C语言 编译过程
清风自在 流水潺潺 人气:0一、初识编译器
编译器是一个广义的概念,真正的编译器由下面几个模块组成,真正的编译器是进行语法分析和语义分析的。
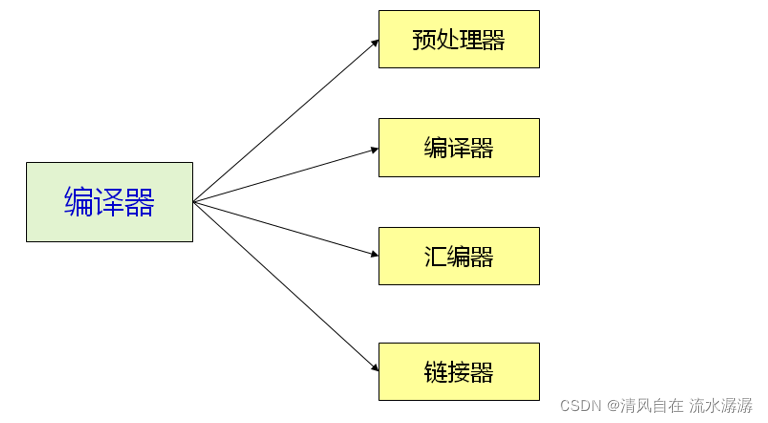
二、程序被编译的过程
如下,file.i 是中间代码,file.s 是一个汇编文件,file.o 是二进制文件。
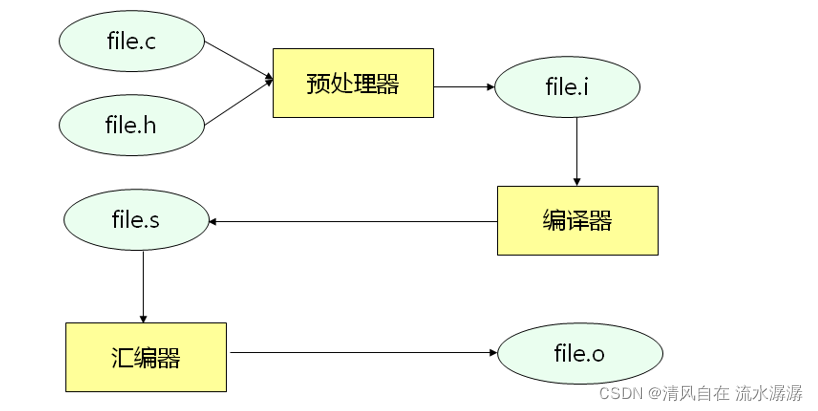
预编译
- 处理所有的注释,以空格代替
- 将所有的 #define 删除,并且展开所有的宏定义
- 处理条件编译指令
#if, #ifdef, #elif,#else,#endif - 处理 #include,展开被包含的文件
- 保留编译器需要使用的 #pragma 指令
预处理指令示例:gcc -E file.c -o file.i
编译
对预处理文件进行词法分析,语法分析和语义分析
- 词法分析:分析关键字,标示符,立即数等是否合法
- 语法分析:分析表达式是否遵循语法规则
- 语义分析:在语法分析的基础上进一步分析表达式是否合法
分析结束后进行代码优化生成相应的汇编代码文件
编译指令示例:gcc -S file.i -o file.s
汇编
- 汇编器将汇编代码转变为机器的可以执行指令
- 每条汇编语句几乎都对应一条机器指令
汇编指令示例:gcc -c file.s -o file.o
下面看一个源代码单步编译的示例:
demo.h
/*
This is a header file.
*/
char* p = "Autumn";
int i = 0;demo.c
#include "demo.h"
// Begin to define macro
#define GREETING "Hello world!"
#define INC(x) x++
// End
int main()
{
p = GREETING;
INC(i);
return 0;
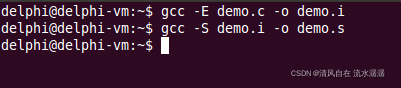
}输入 gcc -E demo.c -o demo.i,如下:

然后就生成了 demo.i 文件,如下:
# 1 "demo.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "demo.c"
# 1 "demo.h" 1
# 9 "demo.h"
char* p = "Autumn";
int i = 0;
# 2 "demo.c" 2
# 11 "demo.c"
int main()
{
p = "Hello world!";
i++;
return 0;
}可以看到注释都没有了, demo.h 文件的全局变量被复制过来,宏也被替换掉了,#开头的信息是给后续编译器使用的。
输入gcc -S demo.i -o demo.s,如下:
然后就生成了 demo.o 文件,如下:
.file "demo.c" .globl p .section .rodata .LC0: .string "Autumn" .data .align 4 .type p, @object .size p, 4 p: .long .LC0 .globl i .bss .align 4 .type i, @object .size i, 4 i: .zero 4 .section .rodata .LC1: .string "Hello world!" .text .globl main .type main, @function main: pushl %ebp movl %esp, %ebp movl $.LC1, p movl i, %eax addl $1, %eax movl %eax, i movl $0, %eax popl %ebp ret .size main, .-main .ident "GCC: (Ubuntu/Linaro 4.4.4-14ubuntu5.1) 4.4.5" .section .note.GNU-stack,"",@progbits
最后输入gcc -c demo.s -o demo.o,如下:
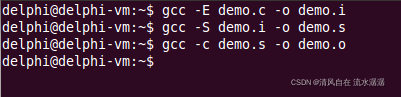
这样就生成了一个 .o 文件
最后链接器出场了,输入 gcc demo.o,如下:
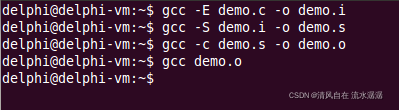
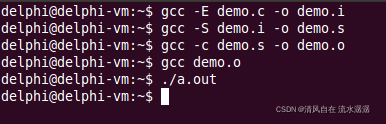
这样就生成一个 a.out 文件:

这样就能运行了
三、小结
编译过程分为预处理,编译,汇编和链接四个阶段
- 预处理:处理注释,宏以及已经以 # 开头的符号
- 编译:进行词法分析,语法分析和语义分析等
- 汇编:将汇编代码翻译为机器指令的目标文件
- 链接:链接到一起生成可执行程序
加载全部内容