tensorflow函数tensorboard
Bubbliiiing 人气:0tensorboard常用于更直观的观察数据在神经网络中的变化,或者用于观测已经构建完成的神经网络的结构。其有助于我们更加方便的去观测tensorflow神经网络的搭建情况以及执行情况。
tensorboard相关函数及其常用参数设置
tensorboard相关函数代码真的好多啊。难道都要背下来吗!
不需要!只要收藏了来这里复制粘贴就可以了。常用的只有七个!
1 with tf.name_scope(layer_name):
TensorFlow中的name_scope函数的作用是创建一个参数名称空间。这个空间里包括许多参数,每个参数有不同的名字,这样可以更好的管理参数空间,防止变量命名时产生冲突。
利用该函数可以生成相对应的神经网络结构图。
该函数支持嵌套。
在该标题中,该参数名称空间空间的名字为layer_name。
2 tf.summary.histogram(layer_name+"/biases",biases)
该函数用于将变量记录到tensorboard中。用来显示直方图信息。
一般用来显示训练过程中变量的分布情况。
在该标题中,biases的直方图信息被记录到tensorboard的layer_name+"/biases"中。
3 tf.summary.scalar(“loss”,loss)
用来进行标量信息的可视化与显示。
一般在画loss曲线和accuary曲线时会用到这个函数。
在该标题中,loss的标量信息被记录到tensorboard的"loss"中。
4 tf.summary.merge_all()
将之前定义的所有summary整合在一起。
tf.summary.scalar、tf.summary.histogram、tf.summary.image在定义的时候,也不会立即执行,需要通过sess.run来明确调用这些函数。因为,在一个程序中定义的写日志操作比较多,如果一一调用,将会十分麻烦,所以Tensorflow提供了tf.summary.merge_all()函数将所有的summary整理在一起。
在TensorFlow程序执行的时候,只需要运行这一个操作就可以将代码中定义的所有写summary内容执行一次,从而将所有的summary内容写入。
5 tf.summary.FileWriter(“logs/”,sess.graph)
将summary内容写入磁盘文件,FileWriter类提供了一种用于在给定目录下创建事件文件的机制,并且将summary数据写入硬盘。
在该标题中,summary数据被写入logs文件夹中。
6 write.add_summary(result,i)
该函数成立前提为:
write = tf.summary.FileWriter("logs/",sess.graph)add_summary是tf.summary.FileWriter父类中的成员函数;添加summary内容到事件文件,写入事件文件。
在该标题中,result是tf.summary.merge_all()执行的结果,i表示世代数。
7 tensorboard --logdir=logs
该函数用于cmd命令行中。用于生成tensorboard观测网页。
例子
该例子为手写体识别例子。
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot = "true")
def add_layer(inputs,in_size,out_size,n_layer,activation_function = None):
layer_name = 'layer%s'%n_layer
with tf.name_scope(layer_name):
with tf.name_scope("Weights"):
Weights = tf.Variable(tf.random_normal([in_size,out_size]),name = "Weights")
tf.summary.histogram(layer_name+"/weights",Weights)
with tf.name_scope("biases"):
biases = tf.Variable(tf.zeros([1,out_size]) + 0.1,name = "biases")
tf.summary.histogram(layer_name+"/biases",biases)
with tf.name_scope("Wx_plus_b"):
Wx_plus_b = tf.matmul(inputs,Weights) + biases
tf.summary.histogram(layer_name+"/Wx_plus_b",Wx_plus_b)
if activation_function == None :
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
tf.summary.histogram(layer_name+"/outputs",outputs)
return outputs
def compute_accuracy(x_data,y_data):
global prediction
y_pre = sess.run(prediction,feed_dict={xs:x_data})
correct_prediction = tf.equal(tf.arg_max(y_data,1),tf.arg_max(y_pre,1)) #判断是否相等
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) #赋予float32数据类型,求平均。
result = sess.run(accuracy,feed_dict = {xs:batch_xs,ys:batch_ys}) #执行
return result
xs = tf.placeholder(tf.float32,[None,784])
ys = tf.placeholder(tf.float32,[None,10])
layer1 = add_layer(xs,784,150,"layer1",activation_function = tf.nn.tanh)
prediction = add_layer(layer1,150,10,"layer2")
with tf.name_scope("loss"):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=ys,logits = prediction),name = 'loss')
#label是标签,logits是预测值,交叉熵。
tf.summary.scalar("loss",loss)
train = tf.train.GradientDescentOptimizer(0.5).minimize(loss)
init = tf.initialize_all_variables()
merged = tf.summary.merge_all()
with tf.Session() as sess:
sess.run(init)
write = tf.summary.FileWriter("logs/",sess.graph)
for i in range(5001):
batch_xs,batch_ys = mnist.train.next_batch(100)
sess.run(train,feed_dict = {xs:batch_xs,ys:batch_ys})
if i % 1000 == 0:
print("训练%d次的识别率为:%f。"%((i+1),compute_accuracy(mnist.test.images,mnist.test.labels)))
result = sess.run(merged,feed_dict={xs:batch_xs,ys:batch_ys})
write.add_summary(result,i)
该例子执行结果为:
结构图:

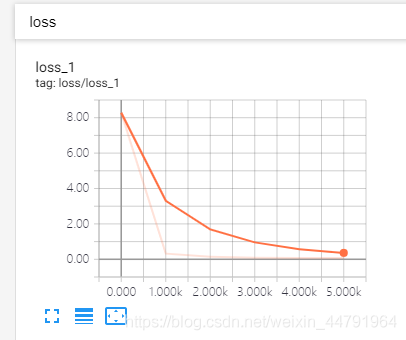
LOSS值:
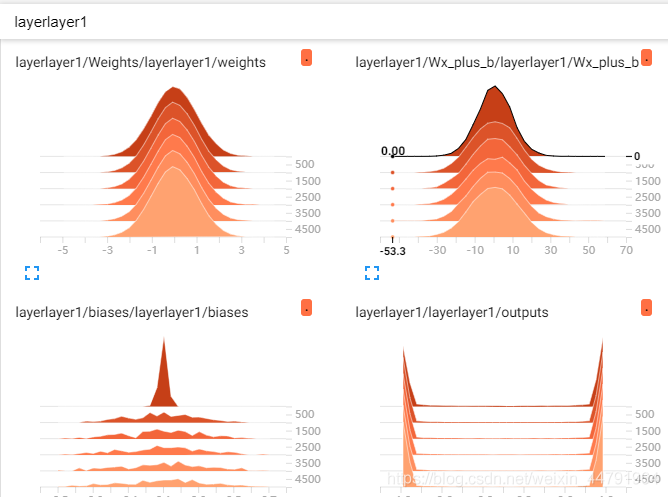
weights,biases的直方图分布:
加载全部内容