python多进程和多线程
小熊猫爱恰饭 人气:0一、什么是进程和线程
进程是分配资源的最小单位,线程是系统调度的最小单位。
当应用程序运行时最少会开启一个进程,此时计算机会为这个进程开辟独立的内存空间,不同的进程享有不同的空间,而一个CPU在同一时刻只能够运行一个进程,其他进程处于等待状态。
一个进程内部包括一个或者多个线程,这些线程共享此进程的内存空间与资源。相当于把一个任务又细分成若干个子任务,每个线程对应一个子任务。
二、多进程和多线程
对于一个CPU来说,在同一时刻只能运行一个进程或者一个线程,而单核CPU往往是在进程或者线程间切换执行,每个进程或者线程得到一定的CPU时间,由于切换的速度很快,在我们看来是多个任务在并行执行(同一时刻多个任务在执行),但实际上是在并发执行(一段时间内多个任务在执行)。
单核CPU的并发往往涉及到进程或者线程的切换,进程的切换比线程的切换消耗更多的时间与资源。在单核CPU下,CPU密集的任务采用多进程或多线程不会提升性能,而在IO密集的任务中可以提升(IO阻塞时CPU空闲)。
而多核CPU就可以做到同时执行多个进程或者多个进程,也就是并行运算。在拥有多个CPU的情况下,往往使用多进程或者多线程的模式执行多个任务。
三、python中的多进程和多线程
1、多进程
def Test(pid):
print("当前进程{}:{}".format(pid, os.getpid()))
for i in range(1000000000):
pass
if __name__ == '__main__':
#单进程
start = time.time()
for i in range(2):
Test(i)
end = time.time()
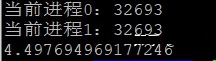
print((end - start))单进程输出结果如图:
def Test(pid):
print("当前子进程{}:{}".format(pid, os.getpid()))
for i in range(100000000):
pass
if __name__ == '__main__':
#多进程
print("父进程:{}".format(os.getpid()))
start = time.time()
pool = Pool(processes=2)
pid = [i for i in range(2)]
pool.map(Test, pid)
pool.close()
pool.join()
end = time.time()
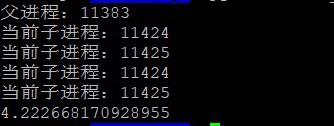
print((end - start))多进程输出结果如图:

从输出结果可以看出都是执行两次for循环,多进程比单进程减少了近乎一半的时间(这里使用了两个进程),并且查看CPU情况可以看出多进程利用了多个CPU。
python中的多进程可以利用mulitiprocess模块的Pool类创建,利用Pool的map方法来运行子进程。
一般多进程的执行如下代码:
def Test(pid):
print("当前子进程{}:{}".format(pid, os.getpid()))
for i in range(100000000):
pass
if __name__ == '__main__':
#多进程
print("父进程:{}".format(os.getpid()))
pool = Pool(processes=2)
pid = [i for i in range(4)]
pool.map(Test, pid)
pool.close()
pool.join()1、利用Pool类创建一个进程池,processes声明在进程池中最多可以运行几个子进程,不声明的情况下会自动根据CPU数量来设定,原则上进程池容量不超过CPU数量。(出于资源的考虑,不要创建过多的进程)
2、声明一个可迭代的变量,该变量的长度决定要执行多少次子进程。
3、利用map()方法执行多进程,map方法两个参数,第一个参数是多进程执行的方法名,第二个参数是第二步声明的可迭代变量,里面的每一个元素是方法所需的参数。 这里需要注意几个点:1)进程池满的时候请求会等待,以上述代码为例,声明了一个容量为2的进程池,但是可迭代变量有4个,那么在执行的时候会先创建两个子进程,此时进程池已满,等待有子进程执行完成,才继续处理请求;
2) 子进程处理完一个请求后,会利用已经创建好的子进程继续处理新的请求而不会重新创建进程。
从图3可以看出上述两个点,如果同时处理4个进程,那么只需要2秒钟,这里是分成两次处理,花费了4秒,并且两次处理使用的子进程号都相同。
3)map会将每个子进程的返回值汇总成一个列表返回。
4、在所有请求处理结束后使用close()方法关闭进程池不再接受请求。
5、使用join()方法让主进程阻塞,等待子进程退出,join()方法要放在close()方法之后,防止主进程在子进程结束之前退出。
2、多线程
python的多线程模块用threading类进行创建
import time
import threading
import os
count = 0
def change(n):
global count
count = count + n
count = count - n
def run(n):
print("当前子线程:{}".format(threading.current_thread().name))
for i in range(10000000):
change(n)
if __name__ == '__main__':
print("主线程:{}".format(threading.current_thread().name))
thread_1 = threading.Thread(target=run, args=(3,))
thread_2 = threading.Thread(target=run, args=(10,))
thread_1.start()
thread_2.start()
thread_1.join()
thread_2.join()
print(count)程序执行会创建一个进程,进程会默认启动一个主线程,使用threading.Thread()创建子线程;target为要执行的函数;args传入函数需要的参数;start()启动子线程,join()阻塞主线程先运行子线程。 由于变量由多个线程共享,任何一个线程都可以对于变量进行修改,如果同时多个线程修改变量就会出现错误。
上面的程序在理论上的结果应该为0,但运行结果如图:

出现这个结果的原因就是多个线程同时对于变量修改,在赋值时出现错误,具体解释见多线程
解决这个问题就是在修改变量的时候加锁,这样就可以避免出现多个线程同时修改变量。
import time
import threading
import os
count = 0
lock = threading.Lock()
def change(n):
global count
count = count + n
count = count - n
def run(n):
print("当前子线程:{}".format(threading.current_thread().name))
for i in range(10000000):
# lock.acquire()
# try:
change(n)
# finally:
# lock.release()
if __name__ == '__main__':
print("主线程:{}".format(threading.current_thread().name))
thread_1 = threading.Thread(target=run, args=(3,))
thread_2 = threading.Thread(target=run, args=(10,))
thread_1.start()
thread_2.start()
thread_1.join()
thread_2.join()
print(count)python中的线程需要先获取GIL(Global Interpreter Lock)锁才能继续运行,每一个进程仅有一个GIL,线程在获取到GIL之后执行100字节码或者遇到IO中断时才会释放GIL,这样在CPU密集的任务中,即使有多个CPU,多线程也是不能够利用多个CPU来提高速率,甚至可能会因为竞争GIL导致速率慢于单线程。所以对于CPU密集任务往往使用多进程,IO密集任务使用多线程。
加载全部内容