DateFrame数据排序和排名
柳小葱 人气:01.数据排序
DataFrame.sort_values(by,axis=0,ascending=True,inplace=False,kind="quicksort",na_position="last",ignore_index=False) """ by:要排序的名称列表 axis:轴,0表示行,1表示列 ascending:升序或者降序排列,默认是True,升序 inplace:是否直接在数据上修改,True为直接修改df,False为副本 kind:指定排序算法, na_position:空值(NaN)的位置,值为first空值在数据开头,值为last空值在数据最后。 ignore_index:布尔值,是否忽略索引,值为True标记索引(从0开始顺序的整数值),False则忽略索引 """
2.按某列降序排序
import pandas as pd
exelFile="C:\\Users\\Administrator\\Desktop\\python数据分析Code\\Code\\03\\46\\mrbook.xlsx"
df=pd.DataFrame(pd.read_excel(exelFile))
pd.set_option('display.max_rows',1000)#设置展示最高行数
pd.set_option('display.max_columns',1000)#设置展示最高列数
pd.set_option('display.unicode.east_asian_width',True)
pd.set_option("display.unicode.ambiguous_as_wide",True)
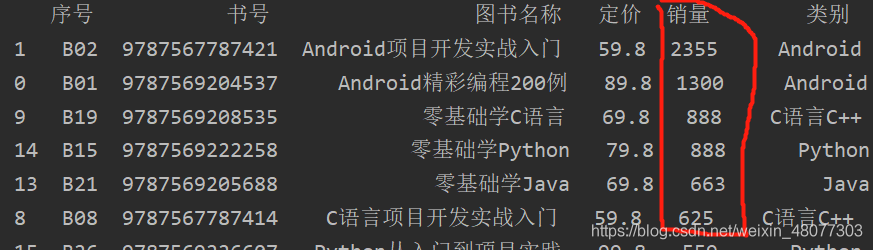
#按“销量”列降序排序
df1=df.sort_values(by="销量",ascending=False)
print(df1)
结果如图所示:
3.按多列升降序排列
#先按照图书名称降序排列,再按照销量降序排列 df2=df.sort_values(by=["图书名称","销量"])
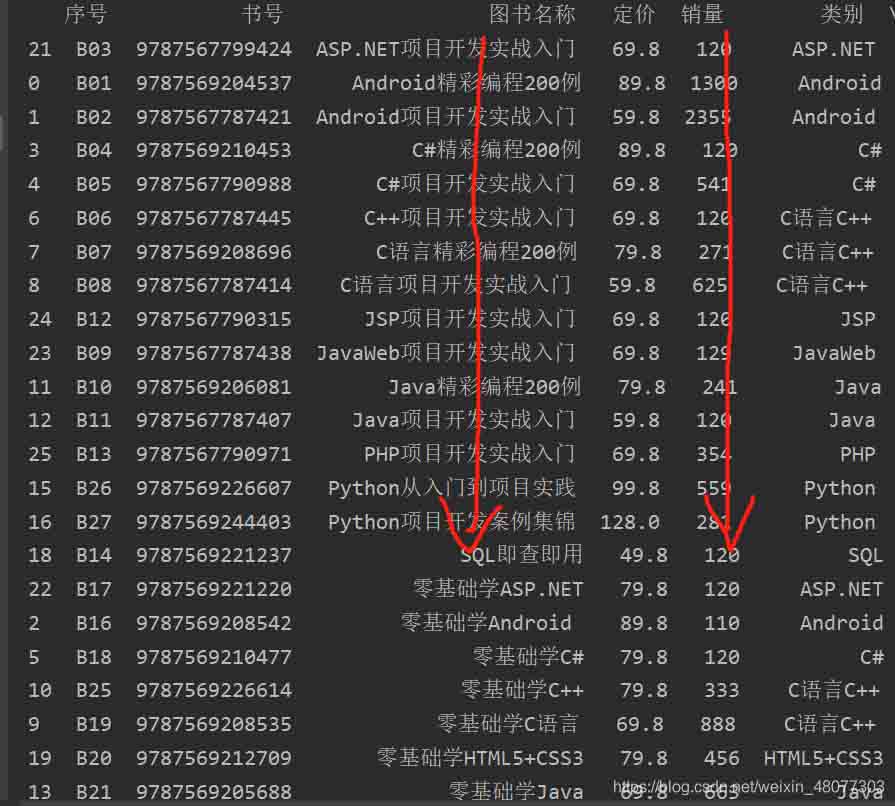
4.对统计结构排序
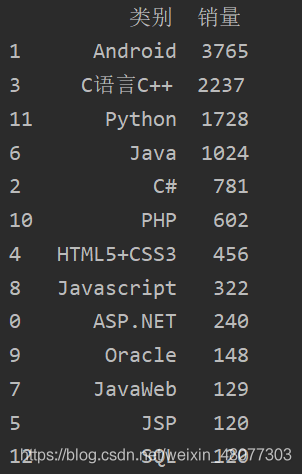
将类别分组并统计总销量降序排列。
df3=df.groupby(["类别"])["销量"].sum().reset_index() df4=df3.sort_values(by="销量",ascending=False) print(df4)
结构如下:
5.数据排名
DataFrame.rank(axis-0,method="average",numeric_only=None,na_option="keep",ascending=True,,pct=False) """ axis:轴,0表示行,1表示列 method:表示在相同值的情况下所使用的排序方法,参数如下:average:默认值,平均值排名;min:最小值排名;max:最大值排名;first:按第一次出现的顺序排列;dense:密集排序,类似于最小值排序,,但排名每次只增加1,相同排名的数据只只占据一个名词。 numeric_only:对于DataFrame,如果设置值为True,并只对数字列进行排序。 ascending:升序或者降序排列,默认值为True pct:布尔值,是否以百分比形式返回排名,默认值为False """
实例:
对销量相同的产品,按照顺序排名的平均值进行平均排名
#先排序 df=df.sort_values(by="销量",ascending=False) #按照顺序排名的平均值进行平均排名 df["顺序排名"]=df["销量"].rank(ascending=False)
这里两个数销量相同,分别为3和4名,取平均值为3.5
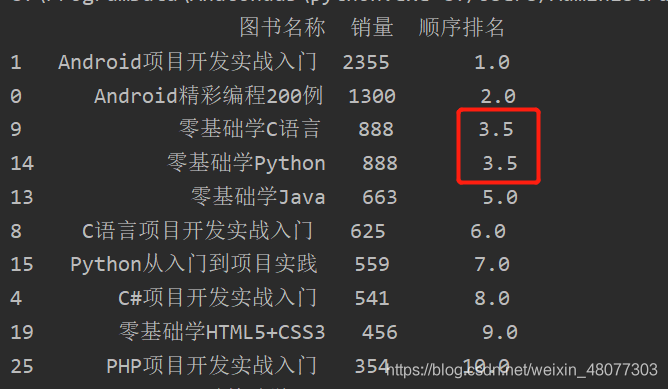
对销量相同的产品,按照在原表中出现的顺序进行排名
#先排序 df=df.sort_values(by="销量",ascending=False) df["顺序排名"]=df["销量"].rank(method="first",ascending=False)
结果如下:很正常的结果
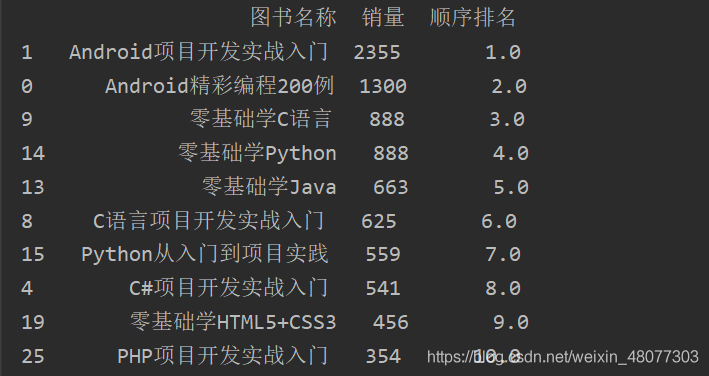
对销量相同的产品,按照顺序排名并取最小值最为排名
#先排序 df=df.sort_values(by="销量",ascending=False) df["顺序排名"]=df["销量"].rank(method="min",ascending=False)
排名如下:相同数量的都按照最小排名填写
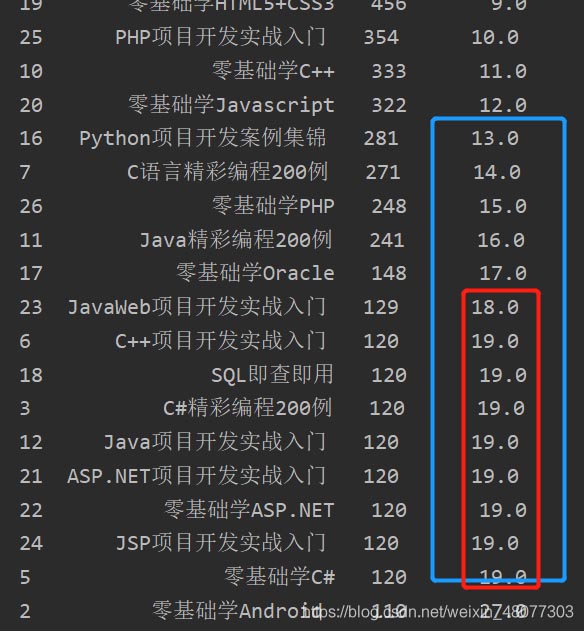
对销量相同的产品,按照顺序排名并取最大值最为排名
#先排序 df=df.sort_values(by="销量",ascending=False) df["顺序排名"]=df["销量"].rank(method="max",ascending=False)
排名如下:相同数量的都按照最大排名填写
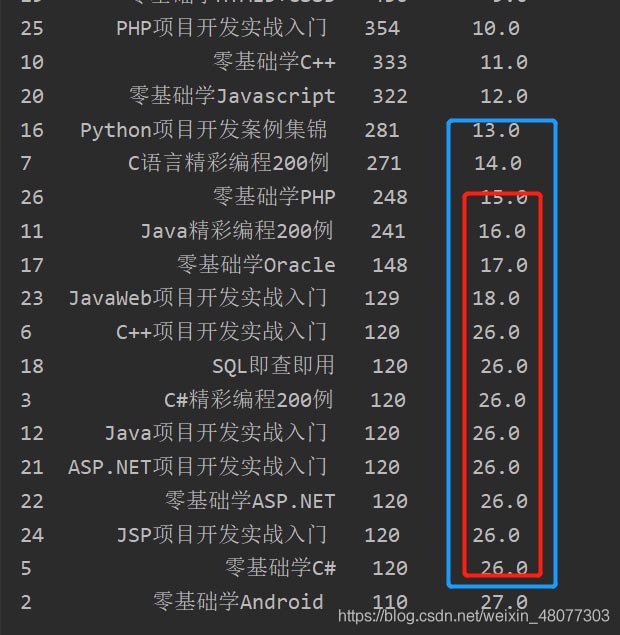
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容