Python TFIDF提取文本关键词
云朵君 人气:4前言
关键词提取是从简明概括长文本内容的文档中,自动提取一组代表性短语。关键词是一个简短的短语(通常是一到三个单词),高度概括了文档的关键思想并反映一个文档的内容,清晰反映讨论的主题并提供其内容的摘要。
关键字/短语提取过程包括以下步骤:
- 预处理: 文档处理以消除噪音。
- 形成候选tokens:形成 n-gram tokens作为候选关键字。
- 关键字加权:使用向量器 TFIDF 计算每个 n-gram token (关键短语) 的 TFIDF 权重。
- 排序: 根据 TFIDF 权重对候选词进行降序排列。
- 选择前 N 个关键字。
词频逆文档频率(TFIDF)
TFIDF 的工作原理是按比例增加一个词语在文档中出现的次数,但会被它所在的文档数量抵消。因此,诸如“这个”、“是”等在所有文档中普遍出现的词没有被赋予很高的权重。但是,在少数文档中出现太多次的单词将被赋予更高的权重排名,因为它很可能是指示文档的上下文。

Term Frequency
Term Frequency --> 词频
词频定义为单词 (i) 在文档 (j) 中出现的次数除以文档中的总单词数。
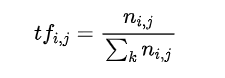
Inverse Document Frequency
Inverse Document Frequency --> 逆文档频率
逆文档频率是指文档总数除以包含该单词的文档数的对数。添加对数是为了抑制非常高的 IDF 值的重要性。

TFIDF
TFIDF是通过将词频乘以逆文档频率来计算的。
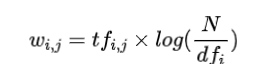
Python 中的 TFIDF
我们可以使用 sklearn 库轻松执行 TFIDF 向量化。
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(corpus) print(X.toarray())
Python 库准备
import spacy
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import regex as re
import string
import pandas as pd
import numpy as np
import nltk.data
import re
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('averaged_perceptron_tagger')
from nltk.stem import WordNetLemmatizer
from nltk import word_tokenize, sent_tokenize, pos_tag
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
[nltk_data] Downloading package wordnet to /root/nltk_data...
[nltk_data] Package wordnet is already up-to-date!
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Package punkt is already up-to-date!
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] /root/nltk_data...
[nltk_data] Package averaged_perceptron_tagger is already up-to-
[nltk_data] date!
主要使用的是nltk库,如果你没有使用过该库,除了需要pip install nltk,另外还要下载诸如停用词等。或者直接到官网上把整个nltk_data下载下来。

准备数据集
将使用 Theses100 标准数据集[1]来评估关键字提取方法。这 100 个数据集由新西兰怀卡托大学的 100 篇完整的硕士和博士论文组成。这里使用一个只包含 99 个文件的版本。删除其余不包含关键字打文件。论文主题非常多样化:从化学、计算机科学和经济学到心理学、哲学、历史等。每个文档的平均重要关键字数约为 7.67。
你可以将所需的数据集下载到本地。本文已经假设你电脑本地已经存在该数据文件。将编写一个函数来检索文档及其关键字并将输出存储为数据框。
为了演示,我们只选择了其中20个文档。
import os path = "./data/theses100/" all_files = os.listdir(path + "docsutf8") all_keys = os.listdir(path + "keys") print(len(all_files)," files n",all_files, "n", all_keys) # 不一定要排序

all_documents =[]
all_keys = []
all_files_names = []
for i, fname in enumerate(all_files):
with open(path+'docsutf8/'+fname) as f:
lines = f.readlines()
key_name= fname[:-4 ]
with open(path+'keys/'+key_name+'.key') as f:
k = f.readlines()
all_text = ' '.join(lines)
keyss = ' '.join(k)
all_documents.append(all_text)
all_keys.append(keyss.split("n"))
all_files_names.append(key_name)
import pandas as pd
dtf = pd.DataFrame({'goldkeys': all_keys,
'text': all_documents})
dtf.head()

文本预处理
预处理包括标记化、词形还原、小写转换、去除数字、去除空格、去除短于三个字母的单词、去除停用词、去除符号和标点符号。实现这些功能的函数定义为preprocess_text,我附在文末,按需查看。
对于词形还原, 使用了 WordNetLemmatizer 它不会改变单词的词根。
dtf['cleaned_text'] = dtf.text.apply(lambda x: ' '.join(preprocess_text(x))) dtf.head()

之后,清理每个文档的 goldkeys 并执行词形还原,以便稍后与TFIDF使用Python算法生成的单词进行匹配。
# 清理基本关键字,删除空格和噪音 def clean_orginal_kw(orginal_kw): orginal_kw_clean =[] for doc_kw in orginal_kw: temp =[] for t in doc_kw: tt = ' '.join(preprocess_text(t)) if len(tt.split())>0: temp.append(tt) orginal_kw_clean.append(temp) return orginal_kw_clean orginal_kw= clean_orginal_kw(dtf['goldkeys']) orginal_kw[0:1]

TFIDF关键词提取
1.生成 n-gram 并对其进行加权
首先,从文本特征提取包中导入 Tfidf Vectorizer。
其次,设置参数 use_idf=True ,即希望将逆文档频率 IDF 与词频一起使用。它的最大值是 max_df = 0.5,这意味着我们只想要出现在 50% 的文档中的词条(本文中,对应 99 个中的 49 个文档)。如果一个词语在超过 50 个文档中均出现过,它将被删除,因为它在语料库级别被认为是无歧视性的。指定n-gram的范围从1到3(可以设置更大的数字,但是根据当前数据集的统计,最大的比例是1-3长度的关键字)
然后生成文档的向量。
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(use_idf=True, max_df=0.5, min_df=1, ngram_range=(1,3)) vectors = vectorizer.fit_transform(dtf['cleaned_text'])
再者,对于每个文档,均需要构建一个字典( dict_of_tokens ),其中键是单词,值是 TFIDF 权重。创建一个tfidf_vectors列表来存储所有文档的字典。
dict_of_tokens={i[1]:i[0] for i in vectorizer.vocabulary_.items()}
tfidf_vectors = [] # all deoc vectors by tfidf
for row in vectors:
tfidf_vectors.append({dict_of_tokens[column]:value for
(column,value) in
zip(row.indices,row.data)})
看看这个字典包含的第一个文档
print("The number of document vectors = ", len(tfidf_vectors) ,
"\nThe dictionary of document[0] :", tfidf_vectors[0])
第一个文档的字典内容
字典的数量与文档的数量相同,第一个文档的字典包含每个 n-gram 及其 TFIDF 权重。
2. 按 TFIDF 权重对关键短语进行排序
下一步是简单地根据 TFIDF 权重对每个字典中的 n-gram 进行降序排序。设置 reverse=True 选择降序排序。
doc_sorted_tfidfs =[] # 带有tfidf权重的文档特征列表 # 对文档的每个字典进行排序 for dn in tfidf_vectors: newD = sorted(dn.items(), key=lambda x: x[1], reverse=True) newD = dict(newD) doc_sorted_tfidfs.append(newD)
现在可以获得没有权重的关键字列表
tfidf_kw = [] for doc_tfidf in doc_sorted_tfidfs: ll = list(doc_tfidf.keys()) tfidf_kw.append(ll)
为第一个文档选择前 5 个关键字。
TopN= 5 print(tfidf_kw[0][0:TopN])
['cone', 'cone tree', 'dimensional', 'shadow', 'visualization']
性能评估
以上方法足以使用其提取关键词或关键短语,但在下文中,希望根据此类任务的标准度量,以科学的方式评估该方法的有效性。
首先使用精确匹配进行评估,从文档中自动提取的关键短语必须与文档的黄金标准关键字完全匹配。
def get_exact_intersect(doc_orginal_kw, doc_my_kw):
general = []
for kw in doc_my_kw:
for kww in doc_orginal_kw:
l_my = len(kw.split())
l_org = len(kww.split())
if (kw == kww):
# print("exact matching ========", kw, kww)
if kww not in general:
general.append(kww)
return general
get_exact_intersect(orginal_kw[0], tfidf_kw[0])
['visualization', 'animation', 'unix', 'dimension', 'cod', 'icon', 'shape', 'fisheye lens', 'rapid prototyping', 'script language', 'tree structure', 'programming language']
关键字提取是一个排名问题。最常用的排名度量之一是"Mean average precision at K(K处的平均精度), MAP@K"。为了计算MAP@K ,首先将 " precision at K elements(k处的精度), p@k "视为一个文档的排名质量的基本指标。
def apk(kw_actual, kw_predicted, k=10): if len(kw_predicted)>k: kw_predicted = kw_predicted[:k] score = 0.0 num_hits = 0.0 for i,p in enumerate(kw_predicted): if p in kw_actual and p not in kw_predicted[:i]: num_hits += 1.0 score += num_hits / (i+1.0) if not kw_actual: return 0.0 return score / min(len(kw_actual), k) def mapk(kw_actual, kw_predicted, k=10): return np.mean([apk(a,p,k) for a,p in zip(kw_actual, kw_predicted)])
此函数apk接受两个参数:TFIDF 方法预测的关键字列表(kw_predicted)和黄金标准关键字列表(kw_actual)。k 的默认值为 10。这里在 k=[5,10,20,40] 处打印 MAP 值。
for k in [5, 10,20,40]:
mpak= mapk(orginal_kw, tfidf_kw, k)
print("mean average precession @",k,
'= {0:.4g}'.format(mpak))
mean average precession @ 5 = 0.2037 mean average precession @ 10 = 0.1379 mean average precession @ 20 = 0.08026 mean average precession @ 40 = 0.05371
在本文中,我们介绍了一种使用TFIDF和Python从文档中提取关键字的简单方法。用Python编写代码并逐步解释。将MAP标准作为一个排序任务来评价该方法的性能。这种方法虽然简单,但非常有效,被认为是该领域的有力基线之一。
附录
文本预处理preprocess_text函数。
def preprocess_text(text):
# 1. 将其标记为字母符号
text = remove_numbers(text)
text = remove_http(text)
text = remove_punctuation(text)
text = convert_to_lower(text)
text = remove_white_space(text)
text = remove_short_words(text)
tokens = toknizing(text)
# 2. POS tagging
pos_map = {'J': 'a', 'N': 'n', 'R': 'r', 'V': 'v'}
pos_tags_list = pos_tag(tokens)
# print(pos_tags)
# 3. 小写变换和词形还原
lemmatiser = WordNetLemmatizer()
tokens = [lemmatiser.lemmatize(w.lower(),
pos=pos_map.get(p[0], 'v'))
for w, p in pos_tags_list]
return tokens
def convert_to_lower(text):
# 小写转换
return text.lower()
def remove_numbers(text):
# 除去数字
text = re.sub(r'\d+' , '', text)
return text
def remove_http(text):
# 除去网址
text = re.sub("https?:\/\/t.co\/[A-Za-z0-9]*", ' ', text)
return text
def remove_short_words(text):
# 去除短于三个字母的单词
text = re.sub(r'\b\w{1,2}\b', '', text)
return text
def remove_punctuation(text):
# 去除符号和标点符号
punctuations = '''!()[]{};«№»:'"\,`<>./?@=#$-(%^)+&[*_]~'''
no_punct = ""
for char in text:
if char not in punctuations:
no_punct = no_punct + char
return no_punct
def remove_white_space(text):
# 去除空格
text = text.strip()
return text
def toknizing(text):
stp = my_stopwords
#stops = set(stopwords.words('english'))
stop_words = set(stp)
tokens = word_tokenize(text)
## 从tokens中去除停用词
result = [i for i in tokens if not i in stop_words]
return result加载全部内容