卷积神经网络改进结构块
Bubbliiiing 人气:0学习前言
看了好多代码呀,看了后面忘了前面,这个BLOG主要是记录一些神经网络的改进结构,比如残差结构那种,记录下来有助于自己设计一些轻且好的网络。
1、残差网络
这个网络主要源自于Resnet网络,其作用是:
将靠前若干层的某一层数据输出直接跳过多层引入到后面数据层的输入部分。
意味着后面的特征层的内容会有一部分由其前面的某一层线性贡献。
实验表明,残差网络更容易优化,并且能够通过增加相当的深度来提高准确率。
最终可以使得网络越来越深,Resnet152就是一个很深很深的网络。
残差网络的典型结构如下:

2、不同大小卷积核并行卷积
这个结构主要是在Inception网络结构中出现。
Inception网络采用不同大小的卷积核,使得存在不同大小的感受野,最后实现拼接达到不同尺度特征的融合。
不同大小卷积核并行卷积的典型结构如下:

3、利用(1,x),(x,1)卷积代替(x,x)卷积
这种结构主要利用在InceptionV3中。
利用1x7的卷积和7x1的卷积代替7x7的卷积,这样可以只使用约(1x7 + 7x1) / (7x7) = 28.6%的计算开销;
利用1x3的卷积和3x1的卷积代替3x3的卷积,这样可以只使用约(1x3 + 3x1) / (3x3) = 67%的计算开销。
下图利用1x7的卷积和7x1的卷积代替7x7的卷积。

下图利用1x3的卷积和3x1的卷积代替3x3的卷积。

4、采用瓶颈(Bottleneck)结构
这个结构在Resnet里非常常见,其它网络也有用到。
所谓Bottleneck结构就是首先利用1x1卷积层进行特征压缩,再利用3x3卷积网络进行特征提取,再利用1x1卷积层进行特征扩张。
该结构相比于直接对输入进行3x3卷积减少了许多参数量。
当输入为26,26,512时,直接使用3x3、filter为512的卷积网络的参数量为512x3x3x512=2,359,296。
采用Bottleneck结构的话,假设其首先利用1x1、filter为128卷积层进行特征压缩,再利用3x3、filter为128的卷积网络进行特征提取,再利用1x1、filter为512的卷积层进行特征扩张,则参数量为 512×1×1×128 + 128×3×3×128 + 128×1×1×512 = 278,528。
可以看出来确实时下降了很多呀。
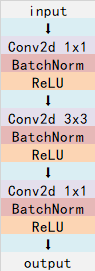
5、深度可分离卷积
深度可分离卷积主要在MobileNet模型上应用。
其特点是3x3的卷积核厚度只有一层,然后在输入张量上一层一层地滑动,每一次卷积完生成一个输出通道,当卷积完成后,在利用1x1的卷积调整厚度。

假设有一个3×3大小的卷积层,其输入通道为16、输出通道为32。具体为,32个3×3大小的卷积核会遍历16个通道中的每个数据,最后可得到所需的32个输出通道,所需参数为16×32×3×3=4608个。
应用深度可分离卷积,用16个3×3大小的卷积核分别遍历16通道的数据,得到了16个特征图谱。在融合操作之前,接着用32个1×1大小的卷积核遍历这16个特征图谱,所需参数为16×3×3+16×32×1×1=656个。
6、改进版深度可分离卷积+残差网络
这种结构主要存在在Xception网络中。
改进版深度可分离卷积就是调换了一下深度可分离的顺序,先进行1x1卷积调整通道,再利用3x3卷积提取特征。
和普通的深度可分离卷积相比,参数量也会有一定的变化。

改进版深度可分离卷积加上残差网络的结构其实和它的名字是一样的,很好理解。
如下图所示:

7、倒转残差(Inverted residuals)结构
在ResNet50里我们认识到一个结构,bottleneck design结构,在3x3网络结构前利用1x1卷积降维,在3x3网络结构后,利用1x1卷积升维,相比直接使用3x3网络卷积效果更好,参数更少,先进行压缩,再进行扩张。
而Inverted residuals结构,在3x3网络结构前利用1x1卷积升维,在3x3网络结构后,利用1x1卷积降维,先进行扩张,再进行压缩。
这种结构主要用在MobilenetV2中。
其主要结构如下:

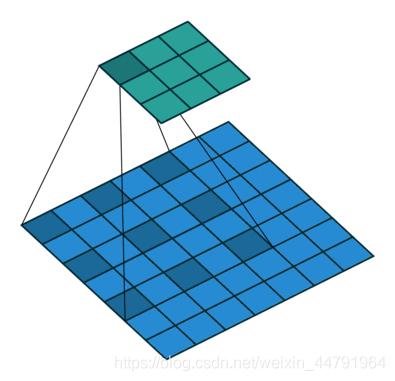
8、并行空洞卷积
这个结构出现在Deeplabv3语义分割中。

其经过并行的空洞卷积,分别用不同rate的空洞卷积进行特征提取,再进行合并,再进行1x1卷积压缩特征。
空洞卷积可以在不损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息**。如下就是空洞卷积的一个示意图,所谓空洞就是特征点提取的时候会跨像素。
加载全部内容