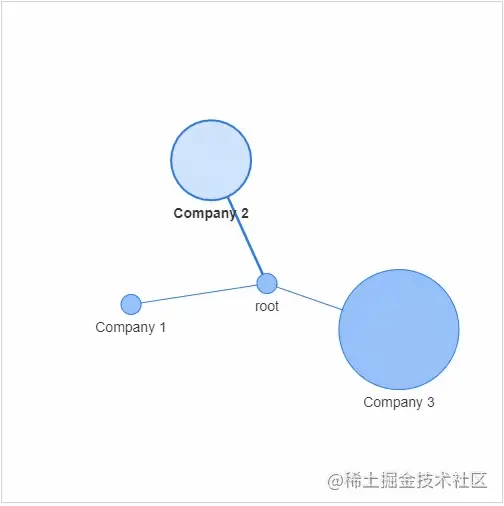
我们先来简单的绘制一个社交网络,主要用到的是networkx模块以及pyvis模块,
g = nx.Graph() g.add_node(0, label = "root") # intialize yourself as central node g.add_node(1, label = "Company 1", size=10, title="info1") g.add_node(2, label = "Company 2", size=40, title="info2") g.add_node(3, label = "Company 3", size=60, title="info3")
我们先是建立了4个节点,也分别给他们命名,其中的参数size代表着节点的大小,然后我们将这些个节点相连接
g.add_edge(0, 1) g.add_edge(0, 2) g.add_edge(0, 3)
最后出来的样子如下图:
我们先从人脉中,他们所属的公司来进行网络的可视化,首先我们对所属的公司做一个统计排序
df_company = df['company'].value_counts().reset_index() df_company.columns = ['company', 'count'] df_company = df_company.sort_values(by="count", ascending=False) df_company.head(10)
输出:
company count
0 Amazon xx
1 Google xx
2 Facebook xx
3 Stevens Institute of Technology xx
4 Microsoft xx
5 JPMorgan Chase & Co. xx
6 Amazon Web Services (AWS) xx
9 Apple x
10 Goldman Sachs x
8 Oracle x
然后我们来绘制社交网络的图表:
# 实例化网络
g = nx.Graph()
g.add_node('myself') # 将自己放置在网络的中心
# 遍历数据集当中的每一行
for _, row in df_company_reduced.iterrows():
# 将公司名和统计结果赋值给新的变量
company = row['company']
count = row['count']
title = f"<b>{company}</b> – {count}"
positions = set([x for x in df[company == df['company']]['position']])
positions = ''.join('<li>{}</li>'.format(x) for x in positions)
position_list = f"<ul>{positions}</ul>"
hover_info = title + position_list
g.add_node(company, size=count*2, title=hover_info, color='#3449eb')
g.add_edge('root', company, color='grey')
# 生成网络图表
nt = net.Network(height='700px', width='700px', bgcolor="black", font_color='white')
nt.from_nx(g)
nt.hrepulsion()
nt.show('company_graph.html')
display(HTML('company_graph.html'))输出:

同样,我们再来可视化一下人脉中各种岗位的分布。
先做一个统计排序:
df_position = df['position'].value_counts().reset_index() df_position.columns = ['position', 'count'] df_position = df_position.sort_values(by="count", ascending=False) df_position.head(10)
输出:
position count
0 Software Engineer xx
1 Data Scientist xx
2 Senior Software Engineer xx
3 Data Analyst xx
4 Senior Data Scientist xx
5 Software Development Engineer xx
6 Software Development Engineer II xx
7 Founder xx
8 Data Engineer xx
9 Business Analyst xx
然后进行网络图的绘制
g = nx.Graph()
g.add_node('myself') # 将自己放置在网络的中心
for _, row in df_position_reduced.iterrows():
# 将岗位名和统计结果赋值给新的变量
position = row['position']
count = row['count']
title = f"<b>{position}</b> – {count}"
positions = set([x for x in df[position == df['position']]['position']])
positions = ''.join('<li>{}</li>'.format(x) for x in positions)
position_list = f"<ul>{positions}</ul>"
hover_info = title + position_list
g.add_node(position, size=count*2, title=hover_info, color='#3449eb')
g.add_edge('root', position, color='grey')
# 生成网络图表
nt = net.Network(height='700px', width='700px', bgcolor="black", font_color='white')
nt.from_nx(g)
nt.hrepulsion()
nt.show('position_graph.html')输出:

加载全部内容