VGG16模型复现预测
Bubbliiiing 人气:1学一些比较知名的模型对身体有好处噢!
什么是VGG16模型
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
可能大家会想,这样一个这么强的模型肯定很复杂吧?
其实一点也不复杂,它的结构如下图所示:
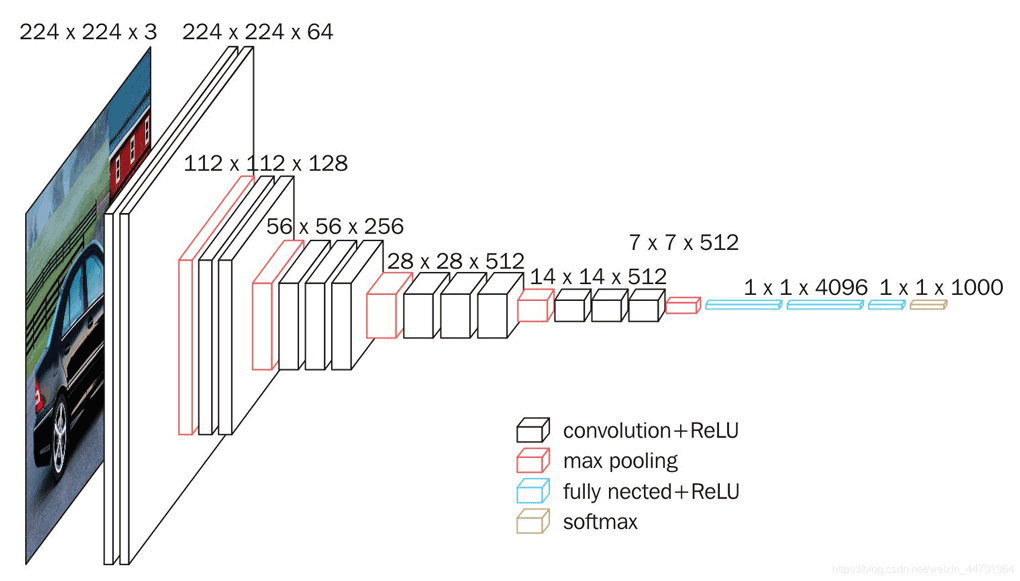
这是一个VGG被用到烂的图,但确实很好的反应了VGG的结构:
1、一张原始图片被resize到(224,224,3)。
2、conv1两次[3,3]卷积网络,输出的特征层为64,输出为(224,224,64),再2X2最大池化,输出net为(112,112,64)。
3、conv2两次[3,3]卷积网络,输出的特征层为128,输出net为(112,112,128),再2X2最大池化,输出net为(56,56,128)。
4、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(56,56,256),再2X2最大池化,输出net为(28,28,256)。
5、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(28,28,512),再2X2最大池化,输出net为(14,14,512)。
6、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(14,14,512),再2X2最大池化,输出net为(7,7,512)。
7、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,4096)。共进行两次。
8、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,1000)。
最后输出的就是每个类的预测。
VGG网络部分实现代码
#-------------------------------------------------------------#
# vgg16的网络部分
#-------------------------------------------------------------#
import tensorflow as tf
# 创建slim对象
slim = tf.contrib.slim
def vgg_16(inputs,
num_classes=1000,
is_training=True,
dropout_keep_prob=0.5,
spatial_squeeze=True,
scope='vgg_16'):
with tf.variable_scope(scope, 'vgg_16', [inputs]):
# 建立vgg_16的网络
# conv1两次[3,3]卷积网络,输出的特征层为64,输出为(224,224,64)
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
# 2X2最大池化,输出net为(112,112,64)
net = slim.max_pool2d(net, [2, 2], scope='pool1')
# conv2两次[3,3]卷积网络,输出的特征层为128,输出net为(112,112,128)
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
# 2X2最大池化,输出net为(56,56,128)
net = slim.max_pool2d(net, [2, 2], scope='pool2')
# conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(56,56,256)
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
# 2X2最大池化,输出net为(28,28,256)
net = slim.max_pool2d(net, [2, 2], scope='pool3')
# conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(28,28,512)
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4')
# 2X2最大池化,输出net为(14,14,512)
net = slim.max_pool2d(net, [2, 2], scope='pool4')
# conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(14,14,512)
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5')
# 2X2最大池化,输出net为(7,7,512)
net = slim.max_pool2d(net, [2, 2], scope='pool5')
# 利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,4096)
net = slim.conv2d(net, 4096, [7, 7], padding='VALID', scope='fc6')
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout6')
# 利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,4096)
net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout7')
# 利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,1000)
net = slim.conv2d(net, num_classes, [1, 1],
activation_fn=None,
normalizer_fn=None,
scope='fc8')
# 由于用卷积的方式模拟全连接层,所以输出需要平铺
if spatial_squeeze:
net = tf.squeeze(net, [1, 2], name='fc8/squeezed')
return net
图片预测
在图片预测之前首先看看整个文档的结构。需要完整代码可以直接下载
VGG16的模型下载可以用
链接: http://pan.baidu.com/s/18IT3ILvnD0uUJDx9-ums2A
提取码: jr6u 完成
model用于存储模型,nets用于存储网络结构,test_data用于存放图片,demo就是之后要执行的测试程序。
图片预测的步骤其实就是利用训练好的模型进行预测。
1、载入图片
2、建立会话Session;
3、将img_input的placeholder传入网络,建立网络结构;
4、初始化所有变量;
5、利用saver对象restore载入所有参数。
6、读取预测结果
demo.py的代码如下:
from nets import vgg16
import tensorflow as tf
import numpy as np
import utils
# 读取图片
img1 = utils.load_image("./test_data/dog.jpg")
# 对输入的图片进行resize,使其shape满足(-1,224,224,3)
inputs = tf.placeholder(tf.float32,[None,None,3])
resized_img = utils.resize_image(inputs, (224, 224))
# 建立网络结构
prediction = vgg16.vgg_16(resized_img)
# 载入模型
sess = tf.Session()
ckpt_filename = './model/vgg_16.ckpt'
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess, ckpt_filename)
# 最后结果进行softmax预测
pro = tf.nn.softmax(prediction)
pre = sess.run(pro,feed_dict={inputs:img1})
# 打印预测结果
utils.print_prob(pre[0], './synset.txt')
utils里是一些工具代码(工具人),包括载入图片、图片大小更改、打印预测结果等:
import matplotlib.image as mpimg
import numpy as np
import tensorflow as tf
from tensorflow.python.ops import array_ops
def load_image(path):
# 读取图片,rgb
img = mpimg.imread(path)
# 将图片修剪成中心的正方形
short_edge = min(img.shape[:2])
yy = int((img.shape[0] - short_edge) / 2)
xx = int((img.shape[1] - short_edge) / 2)
crop_img = img[yy: yy + short_edge, xx: xx + short_edge]
return crop_img
def resize_image(image, size,
method=tf.image.ResizeMethod.BILINEAR,
align_corners=False):
with tf.name_scope('resize_image'):
image = tf.expand_dims(image, 0)
image = tf.image.resize_images(image, size,
method, align_corners)
image = tf.reshape(image, tf.stack([-1,size[0], size[1], 3]))
return image
def print_prob(prob, file_path):
synset = [l.strip() for l in open(file_path).readlines()]
# 将概率从大到小排列的结果的序号存入pred
pred = np.argsort(prob)[::-1]
# 取最大的1个、5个。
top1 = synset[pred[0]]
print(("Top1: ", top1, prob[pred[0]]))
top5 = [(synset[pred[i]], prob[pred[i]]) for i in range(5)]
print(("Top5: ", top5))
return top1
该图的预测结果为:

('Top1: ', 'n02099601 golden retriever', 0.98766345)
('Top5: ', [('n02099601 golden retriever', 0.98766345), ('n02099712 Labrador retriever', 0.0108569125), ('n02101556 clumber, clumber spaniel', 0.00039345716), ('n02102480 Sussex spaniel', 0.0002893341), ('n02102318 cocker spaniel, English cocker spaniel, cocker', 0.00018955152)])
加载全部内容