C#列表List<T>、HashSet和只读集合
springsnow 人气:0一、概述
List<T> 是ArrayList类的等效泛型类。属System.Collections.Generic命名空间。
二、声明及初始化
1、List<T> mList=new List<T>([capacity]) :可带初始容量
List<string> mList=new List<string>();
2、List<T> mList=new List<T><IEnumerable<T> collection): 从指定集合(如数组)复制元素进行初始化。
List<string> mList0 = new List<string>(new []{ "a", "b", "c" } );//数组
List<string> mList1 = new List<string>("a,b,c".Split(new char[] {','}) );//将字符串转成List<string>
List<string> mList2 = new List<string> { "a", "b", "c" };//集合初始值设定项三、常用属性和方法
1、添加元素
1、添加一个元素:
mList.Add("a");2、添加一组元素
mList.AddRange(new [] { new Person("a", 20), new Person("b", 10), }3、在Index处插入一个元素
mList.Insert(0,"d");//以前占此及此位以后的元素都往后移动
4、在Index处插入一组元素:
mList.InsertRange(0,new []{"E","f"});2、删除元素
1、删除一个值:
mList.Remove("a");2、删除索引处的元素:
mList.RemoveAt(0);
for (int i = mList.Count - 1; i >= 0; i--)
{ }3、删除范围内的元素:
mList.RemoveRange(3, 2);//index,count
4、清空所有元素:
mList.Clear();
5、删除与指定条件匹配的所有元素:
mList.RemoveAll(p => p.Length > 1);//bool Predicate<T>(T matach) 委托
注意:Remove()、Contais()、IndexOf、LastIndexOf()方法需要使用“相等”比较器。
List<T>中的元素实现了IEquatable接口则使用其Equals()方法,否则默认使用Object.Equals(object)。
3、访问列表元素以及遍历列表:
1、用索引的形式访问
mList[0]
2、遍历
foreach (string s in mList)
{
Console.WriteLine(s);
}
for (int i = 0; i < mList.Count; i++)
{
Console.WriteLine(s);
}注意:Count属性:实际包含的元素数;
Capacity:能够容纳的元素总数;
TrimExcess()方法可将容量调整为实际容量。
4、判断元素存在:
1、判断整个元素是否存在该List中:
if (mList.Contains("d"))
{ }2、判断是否存在于指定条件匹配的元素:
if (mList.Exists(p => p.Length > 2))
{ }3、判读是否List中每个元素都与指定条件匹配:
if (mList.TrueForAll(p => p.Length > 2))
{}5、搜索:
查找索引
1、查找列表中某个项的第一个索引:
mList.IndexOf(T,[index],[count]);
2、查找某元素在列表中最后一个匹配 项的索引:
mList.LastIndexOf(T,[index],[count]);
3、查找与指定条件匹配的元素在列表中第一个匹配项的索引:
mList.FindIndex([startIndex],[count],match);
4、查找与指定条件匹配的元素在列表中最后一个匹配项的索引:
mList.FindLastIndex(2, 10, p => p.Length > 2);
查找元素:
1、查找与指定条件匹配的元素,返回第一个匹配元素:
string find= mList.Find( p => p.Length > 2);
2、查找与指定条件匹配的元素,返回最后一个匹配元素:
string find= mList.FindLast( p => p.Length > 2);
3、查找并返回与指定条件匹配的元素列表:
List<string> finds= mList.FindAll( p => p.Length > 2);
6、排序:
委托签名:
int Comparison<T>(T x, T y);
1、使用Comparision<T>委托进行元素排序:
mList.Sort((x, y) =>
{
int result = x[0].CompareTo(y[0]);
if (result == 0) { return x[1].CompareTo(y[1]); }
return result;
});2、顺序翻转
mList.Reverse()//index,count
注意:Sort方法还可以利用ICompable和Icomparer接口排序。
7、转换:
1、将一定范围内的元素从List<T>复制到兼容的一维数组中。
mList.CopyTo([index],array,[arrryIndex],[count]);
2、将List<T>中的元素复制到新数组中。
string[] arr=mList.ToArray();
3、创建源List<T>的元素范围的浅表副本。
List(string) range= mList.GetRange(inex,count);
4、将当前List<T>的元素转换成另一种类型,返回转换后元素的列表
List<char> chars=mList.ConvertAll(p=>p[0]);
List<Racer> RacerList=PList.ConvertAll<Person,Racer>(p=>new Racer(p.FirstName+" " +p.LastName));
Converter委托签名:
TOutput Converter<in TInput,out TOutput>(TInput input);
5、将List<string>转成用逗号分隔的字符串
string aa= String.Join(",",mList)8、去掉重复项(Distinct)
需要引用using System.Linq;
1、默认比较器:
mList.Distinct().ToList();
2、自定义比较器
mList.Distinct(new MyComparer()).ToList();
public class MyComparer : System.Collections.Generic.IEqualityComparer<string>
{
public bool Equals(string x, string y)
{
return x.ToUpper()==y.ToUpper();
}
public int GetHashCode(string obj)
{
return obj.ToUpper().GetHashCode();
}
}9、只读集合
List的AsReadOnly()方法返回ReadOnlyCollection,所有修改方法抛出NotSupportedException异常。
System.Collections.ObjectModel.ReadOnlyCollection readOnlyList= mList.AsReadOnly();
四:HashSet<T>
用来存储集合,基于Hash,可理解为没有Value,只有Key的Dictionary<TKey,TValue);
- HashSet<T>不能使用索引访问,不能存储重复数据,元素T必须实现了Equals和GetHashCode方法;
- HashSet<T>的检索性能比List<T>好得多。如Contains(),Remove();
- HashSet<T>是专门用来和集合运算(取并集、交集等),所以提供了UnionWith(),InterSetWith()等方法。
1、常用方法
Add、IsSubsetOf、IsSupersetOf、Overlaps、UnionWith
var companyTeams = new HashSet<string> { "Ferrari", "McLaren", "Mercedes" };//公司队
var traditionalTeams = new HashSet<string> { "Ferrari", "McLaren" };//传统队
var privateTeams = new HashSet<string> { "Red Bull", "Toro Rosso", "Force India", "Sauber" };//私有队
//Add方法,将一个元素添加到集中,成功返回true失败返回false
if (privateTeams.Add("Williams"))//返回true
Console.WriteLine("Williams Add Success.privateTeams count:{0}", privateTeams.Count);
if (!companyTeams.Add("McLaren"))//返回false
Console.WriteLine("McLaren Add Failure.companyTeams count:{0}", companyTeams.Count);
//IsSubset,确认(traditionalTeams)对象是否为指定集(companyTeams)的子集
if (traditionalTeams.IsSubsetOf(companyTeams))//traditionalTeams是companyTeams的子集,返回true
Console.WriteLine("traditionalTeams is sub of companyTeams.");
//IsSuperset,确认(companyTeams)对象是否为指定集(traditionalTeams)的超集(父集)
if (companyTeams.IsSupersetOf(traditionalTeams))//companyTeams是traditionalTeams的父集,返回true
Console.WriteLine("companyTeams is a superset of traditionalTeams");
//Overlaps,确认对象(privateTeams)和指定集(traditionalTeams)是否存在共同元素
traditionalTeams.Add("Williams");
if (privateTeams.Overlaps(traditionalTeams))//privateTeams和traditionalTeams都包含有Williams的元素,返回true
Console.WriteLine("At least one team is the same with the traditionalTeams and privateTeams.");
//UnionWith,将指定对象元素添加到当前对象(allTeams)中,因为对象类型为SortedSet,所以是元素是唯一有序的
var allTeams = new SortedSet<string>();
allTeams.UnionWith(companyTeams);
allTeams.UnionWith(traditionalTeams);
allTeams.UnionWith(privateTeams);
foreach (var item in allTeams)
{
Console.Write(item);
}2、HashSet和SortedSet的区别
共同点:
1. 都是集,都具有集的特征,包含的元素不能有重复
不同点:
1. HashSet的元素是无序的,SortedSet的元素是有序的
五、链表 LinkedList
链表是一串存储数据的链式数据结构,它的每个成员都有额外的两个空间来关联它的上一个成员和下一个成员。
所以,链表对于插入和删除操作效率会高于ArrayList,因为它存储了上一个成员和下一个成员的指针,进行插入和删除只需要改变当前LinkedListNode的Previous和Next的指向即可。
1、链表的内存表视图
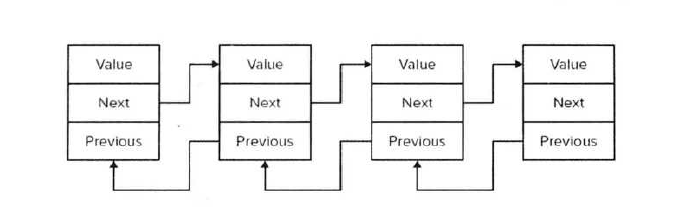
2、实例:
static void Main(string[] args)
{
LinkedList<Document> linkedlist = new LinkedList<Document>();
//添加节点
linkedlist.AddFirst(new Document("1"));
linkedlist.AddFirst(new Document("2"));
Display(linkedlist); //title:2 title:1
Document doc = new Document("3");
linkedlist.AddLast(doc);
Document doc1 = new Document("4");
linkedlist.AddLast(doc1);
Display(linkedlist); //title:2 title:1 title:3 title:4
//查找节点
LinkedListNode<Document> findnode = linkedlist.FindLast(doc);
Display(findnode.Value); //title:3
//插入节点
linkedlist.AddBefore(findnode, new Document("5"));
Display(linkedlist); //title:2 title:1 title:5 title:3 title:4
linkedlist.AddAfter(findnode, new Document("6"));
Display(linkedlist); //title:2 title:1 title:5 title:3 title:6 title:4
linkedlist.AddAfter(findnode.Previous, new Document("7"));
Display(linkedlist); //title:2 title:1 title:5 title:7 title:3 title:6 title:4
linkedlist.AddAfter(findnode.Next, new Document("8"));
Display(linkedlist); //title:2 title:1 title:5 title:7 title:3 title:6 title:8 title:4
//移除节点
linkedlist.Remove(findnode);
Display(linkedlist); //title:2 title:1 title:5 title:7 title:6 title:8 title:4
linkedlist.Remove(doc1);
Display(linkedlist); //title:2 title:1 title:5 title:7 title:6 title:8
linkedlist.RemoveFirst();
Display(linkedlist); //title:1 title:5 title:7 title:6 title:8
linkedlist.RemoveLast();
Display(linkedlist); //title:1 title:5 title:7 title:6
}
private static void Display<T>(LinkedList<T> linkedlist)
{
foreach (var item in linkedlist)
{
Console.Write(item + " ");
}
}
private static void Display<T>(T doc)
{
Console.Write(doc);
}
public class Document
{
public string title { get; private set; }
public Document(string title)
{
this.title = title;
}
public override string ToString()
{
return string.Format("title:{0}", title);
}
}到此这篇关于C#列表List<T>、HashSet和只读集合介绍的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持。
加载全部内容