python标准库html
爱听音乐的boy 人气:0python之标准库html
html库是用于解析HTML的一个工具,是python自带的标准库之一。
html库位置:
__init__.py文件提供两个函数:
__all__ = ['escape', 'unescape']
介绍 escape 和 unescape:
escape(s, quote=True) #用来将特殊字符进行转义成实体字符 """ 参数介绍: s 指定要转义的特殊字符 quote 默认为True,表示要将 " 或者 ' 也要转义成实体字符,False反之不用转义成实体字符 """ unescape(s) #用来将实体字符进行还原到特殊字符
escape 和 unescape 的使用:
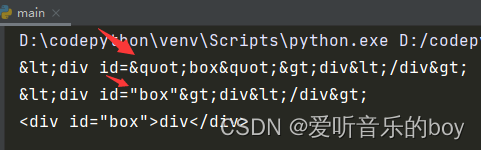
import html s = '<div id="box">div</div>' res = html.escape(s) print(res) print(html.escape(s,quote=False)) print(html.unescape(res)) #理解还原即可
输出结果:
escape源码的实现:

html库中的 entities 模块
该模块定义: HTML字符实体引用。
该模块提供四个字典对象:
__all__ = ['html5', 'name2codepoint', 'codepoint2name', 'entitydefs']
导入:
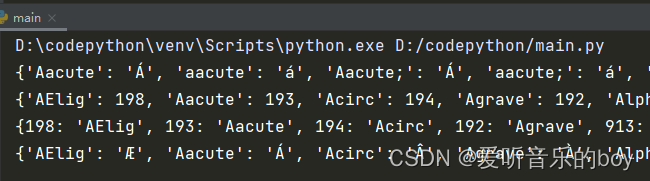
from html import entities html = entities.html5 name2codep = entities.name2codepoint codep = entities.codepoint2name ent = entities.entitydefs print(html) print(name2codep) print(codep) print(ent)
输出结果:
html库中的 parser 模块
该模块是HTML和XHTML的解析器。
该模块提供一个类:
__all__ = ['HTMLParser']
导入:
from html import parser htmlParser=parser.HTMLParser()
介绍该类的常用属性和常用方法:
常用属性:
lasttag #保存上一个解析的标签名,返回字符串。
已实现的常用方法:
feed(data) #将数据馈送到解析器。无返回值 unescape(s) #往上看,前面有介绍的 get_starttag_text() #返回开始标记的完整来源 close() #关闭
未实现的常用方法:
注意:这些方法在源码中都没有具体实现,需要我们定义一个子类继承自HTMLParser类,在子类中重写这些方法,实现自己逻辑
handle_starttag(tag, attrs) #处理开始标签,如 <div>;这里的attrs获取到的是属性列表,属性以元组的方式展示 handle_endtag(tag) #处理结束标签, 如 </div> handle_data(data) #处理数据,标签之间的文本 handle_comment(data) #处理注释,<!-- - -> 之间的文本 handle_startendtag(tag, attrs) #处理自己结束的标签,如 <img />
以上方法在源码中是这样的:



加载全部内容