C++ atomic 和 memory ordering
pokpok 人气:0如果不使用任何同步机制(例如 mutex 或 atomic),在多线程中读写同一个变量,那么,程序的结果是难以预料的。简单来说,编译器以及 CPU 的一些行为,会影响到程序的执行结果:
- 即使是简单的语句,C++ 也不保证是原子操作。
- CPU 可能会调整指令的执行顺序。
- 在 CPU cache 的影响下,一个 CPU 执行了某个指令,不会立即被其它 CPU 看见。
利用 C++ 的 atomic<T> 能完成对象的原子的读、写以及RMW(read-modify-write),而参数 std::memory_order 规定了如何围绕原子对象的操作进行排序。memory order 内存操作顺序其实是 内存一致性模型 (Memory Consistency Model),解决处理器的 write 操作什么时候能够影响到其他处理器,或者说解决其他处理处理器什么时候能够观测到当且 写CPU/写线程 写入内存的值,有了 memory odering,我们就能知道其他处理器是怎么观测到 store 指令的影响的。
一致模型有很多种,在 Wikipedia 里面搜索 Consistency model 即可看到,目前 C++ 所用到有 Sequential Consistency 和 Relaxed Consistency 以及 Release consistency。
Memory Operation Ordering
我们所编写的程序会定义一系列的 load 和 store 操作,也就是 Program ordering,这些 load 和 store 的操作应用在内存上就有了内存操作序(memory operation ordering),一共有四种内存操作顺序的限制,不同的内存一致模型需要保持不同级别的操作限制,其中 W 代表写,R 代表读:
- W -> R:写入内存地址 X 的操作必须比在后面的程序定义序列的读取地址 Y 之前提交 (commit), 以至于当读取内存地址 Y 的时候,写入地址 X 的影响已经能够在读取Y时被观测到。
- R -> R: 读取内存地址 X 的操作必须在后序序列中的读取内存地址 Y 的操作之前提交。
- R -> W:读取内存地址 X 的操作必须在后序序列中读取内存地址 Y 的操作之前提交。
- W -> W:写入内存地址 X 的操作必须在后续序列中写入内存地址 Y 的操作之前提交。
提交的意思可以理解为,后面的操作需要等前面的操作完全执行完才能进行下一个操作。
Sequential consistency
序列一致是 Leslie Lamport 提出来的,如果熟悉分布式共识算法 Paxos ,那么应该不陌生这位大科学家,而序列一致的定义是:
- the result of any execution is the same as-if (任何一种执行结果都是相同的就好像)
- the operations of all threads are executed in some sequential order (所有线程的操作都在某种次序下执行)the operations of each thread appear in this sequence in the order specified by their program (在全局序列中的,各个线程内的操作顺序由程序指定的一致)
组合起来:全局序列中的操作序列要和线程所指定的操作顺序要对应,最终的结果是所有线程指定顺序操作的排列,不能出现和程序指定顺序组合不出来的结果。
怎么做会违反 sequcential consistency(SC)?也就是 SC 的反例是什么?
- 乱序执行 (out-of-order)
- 内存访问重叠,写A的过程中读取A,宽于计算机word的,64位机器写128位变量
更加形象的理解可以从内存的角度来看:
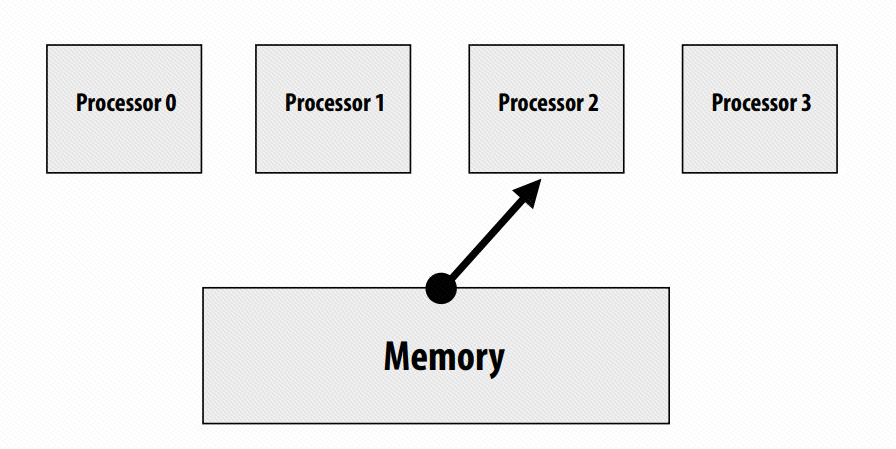
所有的处理器都按照 program order 发射 load 和 store 的操作,而内存一个地一个地从上面 4 个处理器中读取指令,并且仅当完成一个操作后才会去执行下一个操作,类似于多个 producer 一个 consumer 的情况。
(Lamport 一句话,让我为他理解了一下午)
SC 需要保持所有的内存操作序(memory operation ordering),也是最严格的一种,并且 SC 是 c++ atomic<T> 默认的以一种内存模型,对应 std::memory_order_seq_cst,可以看到标准库中的函数定义将其设置为了默认值:
bool
load(memory_order __m = memory_order_seq_cst) const noexcept
{ return _M_base.load(__m); }Relaxed Consistency
松弛内存序,对应的 std::memory_order_relaxed,在 cppreference 上的说明是:"不保证同步操作,不会将一定的顺序强加到并发内存访问上,只保证原子性和修改顺序一致性",并且通常用于计数器,比如 shared_ptr 的引用计数。
松弛内存序不再保证 W -> R,不相互依赖的读写操作可以在 write 之前或者在同一时间段并行处理。(读内存并不是想象中的那么简单,有内存寻址过程,将内存数据映射到 cache block,发送不合法位用于缓存替换)

好处是什么?性能,执行命令的写操作的延迟都被抹去了,cpu 能够更快的执行完一段带有读写的指令序列。
具体实现是通过在 cpu 和 cache 之间加入一个 write buffer,如下图:
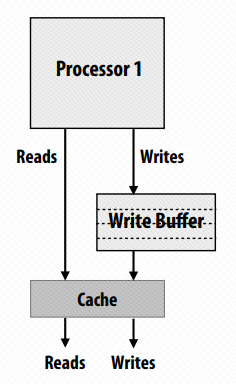
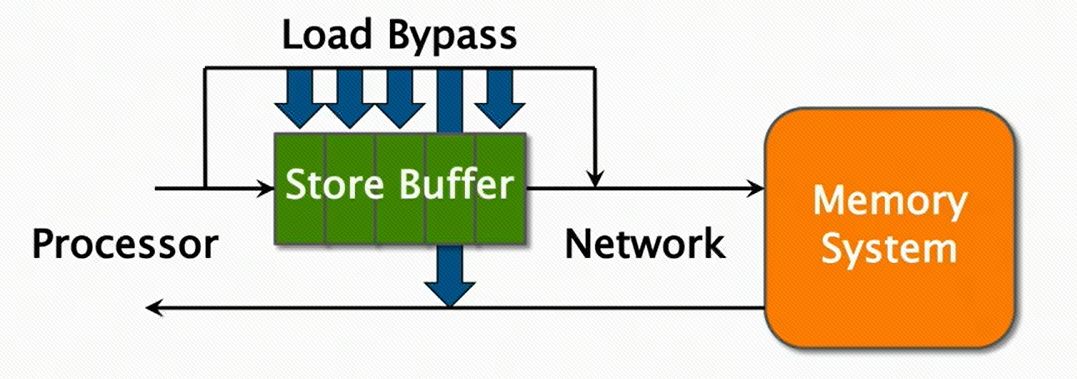
处理器 Write 命令将会发送到 Write Buffer,而 Read 命令就直接能访问 cache,这样可以省去写操作的延迟。Write Buffer 还有一个细节问题,放开 W -> R 的限制是当 Write 和 Read 操作内存地址不是同一个的时候,R/W 才能同时进行甚至 R 能提前到 W 之前,但如果 Write Buffer 中有一个 Read 所依赖的内存地址就存在问题,Read 需要等在 Write buffer 中的 Write 执行完成才能继续吗?只需要 Read 能直接访问这个 Write Buffer,如下(注:这里的Load通常和Read等意,Store和Write等意):
Release Consistency
在这种一致性下,所有的 memory operation ordering 都将不再维护,是最激进的一种内存一致模型,进入临界区叫做 Acquire ,离开临界区叫做 Release。所有的 memory operation ordering 都将不再维护,处理器支持特殊的同步操作,所有的内存访问指令必须在 fence 指令发送之前完成,在 fench 命令完成之前,其他所有的命令都不能开始执行。
Intel x86/x64 芯片在硬件层面提供了 total store ordering 的能力,如果软件要求更高级别的一致性模型,处理器提供了三种指令:
- mm_lfence:load fence,等待所有 load 完成
- mm_sfence:store fence,等待所有 store 完成
- mm_mfence:完全读写屏障
而在 ARM 架构上,提供的是一种非常松弛(very relaxed)内存一致模型。
PS. 曾经有个公司做出了支持 Sequential Consistency 的硬件,但是最终还是败给了市场。
Acquire/Release
Acquire/release 对应 std::memory_order_acquire 和 std::memory_order_acquire,它们的语义解释如下:
- Acquire:如果一个操作 X 带有 acquire 语义,那么在操作 X 后的所有
load/store指令都不会被重排序到操作 X 之前,其他处理器会在看到操作X后序操作的影响之前看到操作 X 的影响,也就是必须先看到 X 的影响,再是后续操作的影响。 - Relase:如果一个操作 X 带有 release 语义,那么在操作 X 之前的所有
load/store指令操作都不会被重排序到操作 X 之后,其他处理器会先看到操作 X 之前的操作。

Acquire/Release 常用在互斥锁(mutex lock)和自旋锁(spin lock),获得一个锁和释放一个锁需要分别使用 Acquire 和 Release 语义防止指令操作被重排出临界区,从而造成数据竞争。
Acquire/Consume
Acquire/Consume 对应 std::memory_order_acquire 和 std::memory_order_consume,两种内存模型的组合仅有 consume 不同于 release,不同点在于,假设原子操作 X, Release 会防止 X 之前的所有指令不会被重排到 X 之后,而 Consume 只能保证依赖的变量不会被重排到 X 之后,引入了依赖关系。
但是在 cppreference 上面写着,“释放消费顺序的规范正在修订中,而且暂时不鼓励使用memory_order_consume。”,所以暂时不对其做深入的研究。
Volatile
volatile 关键词通常会被拿出来说,因为通常会在并发编程中被错误使用:
volatile 的翻译是“不稳定的,易发生变化的”,编译器会始终读取 volatile 修饰的变量,不会将变量的值优化掉,但是这不是用在线程同步的工具,而是一种错误行为,cppreference上面写道:“volatile 访问不建立线程间同步,volatile 访问不是原子的,且不排序内存,非 volatile 内存访问可以自由地重排到 volatile 访问前后。”(Visual Studio 是个例外)。
volatile 变量的作用是用在非常规内存上的内存操作,常规内存在处理器不去操作的时候是不会发生变化的,但是像非常规内存如内存映射I/O的内存,实际上是在和外围设备做串口通信,所以不能省去。(《modern effective c++》)
加载全部内容