FedAvg模型聚合
Cyril_KI 人气:0问题
联邦学习原始论文中给出的FedAvg的算法框架为:

参数介绍: K 表示客户端的个数, B表示每一次本地更新时的数据量, E 表示本地更新的次数, η表示学习率。
首先是服务器执行以下步骤:

对每一个本地客户端来说,要做的就是更新本地参数,具体来讲:
- 把自己的数据集按照参数B分成若干个块,每一块大小都为B。
- 对每一块数据,需要进行E轮更新:算出该块数据损失的梯度,然后进行梯度下降更新,得到新的本地 w 。
- 更新完后 w w w将被传送到中央服务器,服务器整合所有客户端计算出的 w,得到最新的全局模型参数 wt+1
- 客户端收到服务器发送的最新全局参数模型参数,进行下一次更新。
我们仔细观察server的最后一步:
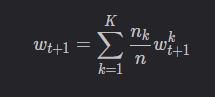

聚合
那么针对聚合,就有以下两种情况。
1. 聚合所有客户端
服务器端每次将新的全局模型发送给全部客户端,并且聚合全部客户端的模型参数。如果客户端未被选中,那么一轮通信结束后,该客户端的模型为一轮通信开始时从服务器获得的初始模型。
设当前全局模型为 wt,服务器选中了 m个客户端(集合V),m个客户端本地更新完毕后,服务器端的聚合公式为:
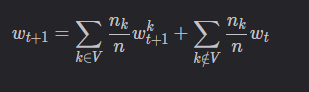
也就是说,每一次聚合时服务器端都将所有客户端的模型考虑在内。
2. 仅聚合被选中的客户端
服务器每次只是将当前新的参数传递给被选中的模型,并且只是聚合被选中客户端的模型参数。
设当前全局模型为 wt,服务器选中了 m 个客户端(集合V),然后将wt只发送给这 m个客户端。 m m m个客户端训练完毕后,服务器端的聚合公式为:
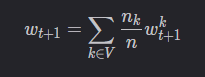
3. 选择
虽然原始论文中对所有K个客户端都进行了聚合,但在真正实现时,感觉用第二种会更好一点,因为如果客户端数量很庞大,每一次通信都会有不小的代价,用第二种会明显降低通信成本。
加载全部内容