Keras实现LSTM参数量
Bubbliiiing 人气:0什么是LSTM
1、LSTM的结构
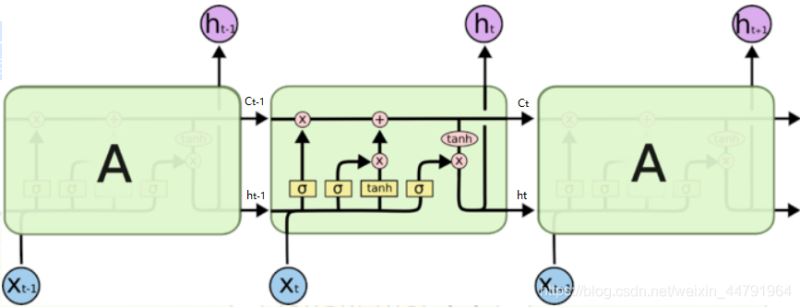
我们可以看出,在n时刻,LSTM的输入有三个:
- 当前时刻网络的输入值Xt;
- 上一时刻LSTM的输出值ht-1;
- 上一时刻的单元状态Ct-1。
LSTM的输出有两个:
- 当前时刻LSTM输出值ht;
- 当前时刻的单元状态Ct。
2、LSTM独特的门结构
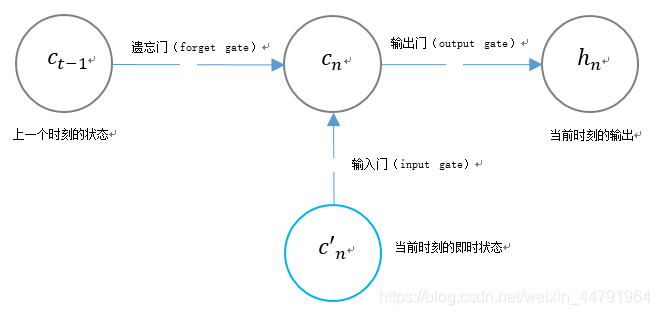
LSTM用两个门来控制单元状态cn的内容:
- 遗忘门(forget gate),它决定了上一时刻的单元状态cn-1有多少保留到当前时刻;
- 输入门(input gate),它决定了当前时刻网络的输入c’n有多少保存到新的单元状态cn中。
LSTM用一个门来控制当前输出值hn的内容:
输出门(output gate),它利用当前时刻单元状态cn对hn的输出进行控制。
3、LSTM参数量计算
a、遗忘门
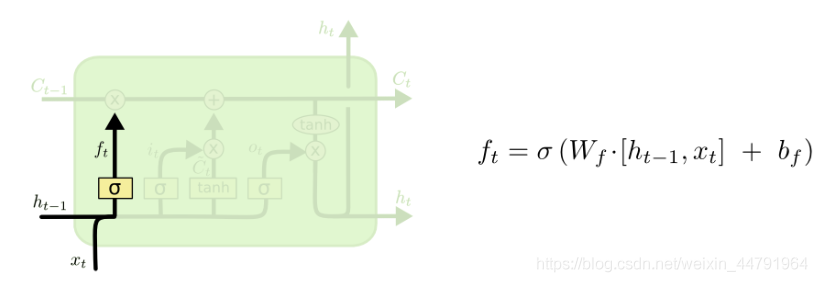
遗忘门这里需要结合ht-1和Xt来决定上一时刻的单元状态cn-1有多少保留到当前时刻;
由图我们可以得到,我们在这一环节需要计一个参数ft。
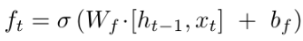

b、输入门
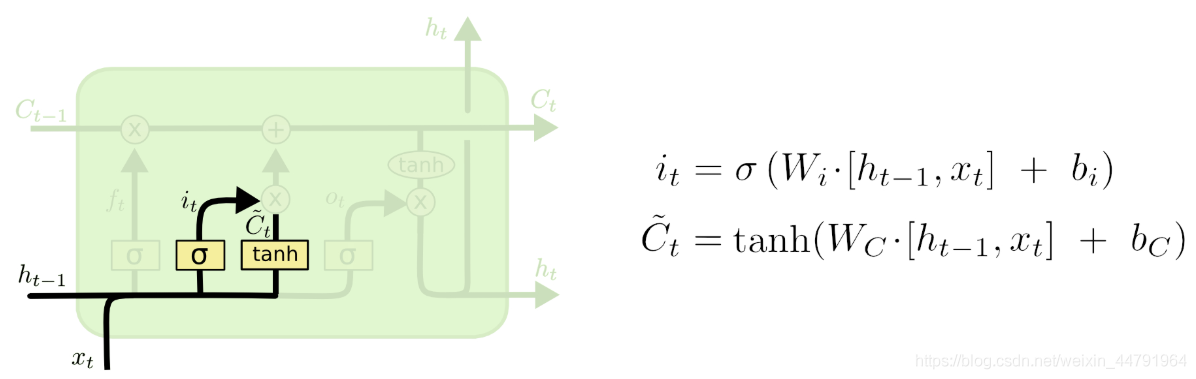
输入门这里需要结合ht-1和Xt来决定当前时刻网络的输入c’n有多少保存到单元状态cn中。
由图我们可以得到,我们在这一环节需要计算两个参数,分别是it。

和C’t
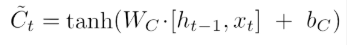
里面需要训练的参数分别是Wi、bi、WC和bC。
在定义LSTM的时候我们会使用到一个参数叫做units,其实就是神经元的个数,也就是LSTM的输出——ht的维度。
所以:

c、输出门
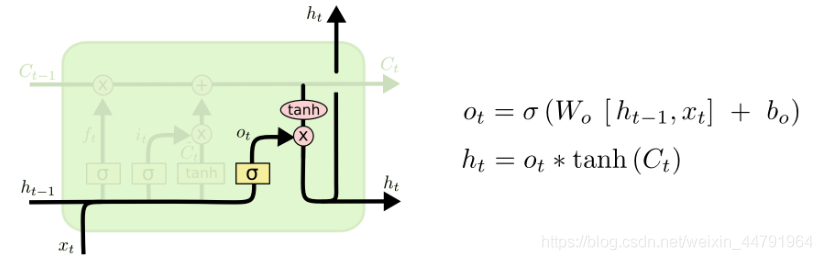
输出门利用当前时刻单元状态cn对hn的输出进行控制;
由图我们可以得到,我们在这一环节需要计一个参数ot。
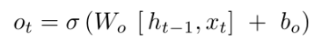
里面需要训练的参数分别是Wo和bo。在定义LSTM的时候我们会使用到一个参数叫做units,其实就是神经元的个数,也就是LSTM的输出——ht的维度。所以:

d、全部参数量
所以所有的门总参数量为:
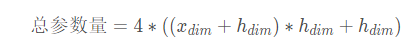
在Keras中实现LSTM
LSTM一般需要输入两个参数。
一个是unit、一个是input_shape。
LSTM(CELL_SIZE, input_shape = (TIME_STEPS,INPUT_SIZE))
unit用于指定神经元的数量。
input_shape用于指定输入的shape,分别指定TIME_STEPS和INPUT_SIZE。
实现代码
import numpy as np
from keras.models import Sequential
from keras.layers import Input,Activation,Dense
from keras.models import Model
from keras.datasets import mnist
from keras.layers.recurrent import LSTM
from keras.utils import np_utils
from keras.optimizers import Adam
TIME_STEPS = 28
INPUT_SIZE = 28
BATCH_SIZE = 50
index_start = 0
OUTPUT_SIZE = 10
CELL_SIZE = 75
LR = 1e-3
(X_train,Y_train),(X_test,Y_test) = mnist.load_data()
X_train = X_train.reshape(-1,28,28)/255
X_test = X_test.reshape(-1,28,28)/255
Y_train = np_utils.to_categorical(Y_train,num_classes= 10)
Y_test = np_utils.to_categorical(Y_test,num_classes= 10)
inputs = Input(shape=[TIME_STEPS,INPUT_SIZE])
x = LSTM(CELL_SIZE, input_shape = (TIME_STEPS,INPUT_SIZE))(inputs)
x = Dense(OUTPUT_SIZE)(x)
x = Activation("softmax")(x)
model = Model(inputs,x)
adam = Adam(LR)
model.summary()
model.compile(loss = 'categorical_crossentropy',optimizer = adam,metrics = ['accuracy'])
for i in range(50000):
X_batch = X_train[index_start:index_start + BATCH_SIZE,:,:]
Y_batch = Y_train[index_start:index_start + BATCH_SIZE,:]
index_start += BATCH_SIZE
cost = model.train_on_batch(X_batch,Y_batch)
if index_start >= X_train.shape[0]:
index_start = 0
if i%100 == 0:
cost,accuracy = model.evaluate(X_test,Y_test,batch_size=50)
print("accuracy:",accuracy)
实现效果:
10000/10000 [==============================] - 3s 340us/step accuracy: 0.14040000014007092 10000/10000 [==============================] - 3s 310us/step accuracy: 0.6507000041007995 10000/10000 [==============================] - 3s 320us/step accuracy: 0.7740999992191792 10000/10000 [==============================] - 3s 305us/step accuracy: 0.8516999959945679 10000/10000 [==============================] - 3s 322us/step accuracy: 0.8669999945163727 10000/10000 [==============================] - 3s 324us/step accuracy: 0.889699995815754 10000/10000 [==============================] - 3s 307us/step
加载全部内容